
技术摘要:
本发明公开了一种基于模糊c均值聚类算法的故障区段定位方法及装置,其中方法包括:获取分布于全网的n个节点的故障特征向量,构建待测样本集;将待测样本集中每个待测样本进行标准化预处理;基于模糊c均值聚类算法将n个预处理后的待测样本划分为故障类和非故障类,并计 全部
背景技术:
传统保护方法的核心思想是将从测量点实时信息中提取的故障特征量与预设的 保护整定值或整定曲线进行比较,一旦测量特征量的大小超出整定值所限定的范围,则判 定故障发生,保护装置动作。然而,这些基于保护整定值的方法在实际应用中所取得的效果 并不十分理想。主要受到以下几个方面的制约:小电流接地故障时,系统阻抗大,因此发生 单相接地故障时,故障电流小,作为保护判据的特征量微弱,检测存在很大难度;配电网运 行方式复杂多变,对于不同运行工况,预设的保护整定值难以自适应性调整;不同故障条件 下表现出来的故障特性各不相同,故障特征量的变化范围大,难以准确检测;在现场环境 中,故障信号还存在受电磁干扰,系统不平衡电流影响,负荷电流淹没等问题,信噪比不高; 分布式电源DG(Distributed generation)在配电网中的渗透率逐步提高的大背景下,传统 单向潮流的被动配电网正逐步演变为具有双向潮流的主动配电网,故障特征量的变化范围 进一步增大。 随着配电网故障区段定位研究的发展,基于智能算法的故障区段定位方法成为了 新的研究热点。对于具有自学能力的智能算法,可以在不预知研究对象的数学模型的情况 下,通过在线训练大量故障样本,实现对馈线运行状态的描述与判断,并提高故障区段定位 精度。人工神经网络算法的优点在于数据训练过程便于操作,适用范围广,已有许多学者在 这方面开展研究。相关文献提出借助人工神经网络模型实现故障定位的方案,首先采用小 波包对提取的暂态过程信号进行处理,然后利用人工神经网络对故障信息进行离线训练, 从而得到故障定位结果。相关文献对BP神经网络的结构进行特殊化处理,在原有网络结构 的基础上有机融入小波变换层与模糊处理层结构,提升了故障识别准确性。相关文献深入 分析非故障相的暂态电流,提出了一种单相接地故障定位新方法,该方法基于故障线路的 非故障相电流暂态量来实现故障定位,首先利用小波变换处理暂态故障信息,然后配合人 工神经网络进行分析,可以有效降低系统运行方式发生改变及故障条件变化等因素对故障 定位造成的影响。根据上述分析可以看出,基于这些新的数学方法,国内外广大专家和学者 对小电流接地系统故障区段定位进行了深入研究,并不断有突破性的新思路引入小电流接 地系统故障区段定位领域,如把小波分析、Prony、遗传算法、专家系统、人工神经网络、模糊 理论等引入到小电流系统故障区段定位领域中。 智能算法的引入,虽然在一定程度上提升了故障区段定位的准确性和可靠性,但 迄今为止,小电流接地系统的故障区段定位难题并没有得到妥善解决。发明人发现,对于具 体的工程实践问题,即使有先进的智能数学方法作为支撑,我们也不应忽视对配电网接地 故障机理及原理的研究,而如何能够从接地故障自身的故障特征出发,研究适应于不同运 行方式下各种故障条件的故障区段定位新方法显得尤为重要。 5 CN 111596167 A 说 明 书 2/10 页
技术实现要素:
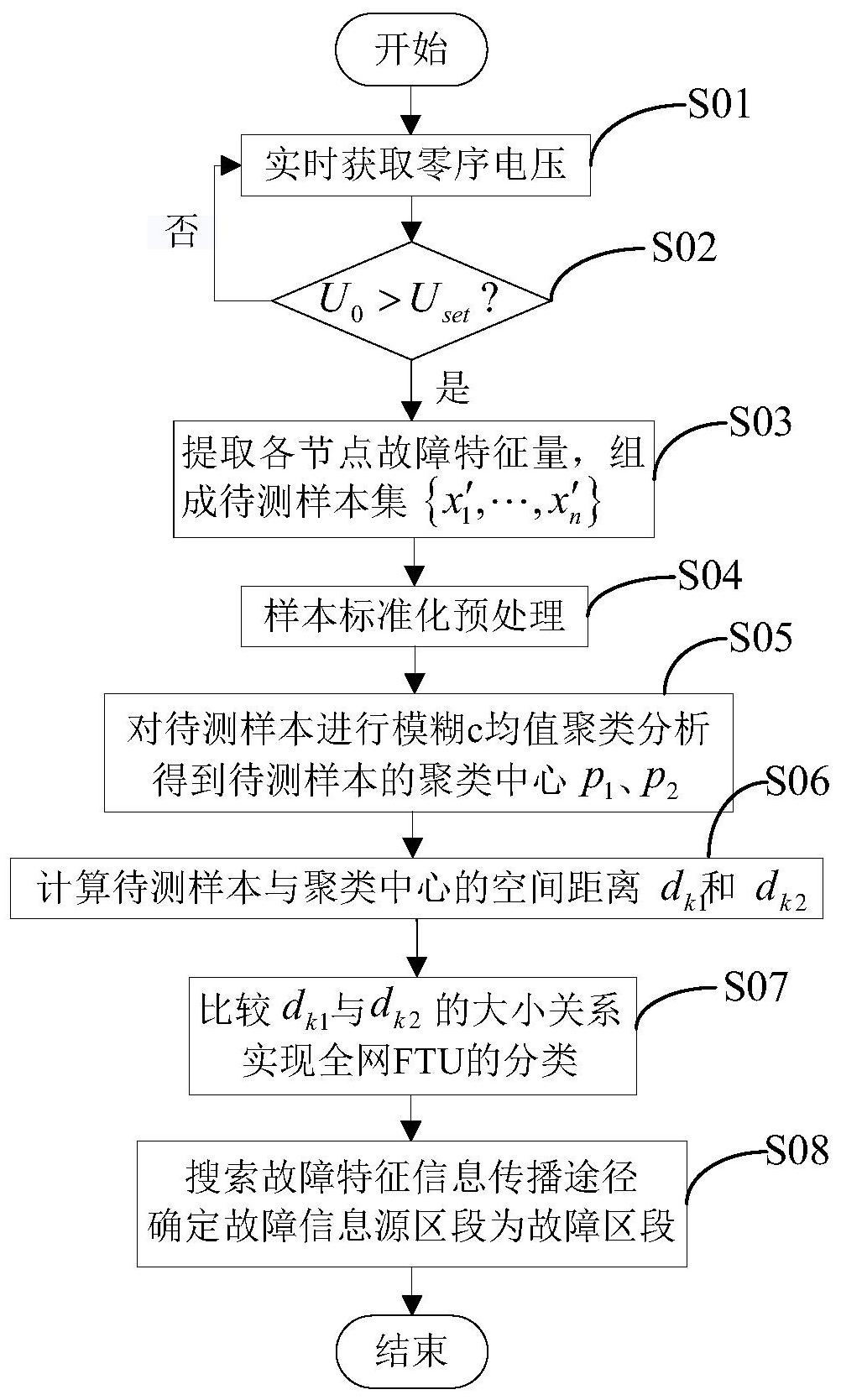
