
技术摘要:
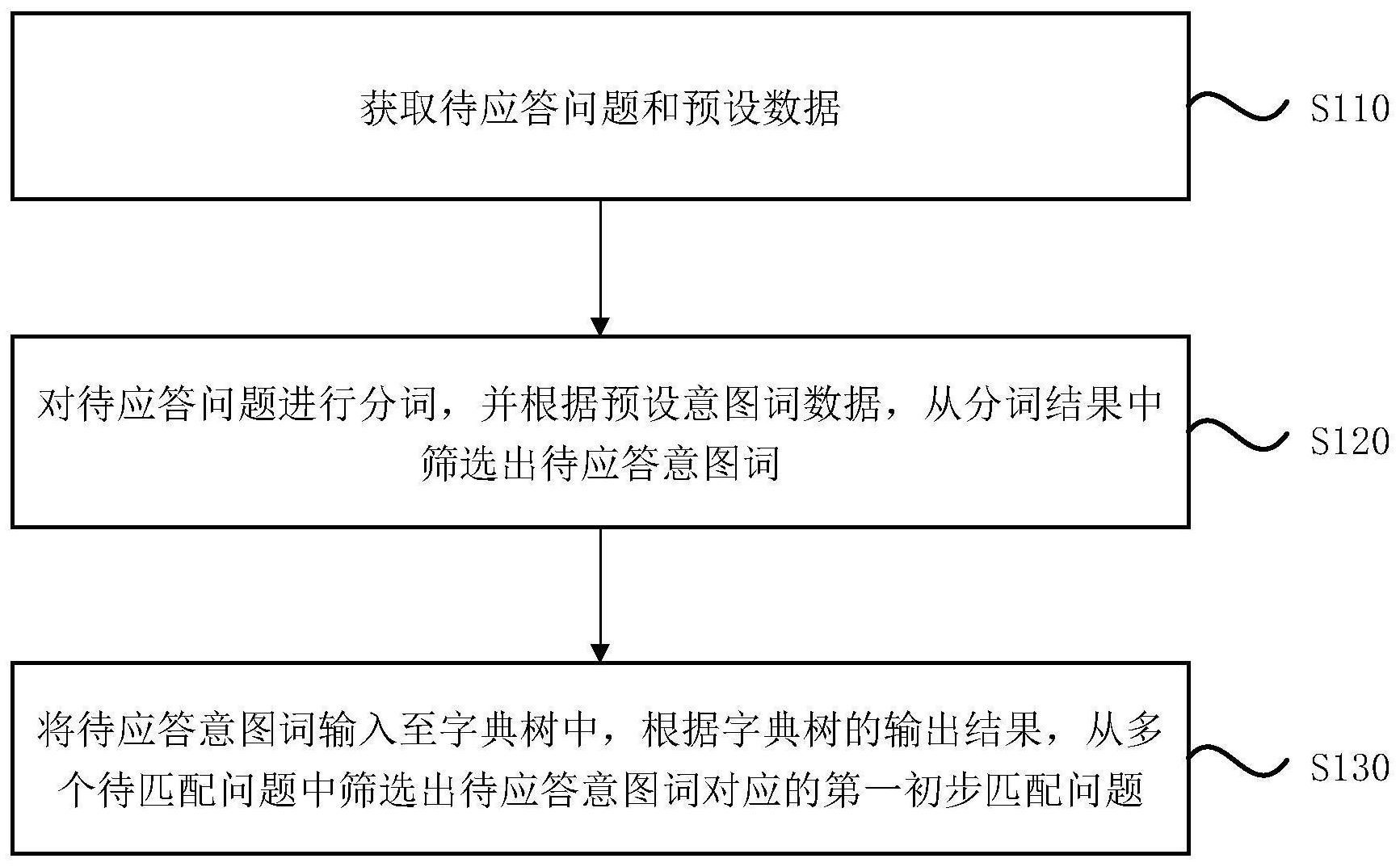
本发明实施例公开了一种应答方法、装置、服务器及存储介质。该方法包括:获取待应答问题和预设数据;对待应答问题进行分词,并根据预设意图词数据,从分词结果中筛选出待应答意图词;将待应答意图词输入至字典树中,根据字典树的输出结果,从多个待匹配问题中筛选出待 全部
背景技术:
智能应答系统在获取到用户提出的待应答问题后,可通过自然语言理解(NLU)对 用户意图进行分类,若是政策咨询类,则进入问答型机器人(QABot)进行应答,否则进入任 务型机器人(TaskBot)进行多轮交互应答。 在QABot中,应答智能系统将待应答问题与问答知识库(QA KnowledgeBase,QAKB) 中的待匹配问题进行匹配,如基于ElasticSearch(一种搜索服务器)按照关键词从各个待 匹配问题中过滤出与待应答提问较为相似的初步匹配问题;然后,再从初步匹配问题中筛 选出与待应答问题的相似度最高的目标匹配问题,并将QAKB中与目标匹配问题对应的目标 应答答案返回给用户。 在实现本发明过程中,发明人发现现有技术中至少存在如下技术问题:在维护 QAKB时,需要将待更新数据推送到ElasticSearch中,这一推送过程可能会出现数据推送失 败的情况,这就会导致问题应答失败,系统稳定性不高;而且,ElasticSearch是一个需要单 独部署的第三方开源服务器,在每次进行问题匹配时,都需要通过ElasticSearch匹配一 遍,匹配性能较差。
技术实现要素:
本发明实施例提供了一种应答方法、装置、服务器及存储介质,以解决问题匹配性 能较差以及因待更新数据推送失败而造成的应答失败的问题。 第一方面,本发明实施例提供了一种应答方法,可以包括: 获取待应答问题和预设数据,其中,预设数据包括字典树,字典树是根据预设问答 知识库和预设意图词数据构造的,预设问答知识库包括多个待匹配问题,预设意图词数据 包括历史应答问题中的目标意图词; 对待应答问题进行分词,并根据预设意图词数据,从分词结果中筛选出待应答意 图词; 将待应答意图词输入至字典树中,根据字典树的输出结果,从多个待匹配问题中 筛选出待应答意图词对应的第一初步匹配问题。 可选的,预设数据还可以包括预设映射数据,预设映射数据包括待匹配问题、待匹 配问题中的待匹配意图词和待匹配意图分类结果间的映射关系;在此基础上,上述应答方 法还可以包括: 基于预设映射数据和待应答意图词,从各待匹配意图分类结果中筛选出已匹配意 图分类结果; 根据待应答意图词和已匹配意图分类结果,分别计算出待应答问题和各已匹配意 5 CN 111737425 A 说 明 书 2/16 页 图分类结果的相关性,并根据相关性从各已匹配意图分类结果中筛选出目标意图分类结 果; 根据预设映射数据,从多个待匹配问题中筛选出与目标意图分类结果对应的第二 初步匹配问题。 