
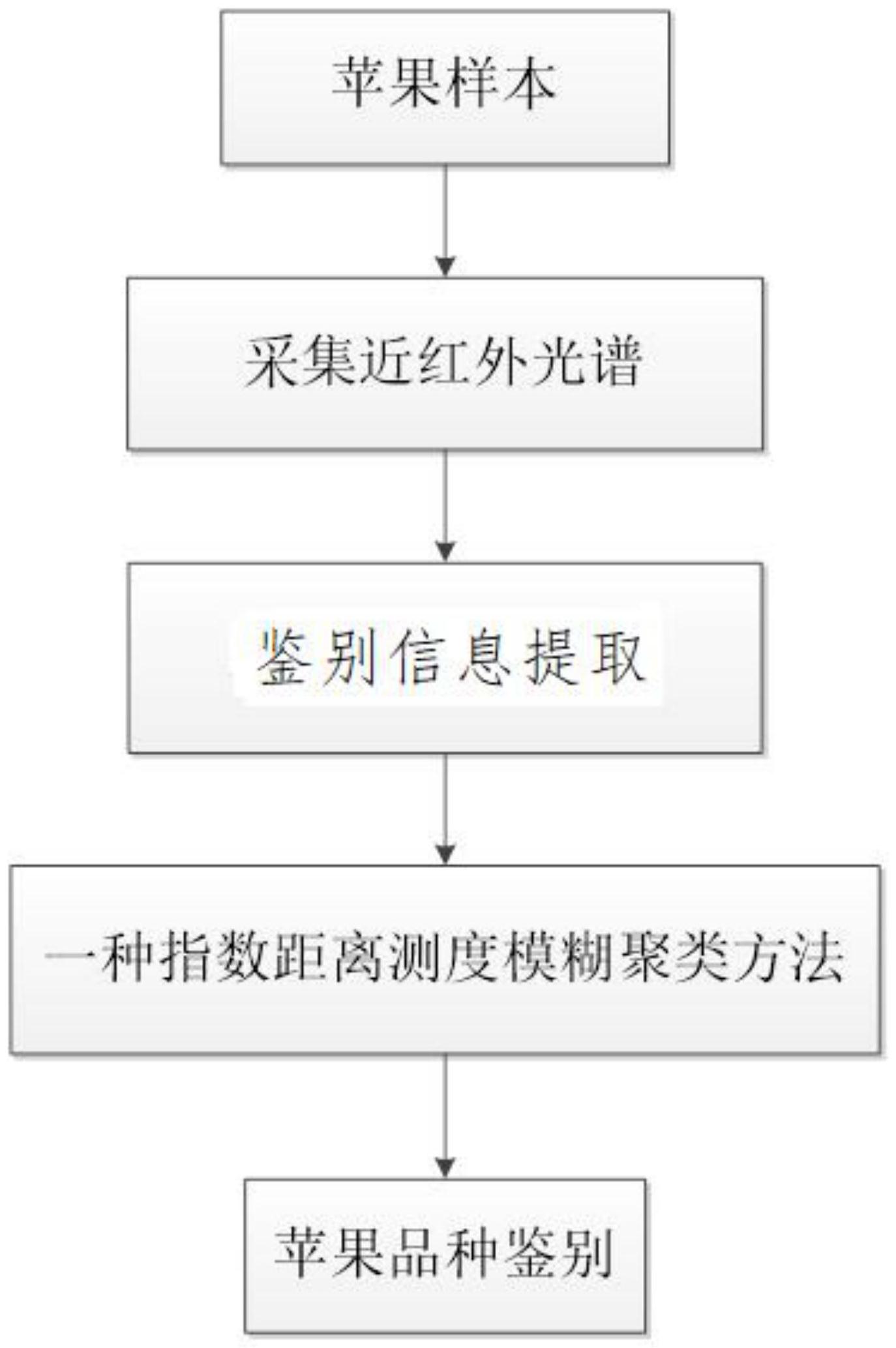
技术摘要:
本发明公开了一种指数距离测度模糊聚类的苹果近红外光谱分类方法,具体步骤如下:(1)应用Antaris II傅立叶变换近红外(FT‑NIR)光谱仪的漫反射模式对多种苹果样本进行扫描,从而获取样本的近红外漫反射光谱数据;(2)运用主成分分析(PCA)对样本的近红外漫反射光谱数据进 全部
背景技术:
苹果富含人体必需的营养物质。但是苹果的品种不同,往往导致其营养成分和口 味不同。对苹果进行理化检测以鉴别苹果的种类非常耗时,这通常需要测量糖含量、酸度并 建立数学模型。尽管理化检测可以得到高准确率、高可靠性的苹果品种鉴别结果,但其普遍 存在成本高、效率低、步骤繁琐、耗时费工、产品破坏大等问题。 近红外光谱技术具有方便,快速,高效,无损,成本低等优点,作为一种检测工具, 已广泛应用于各个领域。近红外光谱的波数范围在10000cm-1~4000cm-1之间,大多数的无 机化合物和有机化合物的化学键振动的基频均在此区域。不同的分子中官能团、化合物的 类别和化合物的立体结构,其近红外吸收光谱不尽相同。实际上,不同种类的苹果中有机物 含量不同,因此漫反射近红外光谱也有所不同,这也为运用近红外光谱技术鉴别茶叶品种 提供了可能。 可能性模糊C均值(PFCM)聚类方法(Nikhil,R.-P.,Kuhu,P.,James,M.-K.,James, C .-B.,A Possibilistic Fuzzy c-Means Clustering Algorithm ,IEEE Trans .Fuzzy Systems,2005,13(4):517-530)解决了模糊C均值聚类(FCM)的噪声敏感性缺陷,克服了可 能C均值聚类(PCM)的聚类重叠问题;由于PFCM的目标函数中使用的是欧氏距离测度,导致 PFCM在处理不同形状、大小和密度的样本数据时,很难获得理想的聚类效果。 使用近红外光谱仪对多个品种苹果的近红外光谱数据进行采集,通过主成分分析 (PCA)对采集来的样本近红外漫反射光谱数据进行降维后,各品种苹果数据的边界往往是 不规则形状的,如果应用基于欧氏距离的PFCM来聚类分析苹果的近红外光谱数据则分类准 确性会很低。
技术实现要素:
本发明是针对现有的PFCM聚类方法在聚类苹果近红外光谱数据时存在的缺点,将 PFCM聚类方法与Gath-Geva聚类方法科学结合,设计了一种指数距离测度模糊聚类的苹果 近红外光谱分类方法,相比原有的PFCM聚类方法,本发明的一种指数距离测度模糊聚类的 苹果近红外光谱分类方法采用基于模糊最大值可能性评估标准距离测度来代替PFCM聚类 方法中的欧氏距离测度。同时,本发明还具有检测成本低、鉴别速度快、分类准确率高等优 点。 本发明依据的原理:研究表明苹果的近红外漫反射光谱包含了苹果内部的有机物 含量信息,不同品种苹果所对应的近红外漫反射光谱不同,因而可以采用聚类方法将不同 品种的苹果近红外光谱进行分类。 一种指数距离测度模糊聚类的苹果近红外光谱分类方法,其具体步骤如下: 3 CN 111595803 A 说 明 书 2/6 页 S1,采集苹果样本的近红外漫反射光谱:应用Antaris II傅立叶变换近红外(FT- NIR)光谱仪的漫反射模式获取苹果样本的近红外漫反射光谱数据;在采集光谱过程中,应 尽可能确保实验室的温度、湿度等外界坏境的恒定;同时,所获得的苹果样本的近红外漫反 射光谱数据为波数范围在10000cm-1~4000cm-1的1557维数据;设置类别数为C。 S2,对苹果近红外漫反射光谱进行鉴别信息提取处理:将苹果近红外光谱数据分 为训练样本集和测试样本集,训练样本数据矩阵 d为样本维数,n为训练样本数量。 具体步骤如下: (1)由训练样本集构造构造矩阵Hft,Hfb和Hfw如下: Hfw=[A1,A2,...,Ac] 上式中, c为类别数,m(m>1)为权重指数,zi为第i(i=1,2,…,n)个近红外光谱训练样本, 为训练样本集的总体样本均值, 为训练样本集中第j(j=1,2,...,c)类样本的样本均 值,uij为训练样本zi属于第j(j=1,2,...,c)类的模糊隶属度,按照下式计算训练样本的 uij: (2)对矩阵Hfb进行QR分解,Hfb=QR,令Sfb=RRT,M=QTHfw,Sfw=MMT (3)对S -1fw Sfb奇异值分解得到其特征向量组成的矩阵P=[φ1 ,φ2 ,φ3 ,......, φt],t=rank(Hfw)。 (4)计算G=QP,对于第k(k=1,2,…,N)个测试样本zk′,经过矩阵G转换后变换为: x =GTk zk′。其中N为测试样本数。 S3,鉴别苹果样本的种类:运用一种指数距离测度模糊聚类的苹果近红外光谱分 类方法方法对S2中已经过鉴别信息处理过的测试样本xk进行聚类分析,从而鉴别苹果样本 的种类; S3.1,初始化:设置阈值ε>0,模糊加权参数m,w∈(1, ∞) ,系数a>0,b>0,类别 数为c;确定最大迭代次数rmax,并且初始迭代计数器r0=1;以S2中降维处理后苹果样本的 