
技术摘要:
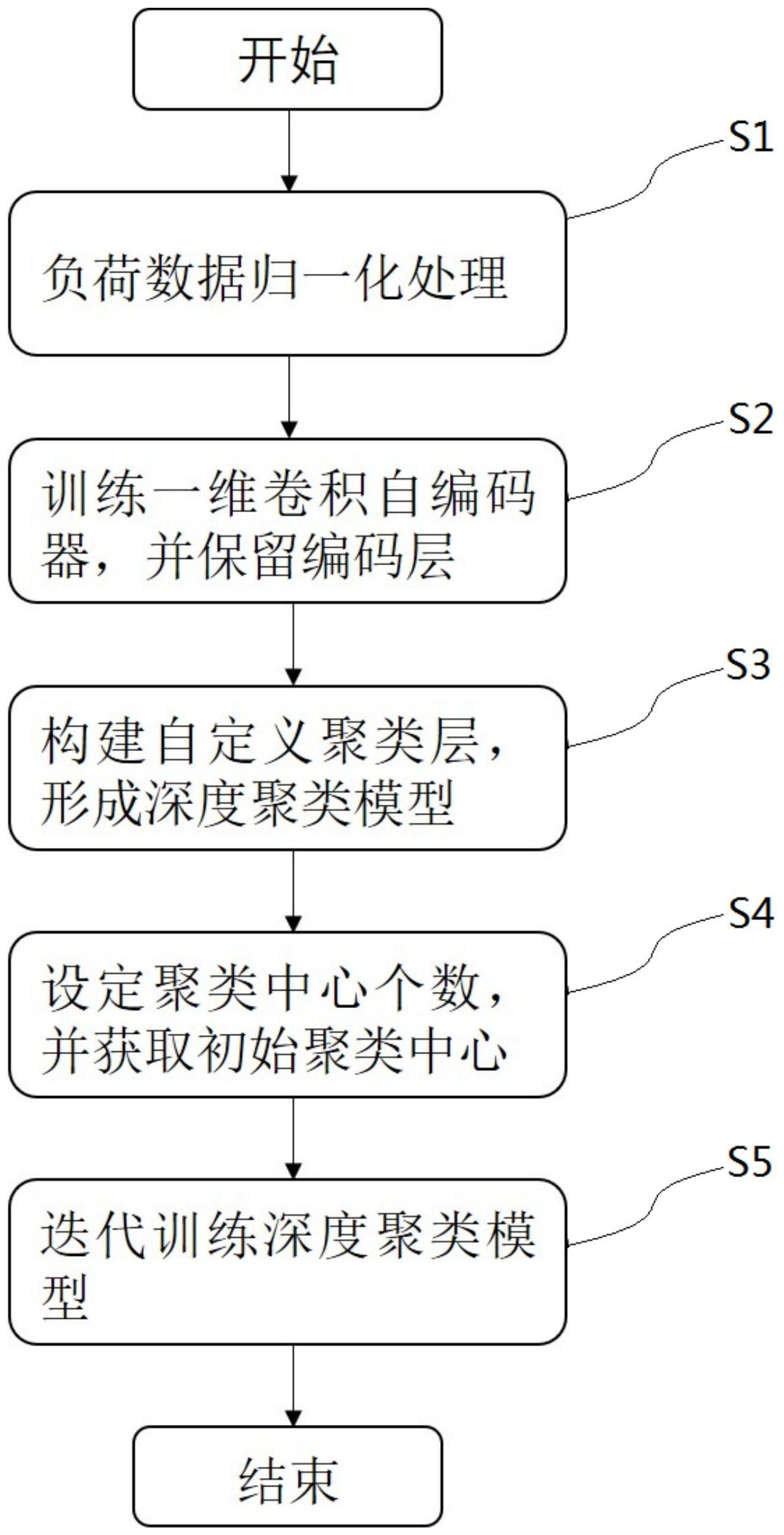
本发明提供一种基于一维卷积自编码器的负荷曲线深度嵌入聚类方法,用于根据用户的原始负荷数据进行聚类分析,其特征在于,包括如下步骤:数据预处理,获取用户的原始负荷数据并对该负荷数据进行预处理,从而获得归一化的日负荷功率数据集;数据训练,使用日负荷功率数 全部
背景技术:
随着智能电表等高级电力计量装置在配用电侧的广泛安装,电力公司的信息采集 能力得到了不断的提升,因此能够记录海量高维的电力负荷数据。电力负荷数据是电网企 业分析用户用电行为的基础。同时,随着泛在电力物联网的建设推进,深入挖掘电力大数据 的应用价值日益受到重视。 电力负荷曲线聚类即利用各种聚类算法,对负荷曲线进行快速有效地分类,是配 用电数据挖掘的重要基础。负荷控制、分时电价制定、负荷预测、用电异常检测等各种电力 数据挖掘应用都需要电力负荷曲线聚类分析。负荷曲线聚类算法及相关技术的研究对电力 系统安全、经济、可靠的运行具有重要的支撑作用。 负荷曲线聚类方法可以分为直接聚类和间接聚类。直接聚类方法是对负荷数据本 身聚类分析。在电力大数据时代,电力负荷数据呈现数量大、维数高等特征,该类方法计算 效率较低,且聚类效果不佳。间接聚类方法即先利用降维算法对负荷数据提取特征,再根据 特征聚类分析。该类方法特征提取和聚类任务分离,无法保证提取的特征适合聚类任务,且 难以有效提取负荷数据所蕴含的深层特征,从而可能降低聚类的质量。
技术实现要素:
为解决上述问题,提供一种基于一维卷积自编码器的负荷曲线深度嵌入聚类方 法,以提高聚类准确性和效率,本发明采用了如下技术方案: 本发明提供了一种基于一维卷积自编码器的负荷曲线深度嵌入聚类方法,用于根 据用户的原始负荷数据进行聚类分析,其特征在于,包括如下步骤:数据预处理,获取用户 的原始负荷数据并对该负荷数据进行预处理,从而获得归一化的日负荷功率数据集以及日 负荷功率曲线的有功功率矩阵;数据训练,使用日负荷功率数据训练一维卷积自编码器,保 留编码层;模型构建,在编码层的基础上构建聚类层形成深度聚类模型;聚类中心设定,设 定聚类中心个数,并运用K-means聚类算法初始化聚类层的聚类中心并进行负荷的初始分 配;迭代训练,对深度聚类模型进行迭代训练,每一次迭代调整网络参数以及聚类中心并获 取聚类标签,当聚类标签变化小于预定值时,输出此时的聚类标签。 本发明提供的基于一维卷积自编码器的负荷曲线深度嵌入聚类方法,还可以具有 这样的特征,数据预处理的具体步骤如下:设Pk=[pk1,..,pki,...,pkm]为第k条所诉日负荷 功率曲线的m点原始有功功率矩阵,k=1,2,...,N,N为日负荷功率曲线总条数,pki为第k条 日负荷功率曲线的第i点原始有功功率,i=1 ,2 ,...,m,m为采样点个数,则P=[P1 ,.., Pk,...,P TN] 为N条日负荷功率曲线的m点原始有功功率矩阵,以日负荷功率曲线的功率最大 值Pk·max=max{pk1,..,pki,...,pkm}为基准值,以日负荷功率曲线的功率最小值Pk·min=min 4 CN 111612319 A 说 明 书 2/5 页 {pk1,..,pki,...,pkm},对原始负荷数据进行归一化处理,从而获得归一化的日负荷功率曲 