
技术摘要:
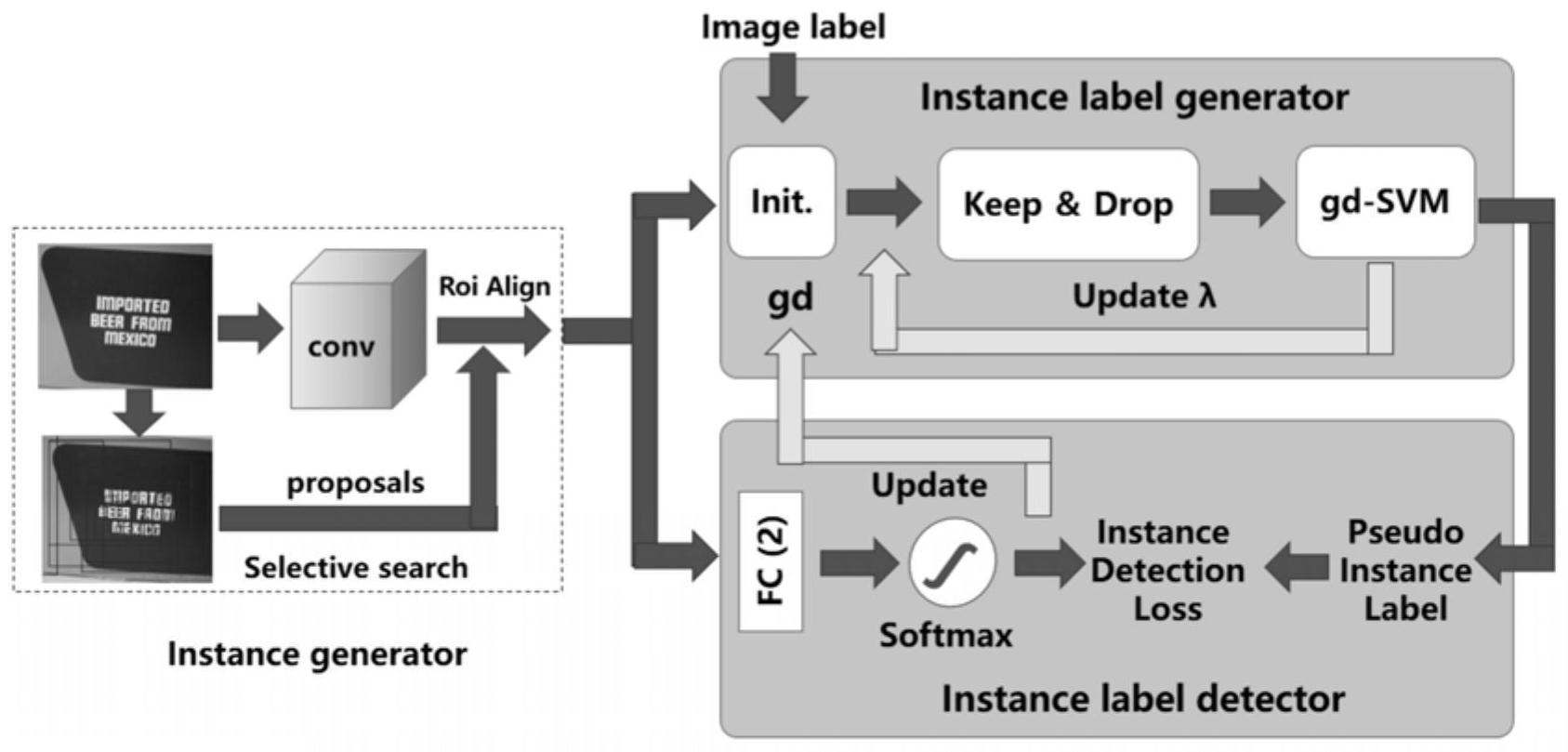
本发明公开了一种基于多示例学习的自然场景文本字符检测标注方法,包括以下步骤:1)得初始化的辅助分类器D0;2)对自然场景图像Bi进行画框处理,得整张图像Bi中的所有提案框bi,j,将图片bi通过基础网络框架进行特征提取,得多示例学习中的具体示例si,j;3)在标签生成器 全部
背景技术:
文本图像在生活中随处可见,它是伴随着人类信息文明发展的一个重要标志。在 人们日常生活中,存在着大量的文本图像,例如:交通指示牌、商品铭牌、车牌和驾驶证等。 随着互联网和各类移动电子设备(手机、相机等)的快速发展,人们通过这些设备能浏览到 大量包含文本信息的自然场景图像,准确检测和识别这些图像所包含的文本信息具有很重 要的研究意义。 随着计算机视觉与模式识别等领域的飞速崛起,目标检测和识别作为其中的重要 领域也在不断的成长和发展中,相比较于其他自然场景中的检测和识别,文本检测和识别 具有其独特的重要性,它能直观的反映出自然场景图像中的具体内容,对于分析和理解图 像具有重要意义。在这个数据为王的深度学习时代,更大规模更高质量的标注数据往往可 以得到更好的识别模型,但与此同时也意味着高昂的标注成本,同时,标注过程会受到标注 人员的主观意识影响导致标注质量参差不齐,最终影响识别模型的性能。具体到文本检测 和识别领域,在收集训练数据的过程中,根据不同检测对象,标注内容不仅要求标注对象类 别,同时要求标注对象位置,这进一步增加了标注难度,制约了研究进展。因此,如何实现自 动的且高质量的自然场景图像文本区域检测定位得到了广泛的关注。 图像中的文本通常被视为若干视觉元素的层次结构,文本的组成可以分为字符、 单词、文本行和文本块,目前基于完全监督的深度学习研究自然场景下的文本检测多是使 用单词或者文本级别进行位置坐标的真值标注,每一张自然场景图像中含有大量文本内 容,文本排列方向并不一致,且分布不均匀,而用于文本识别模块大多是使用字符级别注释 的标签信息进行标注,每一个单词级别的文本需要拆分成一个个单独的字符,字符之间的 间隔相对单词更为紧密,难以手工标注,这样的数据集处理起来耗时且准备成本高,标注人 员稍有松懈将导致整体标签质量较低。除此之外,国内外研究字符级别检测的算法相对于 单词级别而言较为欠缺,研究人员尝试采用半监督和弱监督的学习方式对字符级别的文本 进行检测,弱监督和半监督的学习方式都是针对数据的标签信息而言的,一般而言,一个训 练数据样本由两部分组成:描述对象或事件的特征向量和对应的真值数据标签,完全监督 学习中特征向量和真值具有一一对应的关系,而弱监督学习中与特征向量对应的真值并不 具有完整信息,简单来说,弱监督学习中的标签蕴含的信息量较低,通过弱监督学习,可以 将输入数据映射到一组更强的标签,获得完整标签信息。弱监督学习一般包括不完全监督、 不确切监督和不准确监督。现有研究人员为了获得字符级别的检测器,采用少量单词级别 的标注信息作为基础检测器进行检测,然后使用SSD(Single shot multibox detector)针 对字符检测进行训练,虽然能检测标注出特定数据集ICDAR2013上字符的具体位置,但从本 质上而言,并没有摆脱需要初始标注信息的前提,并且使用少量的单词级别标注训练的单 3 CN 111582329 A 说 明 书 2/6 页 词检测器并不具有鲁棒性,通过单词级别的标注信息获得字符级别标注信息,这种不确切 监督在更为复杂的自然场景图像中对字符级别的检测效果并不理想。 