
技术摘要:
本发明公开了一种多领域实体识别方法。本专利中,我们主要做出了如下2个创新:1、针对目标领域无任何人工标注数据的跨领域场景,快速自动构建目标领域的弱标注数据。2、将局部标注学习应用到跨领域命名实体识别任务中。有益效果:在目标领域没有任何人工标注数据的场景 全部
背景技术:
命名实体识别指识别文本中具有特定意义的实体。近年来,神经网络方法大大提 高了命名实体识别任务的性能。但是,在实际应用场景中,当文本所属领域不同于训练语料 时,深度神经网络模型往往展现出较弱的知识泛化能力。 跨领域命名实体识别的难点主要有:1)实体名多样,目标领域会出现大量源领域 中没有出现过的实体;2)语言表达差异大,不同于新闻领域规范的语言表达,各领域语料的 数据分布迥异,如社交文本口语化现象严重,医疗领域的文本则带有大量专业术语。 目前的跨领域命名实体识别方法大致可以分为:1)基于多任务学习框架的方法, 学习领域无关的特征;2)使用源领域训练得到的模型参数初始化目标领域模型,再在目标 领域数据上进行训练。 基于多任务学习的跨领域命名实体识别 模型主要分为三部分:1)字向量表示层:将输入字/词转化为连续的向量表示;2) 特征抽取层:通过双向长短期记忆网络和线性变换,得到每个字对应各标签的概率;3)预测 层:预测当前输入条件下的输出序列是什么。 为了抽取领域无关、任务相关的特征,该方法共享源领域模型和目标领域模型的 字向量表示层和特征抽取层。由于不同领域输出的标签可能不同,所以不共享CRF层。然后, 使用源领域的人工标注数据和目标领域的人工标注数据分别训练该模型。实验证明,该方 法通过2个领域共享若干层进行联合训练,能够有效抽取与领域无关的特征,从而提高目标 领域的实体识别性能。 2、基于参数初始化的跨领域命名实体识别 该方法共分为以下几个步骤: 1、在具有大规模人工标注数据的源领域上训练,得到模型A。 2、模型B具有同样的模型结构,使用模型A的参数初始化模型B。 3、在目标领域有限的人工标注数据上,继续训练模型B,拟合目标领域特征。 实验证明,该方法能有效提高目标领域的实体识别性能,经过微调的模型B对目标 领域的实体识别性能显著优于模型A。 传统技术存在以下技术问题: 1、需要目标领域的人工标注语料。实际应用中,大规模高质量的标注语料获取代 价高昂。并且,细分领域非常多,每有一个新的特定领域就需要标注一定量的语料,成本非 常高。当目标领域没有标注数据时,大多数现有的领域迁移技术都无法得到有效应用。 2、缺乏对目标领域无标注数据的利用。大规模无标注数据的获取代价很低,其中 蕴含着丰富的语义信息。但是,大多数现有的领域迁移技术并没有利用它。 4 CN 111611802 A 说 明 书 2/6 页
技术实现要素:
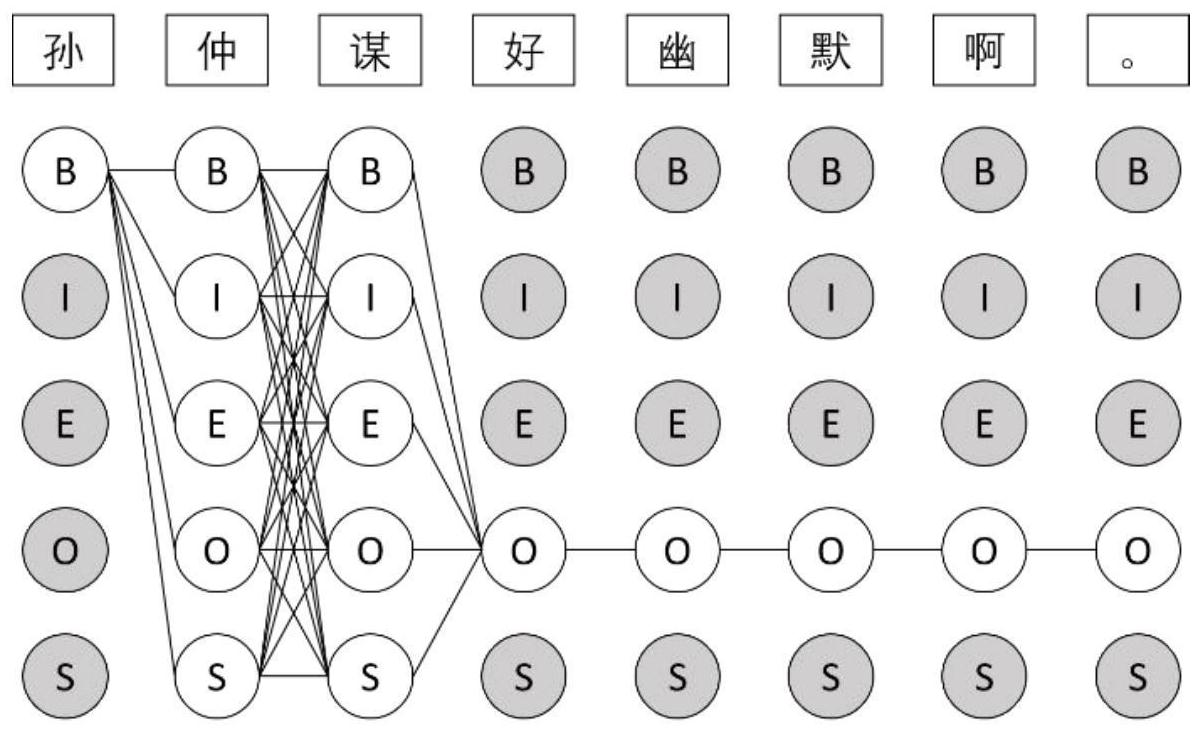
