
技术摘要:
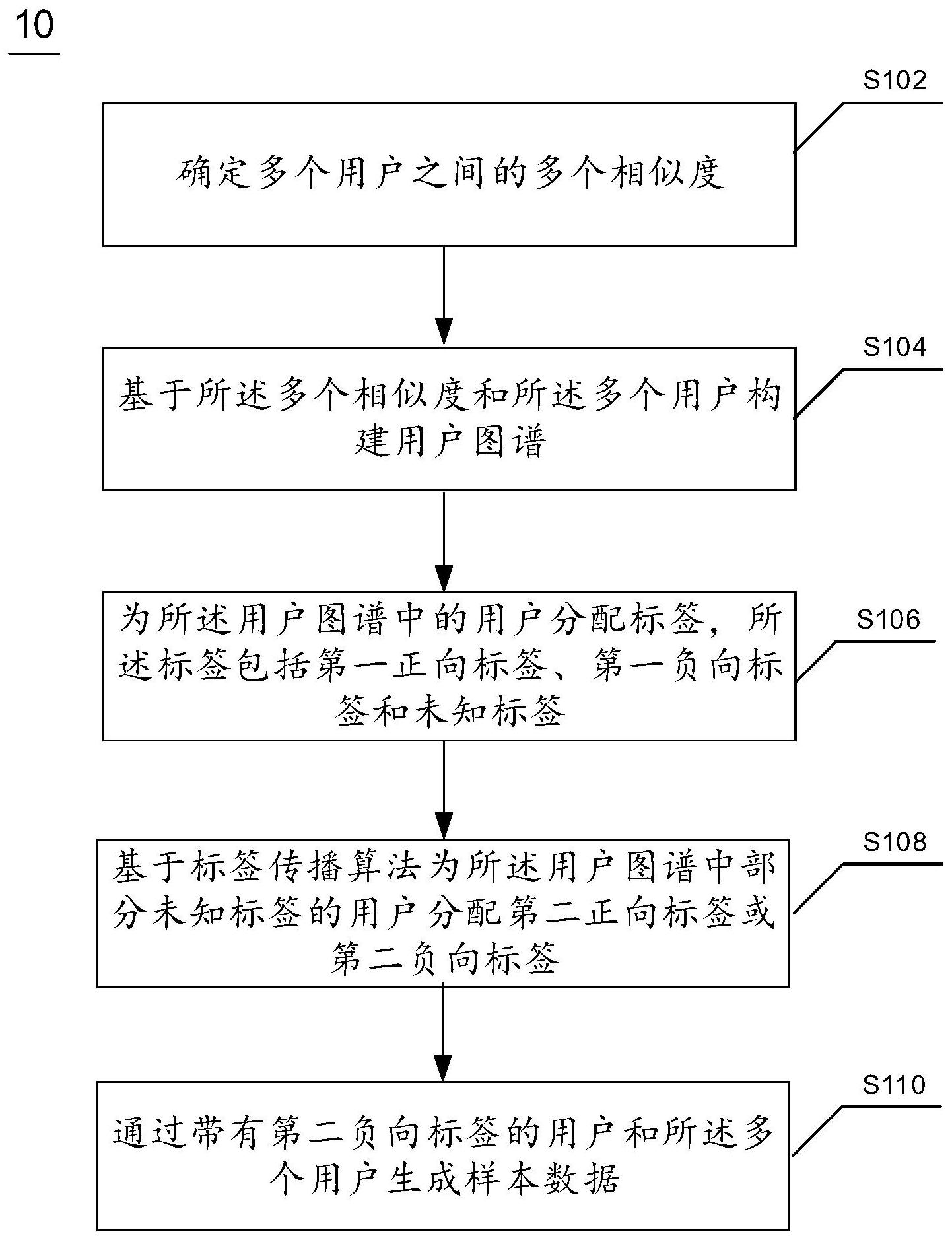
本公开涉及一种样本数据生成方法、装置、电子设备及计算机可读介质。该方法包括:确定多个用户之间的多个相似度;基于所述多个相似度和所述多个用户构建用户图谱;为所述用户图谱中的用户分配标签,所述标签包括第一正向标签、第一负向标签和未知标签;以及基于标签传 全部
背景技术:
不均衡的样本,即数据集中存在某一类样本,其数量远多于或远少于其他类样本, 从而导致一些机器学习模型失效的问题。例如逻辑回归即不适合处理类别不平衡问题,例 如逻辑回归在欺诈检测问题中,因为绝大多数样本都为正常样本,欺诈样本很少,逻辑回归 算法会倾向于把大多数样本判定为正常样本,这样能达到很高的准确率,但是达不到很高 的召回率。通常情况下机器学习模型需要对正样本(好样本)和负样本(坏样本)进行学习, 正样本是正确分类出的类别所对应的样本,负样本原则上可以选取任何不是正确类别的其 他样本。但是对于金融领域或者其他领域而言,正样本的选取是较容易的,负样本的数量是 极少的,这种情况下产生的样本是不均衡的样本。 目前对于不均衡样本处理,主流方法还是从抽样的角度去处理,比如进行欠采样 或者过采样来提升坏样本的比例,但是对于抽样方法,会造成过拟合现象;而且采样改变了 样本的真实分布,使得学习的模型是有偏的,这种不均衡的样本会给机器学习模型训练引 入很多误差数据,最终可能导致训练出来的模型效果不够理想。 因此,需要一种新的样本数据生成方法、装置、电子设备及计算机可读介质。 在所述
技术实现要素:
部分公开的上述信息仅用于加强对本公开的背景的理解,因此它 可以包括不构成对本领域普通技术人员已知的现有技术的信息。