不确切监督是训练样本数据集只有粗粒度标签信息,通过粗粒度信息获得更强的 标签信息是其主要任务,解决不确切监督的主要方法是多示例学习,在多示例学习中,训练 集由一组具有分类标签的多示例包(bag)组成,每个包含有若干个没有分类标签的示例 (instance)。如果多示例包至少含有一个正示例,则该包被标记为正类多示例包(正包)。如 果多示例包的所有示例都是负示例,则该包被标记为负类多示例包(负包)。多示例学习的 目的是,通过对具有分类标签的多示例包的学习,建立多示例分类器,并将该分类器应用于 未知多示例包的预测和每一个包中具体示例的标签预测。 在上述背景以及调研了国内外研究现状后,现有技术中文本字符人工标注的成本 高,标注质量差的缺点,因此急需开发一种新的标注方法,以解决上述问题。
技术实现要素:
本发明的目的在于克服上述现有技术的缺点,提供了一种基于多示例学习的自然 场景文本字符检测标注方法,该方法能够实现自然场景的文本字符检测标注,且标注成本 低,标注质量高。 为达到上述目的,本发明所述的基于多示例学习的自然场景文本字符检测标注方 法包括以下步骤: 1)使用基本二分类网络将文本字符示例及不含有文本字符的背景示例进行训练 分类,得初始化的辅助分类器D0; 2)对自然场景图像Bi进行画框处理,得整张图像Bi中的所有提案框bi,j,其中,Bi∈ B表示第i个包,i=1,…,k,B表示所有k个包,即所有训练图像,bi ,j∈Bi,j=1,…,n,n表示 提案框的个数,将图片bi通过基础网络框架进行特征提取,得所有提案框bi,j的特征图fi,j, 并将所有提案框bi,j的特征图fi,j作为多示例学习中的具体示例xi,j; 3)将步骤2)得到的多示例学习中的具体示例xi ,j送入到示例标签生成器中,并在 标签生成器中进行内部迭代循环,同时使用步骤1)中的辅助分类器D_0联合并指导标签生 成器中的SVM进行迭代训练,得所有正值示例标签yi,j; 4)将步骤3)中的多示例学习中的具体示例xi ,j与与其对应的示例标签yi ,j重新作 为新的训练样本输入到辅助分类器D_0中进行外部循环迭代,以优化更新辅助分类器的模 型参数,得辅助分类器D_i,然后转至步骤2),待完成外部循环训练后,得最终的辅助分类器 D_n,再利用最终的辅助分类器D_n对待处理的自然场景图像进行分类,得自然场景图像的示 例标签信息,完成自然场景额文本字符检测标注。 步骤1)中采用selective search算法或者Edge boxes算法对自然场景图像Bi进 行画框处理。 步骤4)中使用keep and drop算法进行训练。 本发明具有以下有益效果: 本发明所述的基于多示例学习的自然场景文本字符检测标注方法在具体操作时, 使用少量的文本字符示例及不含有文本字符的背景示例进行训练分类,得到初始化的辅助 分类器,然后利用弱监督学习中的多示例学习并结合深度学习,进行循环训练迭代,实现以 4 CN 111582329 A 说 明 书 3/6 页 弱信息含量的标签映射出强信息含量的标签功能,以降低文本字符人工标注的成本,解决 由于人工标注无法保证标注质量的问题,为文本字符区域自动检测标注提供新的研究思 路。 附图说明 图1为本发明的流程示意图; 图2为辅助分类器的基础网络结构图; 图3为示例标签生成器的结构图。











