
技术摘要:
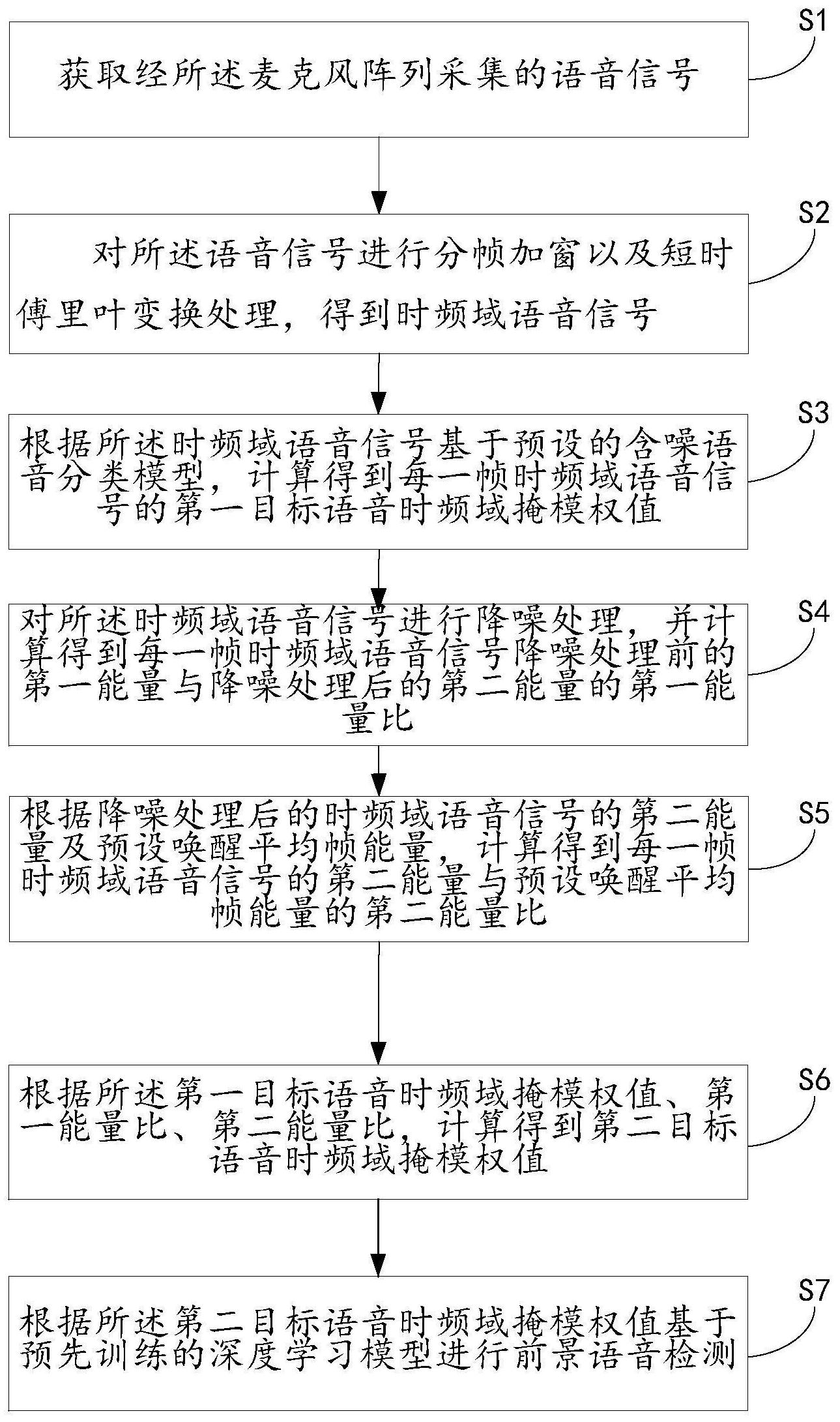
本发明公开了一种基于麦克风阵列的前景语音检测方法及装置,包括:获取经麦克风阵列采集的语音信号;对语音信号进行处理,得到时频域语音信号;基于预设的含噪语音分类模型,得到每一帧时频域语音信号的第一目标语音时频域掩模权值;降噪处理,得到每一帧时频域语音信 全部
背景技术:
对麦克风阵列采集的语音信号中有噪声及目标语音信号,噪声的存在会干扰到目 标语音信号唤醒语音设备,比如音箱,现有技术中对语音的检测对目标语音的识别性低,检 测不准确,计算量大且复杂度高,不能实现对目标前景语音的检测。
技术实现要素:
本发明旨在至少一定程度上解决上述技术中的技术问题之一。为此,本发明的第 一个目的在于提出一种基于麦克风阵列的前景语音检测方法,大幅度提高了复杂噪声环境 下语音检测的准确性,降低计算量及复杂度,对目标前景语音的检测效果良好。 本发明的第二个目的在于提出一种基于麦克风阵列的前景语音检测装置。 为达到上述目的,本发明第一方面实施例提出了一种基于麦克风阵列的前景语音 检测方法,包括: 获取经所述麦克风阵列采集的语音信号; 对所述语音信号进行分帧加窗以及短时傅里叶变换处理,得到时频域语音信号; 根据所述时频域语音信号基于预设的含噪语音分类模型,计算得到每一帧时频域 语音信号的第一目标语音时频域掩模权值; 对所述时频域语音信号进行降噪处理,并计算得到每一帧时频域语音信号降噪处 理前的第一能量与降噪处理后的第二能量的第一能量比; 根据降噪处理后的时频域语音信号的第二能量及预设唤醒平均帧能量,计算得到 每一帧时频域语音信号的第二能量与预设唤醒平均帧能量的第二能量比; 根据所述第一目标语音时频域掩模权值、第一能量比、第二能量比,计算得到第二 目标语音时频域掩模权值; 根据所述第二目标语音时频域掩模权值基于预先训练的深度学习模型进行前景 语音检测。 根据本发明第一方面实施例提出的一种基于麦克风阵列的前景语音检测方法,利 用麦克风阵列的空域选择特性结合第一目标语音时频域掩模权值与降噪处理前后时频点 的能量差异信息及降噪处理后时频域语音信号与预设唤醒平均帧能量,得出了在复杂噪声 场景下,鲁棒性更高的第二目标语音时频域掩模权值,大幅度提高了复杂噪声环境下语音 检测的准确性,实现了鲁棒性更高的语音检测,降低噪声对语音检测的影响,只对目标语音 进行检测,提高了检测效率。 根据本发明的一些实施例,在获取经所述麦克风阵列采集的语音信号之前,还包 括: 4 CN 111613247 A 说 明 书 2/6 页 获取目标人声唤醒语音设备的相关信息; 根据所述相关信息,计算得到预设含噪语音分类模型及预设唤醒平均帧能量。 根据本发明的一些实施例,所述相关信息包括:噪声信息、目标语音信息。 根据本发明的一些实施例,所述深度学习模型包括GMM模型。 根据本发明的一些实施例,所述根据所述第一目标语音时频域掩模权值、第一能 量比、第二能量比,计算得到第二目标语音时频域掩模权值,算法包括: 计算第一能量比: 其中,ni为降噪处理前每一帧时频域语音信号的第一能量;mi为降噪处理后每一帧 时频域语音信号的第二能量;i为总分帧数,i为正整数; 计算第二能量比: 其中,q为预设唤醒平均帧能量; 计算第二目标语音时频域掩模权值: M=ai×bi×ci 其中,ai为第i帧的第一目标语音时频域掩模权值。 