
技术摘要:
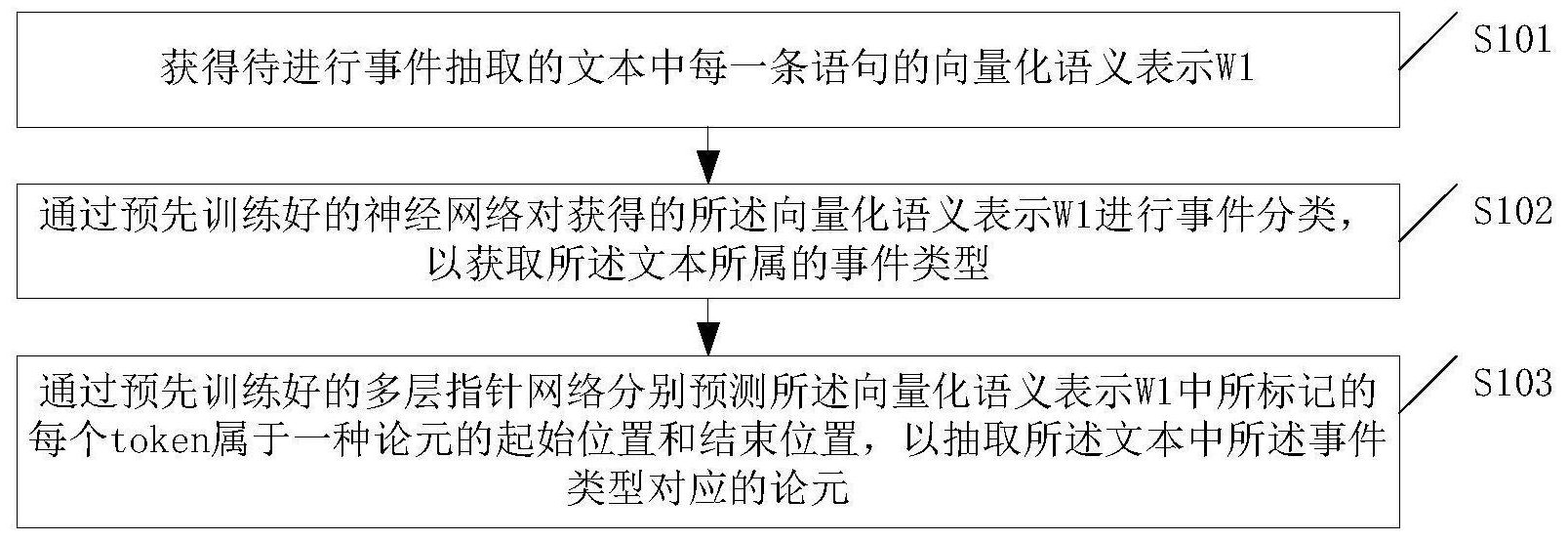
本申请实施例公开了一种事件抽取方法、装置和计算机可读存储介质,该方法包括:获得待进行事件抽取的文本中每一条语句的向量化语义表示W1;通过预先训练好的神经网络对获得的所述向量化语义表示W1进行事件分类,以获取所述文本所属的事件类型;通过预先训练好的多层指 全部
背景技术:
互联网上每天都会产生大量的新闻数据,描述许多已经发生的事件。但由于事件 种类繁多,无法快速而且准确地分辨事件的类型以及事件的各个因素,如时间、地点、参与 人等信息。 对发生的公共事件或者特定行业内所发生的事件进行区分和主要因素识别,不仅 有助于实时把握事件的发展趋势以及整个行业的发展方向,也可辅助高层决策,降低风险, 具有重要的实际应用价值和研究意义。 现有的识别方法:[1]基于图神经网络的模型;[2]基于深度学习、注意力机制、序 列标注、划分span(片段)的模型等。 现有方法存在以下缺点: 1、现有方法很多进行触发词的抽取,但是往往准确度不高且严重影响后续论元的 抽取,同时触发词不容易标注,因此在实际应用中使用很少。 2、现有方法大都使用特定的自然语言处理工具,如Jieba、ltp、standfordNLP等, 首先对句子进行分词,建立依存树,然后再将这些特征输入模型。缺点在于:处理繁琐,而且 这些工具在处理的过程中本身具有一定的误差,因此在后续建模分析的过程中会存在误差 累积的问题。 3、基于序列标注的一系列模型很难解决事件论元存在交叉的情况,比如“北京的 法院”为一个事件论元(机构),但是“北京”本身也是一种论元(地名)。 4、基于span的方法虽然能解决事件论元存在交叉的情况,但是该方法的复杂度比 较高,尤其是当文本长度较长时,复杂度是难以接受的。
技术实现要素:
本申请实施例提供了一种事件抽取方法、装置和计算机可读存储介质,能够不依 赖于特定的自然语言处理工具,解决事件主体存在交叉的情况,提高事件抽取的效率,具有 一定的通用性。 本申请实施例提供了一种事件抽取方法,所述方法可以包括: 获得待进行事件抽取的文本中每一条语句的向量化语义表示W1; 通过预先训练好的神经网络对获得的所述向量化语义表示W1进行事件分类,以获 取所述文本所属的事件类型; 通过预先训练好的多层指针网络分别预测所述向量化语义表示W1中所标记的每 个token属于一种论元的起始位置和结束位置,以抽取所述文本中所述事件类型对应的论 元。 4 CN 111723569 A 说 明 书 2/7 页 本申请实施例还提供了一种事件抽取装置,可以包括处理器和计算机可读存储介 质,所述计算机可读存储介质中存储有指令,当所述指令被所述处理器执行时,实现上述任 意一项所述的事件抽取方法。 本申请实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,所述 计算机程序被处理器执行时实现上述任意一项所述的事件抽取方法。 与相关技术相比,本申请实施例包括获得待进行事件抽取的文本中每一条语句的 向量化语义表示W1;通过预先训练好的神经网络对获得的所述向量化语义表示W1进行事件 分类,以获取所述文本所属的事件类型;通过预先训练好的多层指针网络分别预测所述向 量化语义表示W1中所标记的每个token属于一种论元的起始位置和结束位置,以抽取所述 文本中所述事件类型对应的论元。通过该实施例方案,能够判断句子(或文档)所属的事件 类型并将对应的论元抽取出来,不依赖于特定的自然语言处理工具,解决了事件主体存在 交叉的情况,提高了事件抽取的效率,具有一定的通用性。 本申请的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变 得显而易见,或者通过实施本申请而了解。本申请的其他优点可通过在说明书以及附图中 所描述的方案来实现和获得。 附图说明 附图用来提供对本申请技术方案的理解,并且构成说明书的一部分,与本申请的 实施例一起用于解释本申请的技术方案,并不构成对本申请技术方案的限制。 图1为本申请实施例的事件抽取方法流程图; 图2为本申请实施例的通过预先训练好的神经网络对获得的所述向量化语义表示 W1进行事件分类的方法流程图; 图3为本申请实施例的通过预先训练好的多层指针网络分别预测所述向量化语义 表示W1中所标记的每个token属于一种论元的起始位置和结束位置的方法流程图; 图4为本申请实施例的事件抽取装置组成框图。











