
技术摘要:
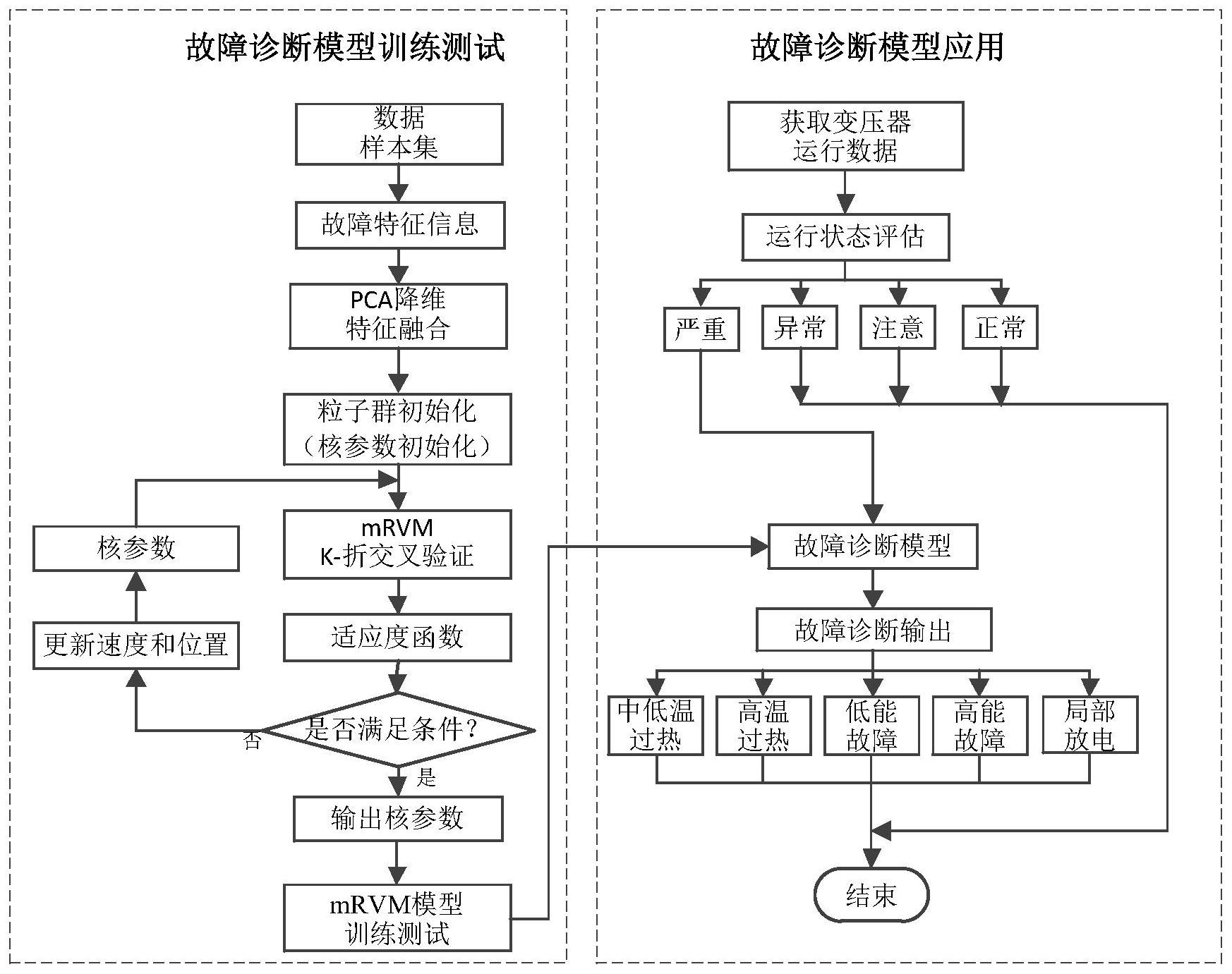
本发明公开了一种计及运行状态等级的变压器故障诊断方法。包括步骤:收集变压器5种典型故障数据,构建故障诊断样本数据集,并进行标签化处理;提取变压器油色谱数据的7种气体含量、19种气体比值共同作为故障特征,将预处理后的26维故障特征利用主元分析法(PCA)进行特征 全部
背景技术:
变压器作为电力系统中的关键枢纽设备之一,不间断地运行于电力系统之中,其 自身的运行状态直接影响着整个电力系统的安全稳定运行。当变压器出现严重的运行状况 而未及时采取有效措施时,则可能引起火灾、爆炸,甚至导致大面积停电事故。因此,当变压 器发生故障时,通过故障诊断技术,准确判断变压器的故障类型,可便于工作人员及时采取 相应的检修措施,减少故障损失,避免事故扩大,具有重要意义。 由于变压器运行可靠性较高,变压器发生故障是小概率事件。相比于变压器正常 运行的数据量而言,故障数据要少得多,这种情况不利于一些基于统计学习的变压器在线 诊断算法。例如,若某台变压器的故障率5%,在线监测的100组数据中,假如存在95组正常 数据,5组故障数据,当一种算法或分类器不考虑输入数据特点,并将所有数据诊断为正常 时,即可得到95%的诊断正确率。显然,这种诊断方式不符合变压器实时在线故障诊断的实 际要求,正常与故障数据的不平衡可能会导致严重的误诊断、漏诊断现象发生。此外,传统 故障诊断方法将变压器直接划分为正常和故障类型,这种分类方法的标准过于粗犷,忽略 了变压器的亚健康状态(一般缺陷),具有较大的模糊性和不确定性。当变压器存在一般缺 陷时,传统诊断方法难以得到有效的诊断结果,给变压器的可靠运行带来安全隐患。
技术实现要素:
本发明提供了一种计及运行状态等级的变压器故障诊断方法,首先利用变压器的 在线监测数据、历史试验数据、历史运行数据等对变压器进行运行状态评估。当运行状态评 估结果是严重时,有必要进行故障诊断;评估结果是非严重的状态时,则不需要进行故障诊 断。该方法通过计及运行状态等级的故障诊断策略,可降低传统变压器实时在线故障诊断 的误诊断风险。 