
技术摘要:
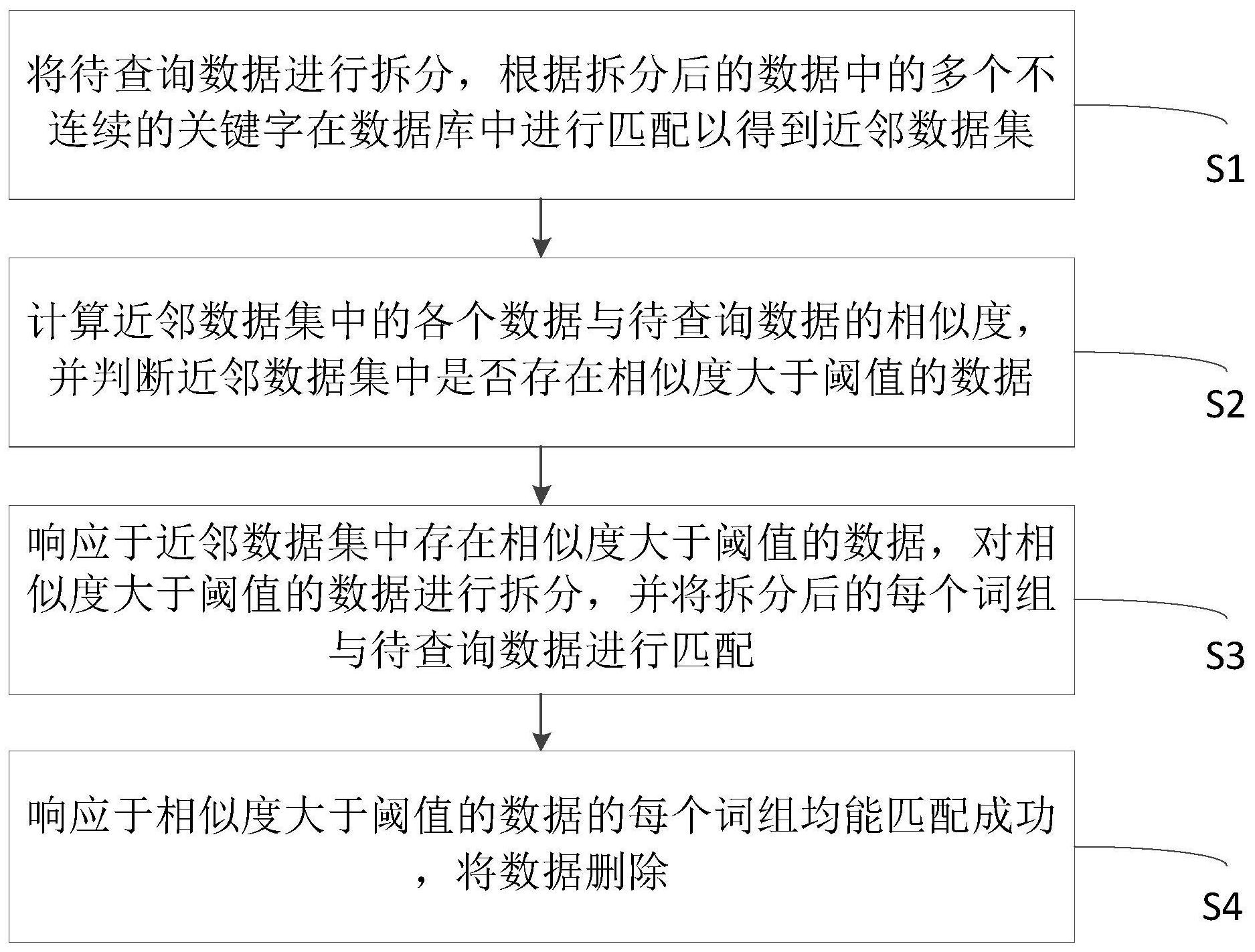
本发明公开了一种清洗重复数据的方法、系统、设备和存储介质,方法包括:将待查询数据进行拆分,根据拆分后的数据中的多个不连续的关键字在数据库中进行匹配以得到近邻数据集;计算近邻数据集中的各个数据与待查询数据的相似度,并判断近邻数据集中是否存在相似度大于 全部
背景技术:
近几年,随着硬件设施与软件技术不断的推陈出新,以及数据分析在国家和企业 发展中起到的作用越来越大,国家政府和企业越来越重视数据的分析与处理。但是在技术 发展的同时,大量的数据分别存储在不同的部门或子公司内,形成了信息壁垒,因此对数据 的统一管理成为一个急切需要解决的问题。尤其是在大型企业使用ERP产品中,集团与子公 司存在一套甚至多套信息系统,如何打通这些信息壁垒成为企业数据化的重要一步。 借助GSP框架研发的主数据产品,成为打破数据壁垒的关键一环,借助GSP框架,主 数据可以快速根据实际场景定义出一套适配企业要求的数据管理系统。但是,数据清洗仍 然是主数据中关键的一环,各个业务系统的数据要形成主数据,必须经过数据清洗,去除脏 数据和重复数据。例如:在不同的业务系统中,“中国国家铁路集团有限公司”这条数据,可 能会被叫做“中国铁路集团”、“中铁集团”等多种叫法,由于各个信息系统是独立运行维护 的,其主键也很难保持一致。因此,在获取业务系统数据形成主数据前,通过数据清洗,去除 相似或重复数据尤为必要。
技术实现要素:
有鉴于此,本发明实施例的目的在于提出一种清洗重复数据的方法、系统、计算机 设备及计算机可读存储介质,通过关键属性判断待查询数据的近邻,在近邻中进行相似度 校验,既能提升效率,又能快速精准定位相似或重复数据,在不增加用户操作难度的基础 上,提升了数据清洗的效率,更便捷的查询出相似或重复数据。 基于上述目的,本发明实施例的一方面提供了一种清洗重复数据的方法,包括如 下步骤:将待查询数据进行拆分,根据拆分后的数据中的多个不连续的关键字在数据库中 进行匹配以得到近邻数据集;计算所述近邻数据集中的各个数据与待查询数据的相似度, 并判断所述近邻数据集中是否存在相似度大于阈值的数据;响应于所述近邻数据集中存在 相似度大于阈值的数据,对相似度大于阈值的数据进行拆分,并将拆分后的每个词组与所 述待查询数据进行匹配;以及响应于相似度大于阈值的所述数据的每个词组均能匹配成 功,将所述数据删除。 在一些实施方式中,还包括:响应于所述近邻数据集中不存在相似度大于阈值的 数据,计算所述数据库中的所有数据的相似度。 在一些实施方式中,所述判断所述近邻数据集中是否存在相似度大于阈值的数据 还包括:按照所述近邻数据集中的各个数据的相似度从大到小进行排序,并判断排在首位 的数据的相似度是否大于阈值。 