
技术摘要:
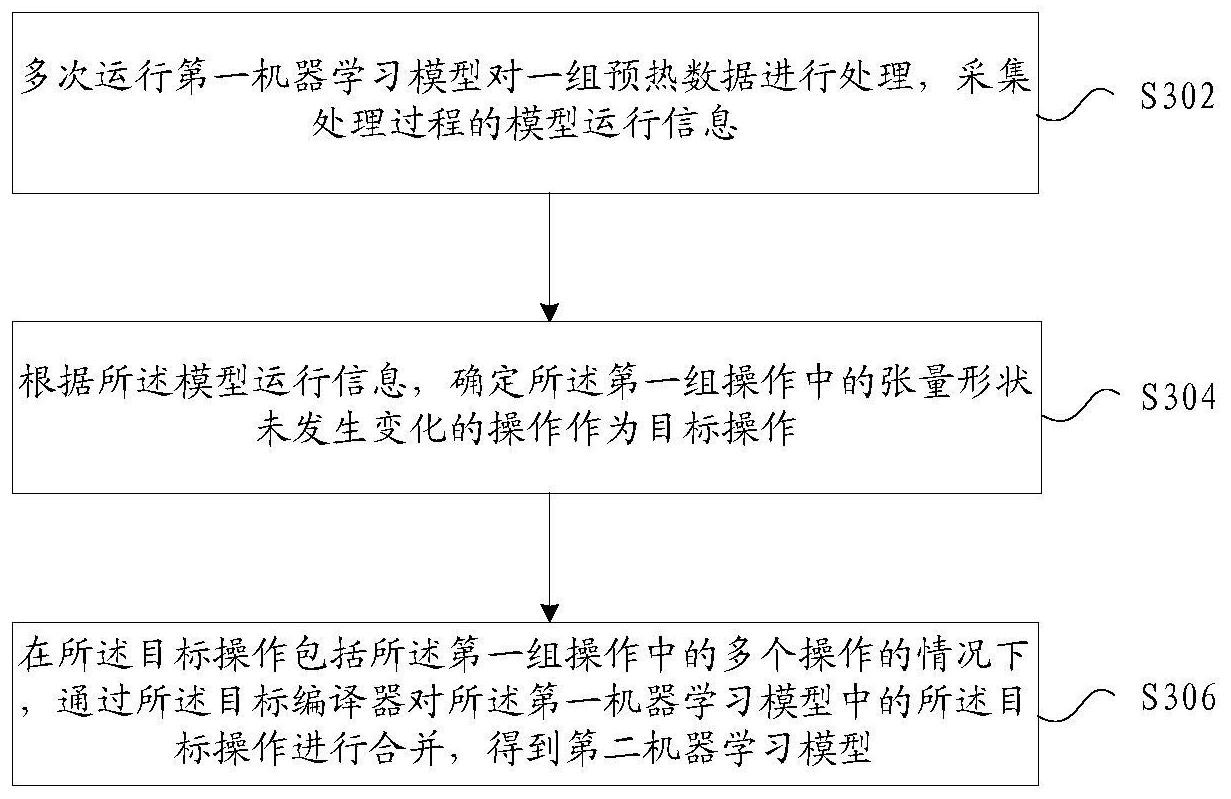
本发明公开了一种机器学习模型的编译优化方法和装置。其中,该方法包括:多次运行第一机器学习模型对一组预热数据进行处理,采集处理过程的模型运行信息;根据所述模型运行信息,确定所述第一组操作中的张量形状未发生变化的操作作为目标操作;在所述目标操作包括所述 全部
背景技术:
机器学习系统中的编译优化有提前编译和即时编译两大类技术。现有机器学习系 统在编译时,没有引入运行时的采样信息,由于没有采样运行时张量形状的变化信息,会导 致在多次迭代过程中因为部分操作张量形状变化引发计算图大部分操作的重新编译。这类 重编译非常耗时且耗内存。 针对相关技术中,由于在机器学习在编译时没有引入运行时的采样信息,导致的 编译周期长、浪费资源的问题,目前尚未存在有效的解决方案。
技术实现要素:
本发明实施例提供了一种机器学习模型的编译优化方法和装置,以至少解决由于 在机器学习在编译时没有引入运行时的采样信息,导致的编译周期长、浪费资源的技术问 题。 根据本发明实施例的一个方面,提供了一种机器学习模型的编译优化方法,包括: 多次运行第一机器学习模型对一组预热数据进行处理,采集处理过程的模型运行信息,其 中,所述第一机器学习模型包括第一组操作,所述第一组操作中的操作为允许被目标编译 器处理的操作;根据所述模型运行信息,确定所述第一组操作中的张量形状未发生变化的 操作作为目标操作;在所述目标操作包括所述第一组操作中的多个操作的情况下,通过所 述目标编译器对所述第一机器学习模型中的所述目标操作进行合并,得到第二机器学习模 型,其中,所述第二机器学习模型包括第二组操作,所述第二组操作中操作的数量小于所述 第一组操作中操作的数量。 可选地,所述通过所述目标编译器对所述第一机器学习模型中的所述目标操作进 行合并,得到第二机器学习模型,包括:通过所述目标编译器将所述第一机器学习模型中的 所述目标操作合并成一个操作,保留所述第一机器学习模型中除所述目标操作之外的操 作,并将所述目标操作的输入张量和输出张量转换为所述一个操作的输入张量和输出张 量,得到所述第二机器学习模型;或者通过所述目标编译器将所述第一机器学习模型中的 所述目标操作合并成多个操作,保留所述第一机器学习模型中除所述目标操作之外的操 作,并将所述目标操作的输入张量和输出张量转换为合并成的所述多个操作的输入张量和 输出张量,得到所述第二机器学习模型,其中,所述合并成的所述多个操作中操作的数量小 于所述目标操作中操作的数量。 可选地,所述一组预热数据包括多个预热数据集,其中,所述多次运行第一机器学 习模型对一组预热数据进行处理,采集处理过程的模型运行信息,包括:重复执行多次以下 步骤:将一个所述预热数据集中的多个输入张量分别输入至所述第一组操作中部分或全部 5 CN 111580827 A 说 明 书 2/12 页 的操作,运行一次所述第一机器学习模型,得到所述第一组操作中的每个操作的输入张量 和输出张量;比较在所述多次运行所述第一机器学习模型的过程中所述第一组操作中的每 个操作的输入张量和输出张量的形状是否发生变化,得到所模型运行信息。 可选地,所述多次运行第一机器学习模型对一组预热数据进行处理,采集处理过 程的模型运行信息,包括:重复执行多次以下步骤:将所述一组预热数据中的多个输入张量 分别输入至所述第一组操作中部分或全部的操作,运行一次所述第一机器学习模型,得到 所述第一组操作中的每个操作的输入张量和输出张量;比较在所述多次运行所述第一机器 学习模型的过程中所述第一组操作中的每个操作的输入张量和输出张量的形状是否发生 变化,得到所模型运行信息。 