线的有功功率矩阵P'=[P'1,..,P'k,...,P' ]TN ,计算公式如下: 本发明提供的基于一维卷积自编码器的负荷曲线深度嵌入聚类方法,还可以具有 这样的特征,数据训练的具体步骤如下:一维卷积自编码器包括编码器以及解码器,将一组 归一化处理后的日负荷功率数据集x={x1 ,...,xn}作为输入数据,输出重构数据y= {y1,...,yn},编码器通过多个卷积层将输入数据映射到低维的隐变量空间,解码器将隐变 量空间反向映射到输入层还原输入数据,编码器编码以及解码器解码的计算公式如下: h=σ(W1·x b1) y=σ(W2·h b2) 式中,h为被提取的深层特征,W1为由多个编码器组成的编码器网络的权重矩阵,W2 为由多个解码器组成的解码器网络的权重矩阵,b1和b2分别为编码器和解码器的偏置向量, y为重构数据,调整网络参数使得损失函数E(θ)最小,网络参数为W1、W2、b1以及b2,损失函数 E(θ)计算公式如下: 利用梯度下降法求解E(θ)从而获得网络参数的最优集合,实现对一维卷积自编码 器的构建与训练,提取归一化处理后的日负荷功率曲线的深层特征。 本发明提供的基于一维卷积自编码器的负荷曲线深度嵌入聚类方法,还可以具有 这样的特征,模型构建的具体过程如下:网络输入的数据维度并为聚类层创建一个可训练 的聚类中心uj, 定义度量聚类中心与负荷数据曲线特征的相似度的计算公式如下: 式中,zi为编码后的负荷数据,qij为负荷数据zi属于聚类中心uj的概率。 本发明提供的基于一维卷积自编码器的负荷曲线深度嵌入聚类方法,还可以具有 这样的特征,聚类中心设定的具体过程如下: 步骤T1,设定K个聚类中心,并对设定的聚类中心初始化, 步骤T2,对提取深层特征的日负荷功率数据集中的每个样本数据,计算其与聚类 中心的欧氏距离,并根据样本到聚类中心的最小欧氏距离进行划分, 步骤T3,根据步骤T2的划分结果更新聚类中心, 步骤T4,重复步骤T2和步骤T3,直到聚类中心不再变化, 步骤T5,输出聚类中心以及初始的样本分布。 本发明提供的基于一维卷积自编码器的负荷曲线深度嵌入聚类方法,还可以具有 这样的特征,迭代训练的具体过程如下: 设定深度聚类模型的损失函数L为KL散度,标签分配变化阈值为δ,损失函数L的计 算公式如下: 5 CN 111612319 A 说 明 书 3/5 页 式中,P是日负荷功率数据集的真实分布,Q是数据的理论分布, 对深度聚类模型进行迭代训练,对网络参数以及聚类中心进行调整,若负荷数据 分布P前后变化小于标签分配变化阈值为δ,则终止对深度聚类模型的迭代训练并将此时的 聚类中心作为结果进行输出。 发明作用与效果 根据本发明的基于一维卷积自编码器的负荷曲线深度嵌入聚类方法,对用户的原 始负荷数据进行预处理获得归一化的日负荷功率数据以及日负荷功率曲线的有功功率矩 阵,再使用日负荷功率数据训练一维卷积自编码器,进一步利用该一维卷积自编码器准确 提取负荷数据的深度特征,减少了原始信息的损失。采用特征提取和聚类分析联合优化的 模型。在迭代过程中,提取合适的特征用于聚类算法,以提高聚类准确性和效率。 附图说明 图1是本发明实施例的基于一维卷积自编码器的负荷曲线深度嵌入聚类方法的流 程图; 图2是本发明实施例的一维卷积自编码器的特征提取结果图; 图3是本发明实施例的聚类结果图。