可选的,预设问答知识库还可以包括每个待匹配问题的待匹配应答答案,在此基 础上,上述应答方法还可以包括: 将待应答问题、各第一初步匹配问题和各第二初步匹配问题输入至深度语义匹配 模型中,根据深度语义匹配模型的输出结果,分别得到待应答问题与各第一初步匹配问题 间的第一相似度、以及待应答问题与各第二初步匹配问题间的第二相似度; 根据第一相似度从各个第一初步匹配问题中筛选出第一目标匹配问题,并根据第 二相似度从各个第二初步匹配问题中筛选出第二目标匹配问题; 从第一目标匹配问题和第二目标匹配问题中筛选出相似度最高的目标匹配问题, 从多个待匹配应答答案中,筛选出目标匹配问题的目标应答答案,并将目标应答答案作为 待应答问题的应答答案。 可选的,目标意图词可以通过如下步骤预先得到: 对历史应答问题进行分词,计算出各分词结果的意图相关度,并根据意图相关度 从各分词结果中筛选出目标意图词。 可选的,计算出各分词结果中的当前分词结果w的意图相关度,可以包括: 获取历史应答问题的总量Total、各历史应答问题中w出现的次数WordTotal(w)、 包含w的历史应答问题的数量Letter(w)、包含w且存在意图的历史应答问题的数量Itent (w); 根据Total、WordTotal(w)、Letter(w)和Itent(w),计算出w的意图相关度。 可选的,根据Total、WordTotal(w)、Letter(w)和Itent(w),计算出w的意图相关 度,可以包括:通过如下式子计算出w的意图相关度IntentRelation(w): IntentRelation(w)=InFo(w)*ItentWeight(w);其中, InFo(w)=lg(Total/Letter(w)), ItentWeight(w)=WordTotal(w)/Itent(w)*lg(Itent(w))。 可选的,待匹配问题包括标准问题和扩展问题,根据待应答意图词和已匹配意图 分类结果,分别计算出待应答问题和各已匹配意图分类结果的相关性,可以包括: 获取包含待应答意图词W且意图为各已匹配意图分类结果中的当前意图分类结果 m的待匹配问题的数量WordToIntent(W,m)、包含W的待匹配问题的数量Letter(W)、意图为m 的待匹配问题的数量Itent(m)、待匹配问题L中目标意图词的数量IntentWord(L)、意图为m 的标准问题的数量StandardQuestion(m)和待应答问题CurrenQuestion; 根据Word ToIntent (W ,m)、Letter (W)、Itent (m)、IntentWord (L)、 StandardQuestion(m)和CurrenQuestion,计算出CurrenQuestion和m的相关性。 