为达到上述目的,本发明第二方面实施例提出了一种基于麦克风阵列的前景语音 检测装置,包括: 第一获取模块,用于获取经所述麦克风阵列采集的语音信号; 语音信号处理模块,用于对所述语音信号进行分帧加窗以及短时傅里叶变换处 理,得到时频域语音信号; 第一计算模块用于: 根据所述时频域语音信号基于预设的含噪语音分类模型,计算得到每一帧时频域 语音信号的第一目标语音时频域掩模权值; 对所述时频域语音信号进行降噪处理,并计算得到每一帧时频域语音信号降噪处 理前的第一能量与降噪处理后的第二能量的第一能量比; 根据降噪处理后的时频域语音信号的第二能量及预设唤醒平均帧能量,计算得到 每一帧时频域语音信号的第二能量与预设唤醒平均帧能量的第二能量比; 根据所述第一目标语音时频域掩模权值、第一能量比、第二能量比,计算得到第二 目标语音时频域掩模权值; 检测模块,用于根据所述第二目标语音时频域掩模权值基于预先训练的深度学习 模型进行前景语音检测。 根据本发明第二方面实施例提出的一种基于麦克风阵列的前景语音检测装置,利 用麦克风阵列的空域选择特性结合第一目标语音时频域掩模权值与降噪处理前后时频点 的能量差异信息及降噪处理后时频域语音信号与预设唤醒平均帧能量,得出了在复杂噪声 场景下,鲁棒性更高的第二目标语音时频域掩模权值,大幅度提高了复杂噪声环境下语音 检测的准确性,实现了鲁棒性更高的语音检测,降低噪声对语音检测的影响,只对目标语音 5 CN 111613247 A 说 明 书 3/6 页 进行检测,提高了检测效率。 根据本发明的一些实施例,基于麦克风阵列的前景语音检测装置还包括: 第二获取模块,用于获取目标人声唤醒语音设备的相关信息; 第二计算模块,用于根据所述相关信息,计算得到预设含噪语音分类模型及预设 唤醒平均帧能量。 本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变 得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明 书以及附图中所特别指出的结构来实现和获得。 下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。 附图说明 附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实 施例一起用于解释本发明,并不构成对本发明的限制。在附图中: 图1是根据本发明一个实施例的一种基于麦克风阵列的前景语音检测方法的流程 图; 图2是根据本发明又一个实施例的一种基于麦克风阵列的前景语音检测方法的流 程图; 图3是根据本发明一个实施例的一种基于麦克风阵列的前景语音检测装置; 图4是根据本发明又一个实施例的一种基于麦克风阵列的前景语音检测装置。 附图标记: 第一获取模块1、语音信号处理模块2、第一计算模块3、检测模块4、第二获取模块 5、第二计算模块6。