本发明要解决的技术问题是提供一种多领域实体识别方法,在目标领域没有任何 人工标注数据的场景下,自动生成高质量的目标领域弱标注数据,并对其建模,提高了目标 领域的命名实体识别性能。 为了解决上述技术问题,本发明提供了一种多领域实体识别方法,包括:为了减少 数据分布不同带来的迁移困难,使用了两种方法同时标注目标领域的无标注语料,保留高 置信度的标签,对于不确定位置采用特殊标签,得到目标领域的弱标注数据;由于弱标注语 料包含不确定标签,普通CRF层无法建模,应用局部标注学习对其建模; 自动标注: 利用外部实体词典,根据正向最大匹配机制,在文本中寻找可能出现的实体;将匹 配成功的部分标记为实体,匹配失败的部分标记为“O”; 在源领域数据上训练得到一个模型,直接用该模型标注目标领域的无标注文本, 作为第二种自动标注方法的结果; 对比上述两个方法的标注结果,保留两种方法达成一致的标签;把产生冲突的位 置标为“U”,意为“Unknown”,即这个字的标签不确定,可以为任何可能的标签;所得结果就 是最终的目标领域弱标注语料; 基于局部标注的命名实体识别: 模型将识别任务当作序列标注任务来处理,模型输入是汉字序列,模型输出是标 签序列; 在模型中,对于输入的汉字序列,首先通过双向长短期记忆网络(LSTM)构造神经 元特征,然后组合这些特征输入到局部CRF层进行标签预测;整个模型分为3个主要部分:1) 字向量表示层:通过字向量映射表,将输入字串表示为连续的向量;2)特征抽取层:通过双 向长短期记忆网络和线性变换,得到每个字对应各标签的概率;3)预测层:采用局部CRF,预 测当前输入条件下的输出序列是什么; 上述模型分为两个状态,训练和预测;在训练过程中,系统会根据输入的训练语句 计算相应的标签序列,这个标签序列一开始和正确的标签序列肯定是相差比较大的,也就 是说一开始模型的性能很差;然后模型会用自己预测得到的结果和正确答案计算得到一个 差值,并反向更新系统参数,更新的目标就是尽可能最小化这个差值Ioss;随着训练的进 行,这个模型对于序列的标签预测能力会越来越好,直到达到一个性能的最高点。 在其中一个实施例中,“模型将识别任务当作序列标注任务来处理,模型输入是汉 字序列,模型输出是标签序列;”中,标签采用BIOES形式,其中,B-XX表示XX类别实体的第一 个汉字,E-XX表示XX类别实体的最后一个汉字,I-XX表示类别XX实体的中间部分,S-XX表示 单个字的类别XX实体,其它汉字标注为“0”。 在其中一个实施例中,字向量表示层:将离散的输入汉字转换成连续的向量表示; 使用一张映射表,表内存储着每个汉字对应的向量表示;向量的初始值可以使用随机数初 始化,也可以设置为预训练的字向量;在模型训练过程中,向量表内容作为模型的参数,在 迭代过程中随同其它参数一起优化;给定句子C=