本发明提供了一种基于模糊c均值聚类算法的故障区段定位方法、装置,以解决现 有技术中没有深度发掘配电网接地故障特性导致准确性、可靠性低的问题。 第一方面,提供了一种基于模糊c均值聚类算法的故障区段定位方法,包括: 获取分布于全网的n个节点的多个故障特征量,每个节点的多个故障特征量构成 一个故障特征向量,将故障特征向量作为待测样本构建待测样本集; 将待测样本集中每个待测样本进行标准化预处理; 构建高维故障特征空间,基于预处理后的每个待测样本的多个故障特征量将n个 待测样本投射至该高维故障特征空间中,基于模糊c均值聚类算法将n个预处理后的待测样 本划分为故障类和非故障类,并计算得到故障类和非故障类的聚类中心; 分别计算预处理后的每个待测样本与故障类和非故障类的聚类中心之间的距离 dk1和dk2,根据dk1和dk2的大小关系将预处理后的每个待测样本对应的节点划分到故障类或 非故障类; 基于每个节点所属的故障类别搜索故障特征信息传播途径,确定故障信息源位 置,实现故障区段定位。 进一步地,所述将待测样本集中每个待测样本进行标准化预处理包括: 将待测样本按如下公式进行标准化预处理: 其中,xk′j为第k个待测样本的第j个故障特征量值, 为第j个故障特征量的均 值,S(xj′)为第j个故障特征量的标准差,xkj为标准化预处理后第k个待测样本的第j个故障 特征量值,s为每个节点获取的故障特征量总个数。 进一步地,所述基于模糊c均值聚类算法将n个预处理后的待测样本划分为故障类 和非故障类,并计算得到故障类和非故障类的聚类中心,包括: 通过以下优化目标函数(4),借由平衡迭代方程(5)和(6)对所有预处理后的待测 样本进行动态聚类,并得到故障类和非故障类的聚类中心: 6 CN 111596167 A 说 明 书 3/10 页 其中,c为聚类类别数量,取c=2;μik∈[0,1]表示预处理后的第k个待测样本xk从 属于第i种聚类类型的隶属度,满足 pi为聚类中心,i取1或2,p1为故障类中心,p2 为非故障类中心;||·||为表征预处理后的待测样本与聚类中心之间空间距离的矩阵范 数;m为加权指数,取m=2;U为所有预处理后的待测样本隶属度所构成的隶属矩阵,P为所有 聚类中心pi构成的聚类中心矩阵,Jm(U,P)为聚类损失函数,Mfc为预处理后的待测样本的模 糊c划分空间, Rs为迭代过程中产生的所有隶 属矩阵;优化目标函数(4)的迭代过程终止条件为: w为当前迭代次 数,ε为预先设定的迭代停止阈值,ε取1.0e-6。 进一步地,所述分别计算预处理后的每个待测样本与故障类和非故障类的聚类中 心之间的距离dk1和dk2,根据dk1和dk2的大小关系将预处理后的每个待测样本对应的节点划 分到故障类或非故障类,包括: 通过公式(7)来计算每个预处理后的待测样本与故障类和非故障类的聚类中心之 间的欧式距离: 其中,dk1表示预处理后的待测样本与故障类中心的距离,dk2表示预处理后的待测 样本与非故障类中心的距离,xkj为标准化预处理后第k个待测样本的第j个故障特征量值, pij表示故障类或非故障类的第j个故障特征量的聚类中心,s为每个节点获取的故障特征量 总个数; 如果dk1>dk2,则该预处理后的待测样本对应的节点属于非故障类; 如果dk1