可选的,根据WordToIntent(W ,m)、Letter(W)、Itent(m)、IntentWord(L)、 StandardQuestion(m)和CurrenQuestion,计算出CurrenQuestion和m的相关性,可以包括: 通过如下式子计算出CurrenQuestion和m的相关性F(m): F(m)=(Letter(W)/WordToIntent(W,m))*lg(Intent(m))*E(m);其中, 6 CN 111737425 A 说 明 书 3/16 页 E(m)=1-|IntentWord(StandardQuestion(m))-IntentWord(CurrenQuestion)|* log100(IntentWord(StandardQuestion(m)))。 可选的 ,若C u r r e n Q u e s t i o n包括待应答意图词W 1 、W 2… W N ,则 其中 ,N 是CurrenQuestion中的所述待应答意图词的总个数,N是大于1的整数。 第二方面,本发明实施例还提供了一种应答装置,该装置可以包括: 获取模块,用于获取待应答问题和预设数据,其中,预设数据包括字典树,字典树 是根据预设问答知识库和预设意图词数据构造的,预设问答知识库包括多个待匹配问题, 预设意图词数据包括历史应答问题中的目标意图词; 分词模块,用于对待应答问题进行分词,并根据预设意图词数据,从分词结果中筛 选出待应答意图词; 筛选模块,用于将待应答意图词输入至字典树中,根据字典树的输出结果,从多个 待匹配问题中筛选出待应答意图词对应的第一初步匹配问题。 第三方面,本发明实施例还提供了一种服务器,该服务器可以包括: 一个或多个处理器; 存储器,用于存储一个或多个程序; 当一个或多个程序被一个或多个处理器执行,使得一个或多个处理器实现本发明 任意实施例所提供的应答方法。 第四方面,本发明实施例还提供了一种计算机可读存储介质,其上存储有计算机 程序,该计算机程序被处理器执行时实现本发明任意实施例所提供的应答方法。 本发明实施例的技术方案,通过获取待应答问题和预设数据,该预设数据包括根 据预设问答知识库和预设意图词数据构造的字典树,由此,针对每个待应答问题,可以先对 其进行分词,并根据预设意图词数据从分词结果中筛选出待应答意图词,该待应答意图词 是属于预设意图词数据中的分词结果;在将待应答意图词输入至字典树后,可以根据字典 树的输出结果,从多个待匹配问题中筛选出待应答意图词对应的第一初步匹配问题。上述 技术方案,基于可以直接加载在内存中的字典树实现待应答问题和待匹配问题的初步匹 配,提高了问题匹配性能,并且由于匹配过程未涉及到第三方服务器,无需进行待更新数据 的推送,从而避免了因待更新数据推送失败而造成的应答失败的问题,达到了提高智能应 答系统的稳定性和问题匹配效率的效果。 附图说明 图1是本发明实施例一中的一种应答方法的流程图; 图2是本发明实施例一中的一种应答方法中字典树的示意图; 图3是本发明实施例二中的一种应答方法的流程图; 图4a是本发明实施例二中的一种应答方法的优选实施例的结构框图; 图4b是本发明实施例二中的一种应答方法的优选实施例的流程图; 图5是本发明实施例三中的一种应答装置的结构框图; 图6是本发明实施例四中的一种服务器的结构示意图。 7 CN 111737425 A 说 明 书 4/16 页