实现本发明目的的技术方案为: 一种计及运行状态等级的变压器故障诊断方法,包括 步骤一:收集多组变压器故障类型数据,对每种故障类型进行标签化处理,构建故 障类型训练集的标签B训练集(L×N),其中,L是故障类型数,N是训练集组数;所述变压器故障类 型为中低温过热T12、高温过热T3、低能放电D1、高能故障D2和局部放电PD; 步骤二:收集对应每一组故障类型数据的变压器油色谱数据构建故障特征训练集 S训练集(N×P),其中,N是训练集组数,P是故障特征维数,每一组故障特征向量S=[s1 ,s2 , s3,···,s26],s1,s2,s3,···,s26为7种气体含量和19种气体含量比值;其中,7种气体含 量为氢气H2、甲烷CH4、乙烷C2H6、乙烯C2H4和乙炔C2H2的含量,CH4、C2H2、C2H4、C2H6的含量之和 即总烃TH,以及CH4、C2H4、C2H2的含量之和D;19种气体含量比值为C2H2/C2H4、CH4/H2、C2H4/ 4 CN 111598150 A 说 明 书 2/9 页 C2H6、C2H2/H2、C2H4/C2H6、C2H2/CH4、C2H4/CH4、C2H4/H2、C2H6/CH4、C2H6/H2、H2/(H2 TH)、CH4/TH、 C2H6/TH、C2H4/TH、C2H2/TH、(CH4 C2H4)/TH、CH4/D、C2H2/D和C2H4/D; 对S训练集(N×P)进行反正切变换,得到X训练集(N×P); 对X训练集(N×P)进行标准化处理,得到X*训练集(N×P); 步骤三:通过主元分析对X*训练集(N×P)进行降维融合,得到Z训练集(N×T),其中,T为降维后 的故障特征维数; 步骤四:构建基于粒子群算法与K-折交叉验证的自适应相关向量机故障诊断模 型,包括 4.1将多分类相关向量机mRVM作为基础的分类器,mRVM的核函数选择径向基RBF核 函数; 4.2粒子群算法随机初始化一组随机粒子种群{Xi|i=1,2,···R},R表示粒子 总个数,令R=10; 随机产生第i个粒子在D维搜索空间下的位置和速度分别表示为X i=(X i 1 , Xi2,···,XiD)T和Vi=(Vi1,Vi2,···,ViD)T;每个粒子的位置对应一个RBF核参数;设置 粒子群的搜索维数D=1; 4 .3将粒子群算法初始化的粒子位置Vi作为mRVM的核参数;将训练集降维后的故 障特征信息Z训练集(N×T)及对应的故障类型训练集的标签B训练集(L×N)作为mRVM的输入量,进行交 叉验证训练;采用K-折交叉验证方式,将用于训练的特征样本集Z训练集(N×T)随机分为K组,每 组数据的样本数接近;按照顺序依次选择K-1组作为交叉验证的训练集,剩下的一组作为交 叉验证的验证集; 4.4在训练过程中,以K-折交叉验证的平均识别率作为粒子群算法的适应度函数, 