近红外漫反射光谱数据的均值作为类中心值 运行模糊C均值聚类得到的模糊隶属度值 和聚类中心值分别作为初始模糊隶属度值 和初始聚类中心 4 CN 111595803 A 说 明 书 3/6 页 S3 .2,计算参数βi: 在迭代过 程中,参数βi作为常数向量存在;N和c分别代表测试样本数据的数量和类别数;v (r-1)i 是第 r-1次迭代计算的聚类中心值;模糊隶属度值u (r-1)ik 表示第r-1次迭代样本xk属于类别i的模 糊隶属度值; S 3 . 3 ,计 算 第 r ( r = 1 ,2 ,… , r m a x ) 次 迭 代 时 的 距 离 范 数 : Dik为样本xk到聚 类 中 心 v i 的 距 离 范 数 ;S f i 是 第 i 个 样 本 类 别 的 模 糊 协 方 差 矩 阵 ,且 pi为先验概率, S3 .4,计算第r次迭代时的模糊隶属度值: u (r)ik 是第r次迭代计算的模糊隶属度值; S3.5,计算第r次迭代时的典型值: t (r)ik 是第r次迭代计算的模糊隶属度值; S 3 . 6 ,计 算 第 r 次 迭 代 时 第 i 类 的 聚 类 中 心 值 其中 是第r次迭代计算的聚类中心vi的值;聚类 中心矩阵V(r)由c个聚类中心值组成,且 S3.7,循环计数增加,即r=r 1;若满足条件:||V(r)-V(r-1)||<ε或r>rmax则计算终 止,否则继续S3.2,根据计算得到的模糊隶属度值和典型值,从而对不同品种的苹果进行分 类。 本发明的有益效果: 本发明的一种指数距离测度模糊聚类的苹果近红外光谱分类方法方法,采用基于 模糊最大值可能性评估标准距离测度,从而能够更加准确地对多种形态、尺寸和密度的苹 果近红外光谱数据进行聚类。本发明在计算苹果近红外光谱数据中鉴别信息时无需进行主 成分分析,避免了因主成分分析丢失鉴别信息的缺点。本发明可以同时产生模糊隶属度值 和典型值对苹果近红外光谱数据进行分析。具有检测成本低、鉴别速度快、分类准确率高等 优点,既适用于苹果品种的鉴别,也适用于其他水果品种的鉴别。 5 CN 111595803 A 说 明 书 4/6 页 附图说明 图1是本发明的流程图; 图2是200个苹果样本的近红外漫反射光谱图; 图3是初始的模糊隶属度; 图4是经鉴别信息提取处理后的苹果测试样本数据; 图5是模糊C均值聚类的模糊隶属度; 图6是一种指数距离测度模糊聚类方法产生的模糊隶属度; 图7是一种指数距离测度模糊聚类方法产生的典型值。