在一些实施方式中,所述将拆分后的每个词组与所述待查询数据进行匹配包括: 4 CN 111597178 A 说 明 书 2/8 页 将拆分后的每个词组与所述待查询数据的词组进行匹配;以及响应于未匹配成功,将拆分 后的每个词组拆分成基本单元,并将所述基本单元与所述待查询数据进行匹配。 本发明实施例的另一方面,还提供了一种清洗重复数据的系统,包括:第一拆分模 块,配置用于将待查询数据进行拆分,根据拆分后的数据中的多个不连续的关键字在数据 库中进行匹配以得到近邻数据集;计算模块,配置用于计算所述近邻数据集中的各个数据 与待查询数据的相似度,并判断所述近邻数据集中是否存在相似度大于阈值的数据;第二 拆分模块,配置用于响应于所述近邻数据集中存在相似度大于阈值的数据,对相似度大于 阈值的数据进行拆分,并将拆分后的每个词组与所述待查询数据进行匹配;以及执行模块, 配置用于响应于相似度大于阈值的所述数据的每个词组均能匹配成功,将所述数据删除。 在一些实施方式中,还包括:第二计算模块,配置用于响应于所述近邻数据集中不 存在相似度大于阈值的数据,计算所述数据库中的所有数据的相似度。 在一些实施方式中,所述计算模块还配置用于:按照所述近邻数据集中的各个数 据的相似度从大到小进行排序,并判断排在首位的数据的相似度是否大于阈值。 在一些实施方式中,所述第二拆分模块还配置用于:将拆分后的每个词组与所述 待查询数据的词组进行匹配;以及响应于未匹配成功,将拆分后的每个词组拆分成基本单 元,并将所述基本单元与所述待查询数据进行匹配。 本发明实施例的又一方面,还提供了一种计算机设备,包括:至少一个处理器;以 及存储器,所述存储器存储有可在所述处理器上运行的计算机指令,所述指令由所述处理 器执行时实现如上方法的步骤。 本发明实施例的再一方面,还提供了一种计算机可读存储介质,计算机可读存储 介质存储有被处理器执行时实现如上方法步骤的计算机程序。 本发明具有以下有益技术效果:通过关键属性判断待查询数据的近邻,在近邻中 进行相似度校验,既能提升效率,又能快速精准定位相似或重复数据,在不增加用户操作难 度的基础上,提升了数据清洗的效率,更便捷的查询出相似或重复数据。 附图说明 为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现 有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本 发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以 根据这些附图获得其他的实施例。 图1为本发明提供的清洗重复数据的方法的实施例的示意图; 图2为本发明提供的清洗重复数据的计算机设备的实施例的硬件结构示意图。