公式如下: 式中:K是交叉验证折数,n1、n2分别是K-折交叉验证的训练集和验证集的样本个 数,acc1、acc2分别是K-折交叉验证的训练集和验证集识别正确率,ntotal是训练集和验证集 的样本个数之和;设粒子群迭代次数k=1; 4.5粒子群的个体极值和种群的群体极值分别表示为Pi=(Pi1,P Ti2,···,PiD) 、 Pg=(Pg1 ,Pg2 ,···,P )TgD ;找出第i个粒子的个体极值Pid和群体中所有粒子的群体极值 Pgd,具体为:将当前第i个粒子的适应度值与之前该粒子的最大适应度值进行比较,取二者 最大适应度值对应的粒子位置作为当前的个体极值Pid;将当前所有粒子的最大适应度值与 之前整个粒子种群的最优位置的适应度值进行比较,取最大适应度值对应的粒子位置作为 当前的群体极值Pgd; 4.6在迭代寻优过程中,粒子通过下式更新自身个体的位置矢量与速度矢量: 式中: 表示第i个粒子在第k次迭代的速度和位置;w是惯性权重,c1、c2是 5 CN 111598150 A 说 明 书 3/9 页 加速度因子,r1、r2是[0,1]之间的随机数,k是当前迭代次数; 4.7判断粒子群迭代次数k或适应度值是否满足要求;若是,则输出最优粒子的位 置,即为最优核参数;若否,则令k=k 1,返回4.5,直到满足要求为止; 4 .8将最优粒子的位置作为RBF的核参数,将训练集降维后的故障特征信息 Z训练集(N×T)及对应的故障类型训练集的标签B训练集(L×N)作为mRVM的输入量,得到故障诊断模型; 步骤五:当变压器的运行状态等级评估为严重故障时,使用故障诊断模型进行诊 断,具体为:收集变压器油色谱数据的7种气体含量和19种气体含量比值,按照步骤二的方 法构建26维故障特征测试集,并进行反正切和标准化处理;再按照步骤三的方法进行降维 处理;将降维后故障特征测试集输入故障诊断模型,得到分类概率矩阵,以概率矩阵中最大 值对应的故障类别作为变压器故障诊断结果。 本发明的有益效果在于, 1、构建的故障诊断模型在模型训练过程中实现核参数的自动寻优,且相比于多级 二分类器,结构简单。 2、通过计及运行状态等级的故障诊断,可降低传统变压器实时在线故障诊断的误 诊断风险。 附图说明 图1是本发明的方法流程图。 图2是26维故障特征信息的主元贡献率变化曲线。 图3是前7个主元特征根与累计贡献率。 图4是传统故障诊断方法的方法流程图。