可选地,所述多次运行第一机器学习模型对一组预热数据进行处理,采集处理过 程的模型运行信息,包括:每运行一次所述第一机器学习模型,记录在该次运行所述第一机 器学习模型的过程中所述第一组操作中的每个操作的输入张量和输出张量;从第二次运行 所述第一机器学习模型开始,每运行一次所述第一机器学习模型,将当前一次记录的所述 第一组操作中的每个操作的输入张量和输出张量与上一次记录的所述第一组操作中的每 个操作的输入张量和输出张量的形状进行比较,得到所述模型运行信息。 可选地,所述多次运行第一机器学习模型对一组预热数据进行处理,采集处理过 程的模型运行信息,包括:每运行一次所述第一机器学习模型,记录在该次运行所述第一机 器学习模型的过程中所述第一组操作中标记为尚未变化的操作的输入张量和输出张量,其 中,在第一次运行所述第一机器学习模型的过程中,所述第一组操作中的每个操作被标记 为尚未变化的操作;从第二次运行所述第一机器学习模型开始,每运行一次所述第一机器 学习模型,将当前一次记录的所述第一组操作中标记为尚未变化的操作的输入张量和输出 张量与上一次记录的输入张量和输出张量的形状进行比较,将所述标记为尚未变化的操作 中输入张量和/或输出张量发生形状变化的操作标记为已发生变化的操作,将所述标记为 尚未变化的操作中输入张量和输出张量的形状未发变化的操作继续标记为尚未变化的操 作;在多次运行所述第一机器学习模型之后,确定出所述模型运行信息,其中,所述模型运 行信息包括:第一运行信息,用于指示所述第一组操作中标记为尚未变化的操作;和/或,第 二运行信息,用于指示所述第一组操作中标记为已发生变化的操作。 可选地,所述方法还包括:在所述多次运行所述第一机器学习模型对一组预热数 据进行处理的过程中,获取所述第一组操作中的每个操作的运行状态信息,其中,所述运行 状态信息包括每个操作的运行时间和/或所需的运行资源;根据所述运行状态信息为所述 第二组操作中的每个操作分配相应的运行资源。 可选地,在所述得到第二机器学习模型之后,所述方法还包括:将正式数据输入至 所述第二机器学习模型,其中,所述正式数据中包括一组正式输入张量;通过所述目标编译 器对所述第二机器学习模型进行编译,得到所述第二机器学习模型对所述一组正式输入张 量进行处理后输出的处理结果。 根据本发明实施例的另一方面,还提供了一种机器学习模型的编译优化装置,包 括:处理模块,用于多次运行第一机器学习模型对一组预热数据进行处理,采集处理过程的 模型运行信息,其中,所述第一机器学习模型包括第一组操作,所述第一组操作中的操作为 允许被目标编译器处理的操作;确定模块,用于根据所述模型运行信息,确定所述第一组操 6 CN 111580827 A 说 明 书 3/12 页 作中的张量形状未发生变化的操作作为目标操作;合并模块,用于在所述目标操作包括所 述第一组操作中的多个操作的情况下,通过所述目标编译器对所述第一机器学习模型中的 所述目标操作进行合并,得到第二机器学习模型,其中,所述第二机器学习模型包括第二组 操作,所述第二组操作中操作的数量小于所述第一组操作中操作的数量。 根据本发明实施例的又一方面,还提供了一种计算机可读的存储介质,该计算机 可读的存储介质中存储有计算机程序,其中,该计算机程序被设置为运行时执行上述机器 学习模型的编译优化方法。 根据本发明实施例的又一方面,还提供了一种电子设备,包括存储器和处理器,上 述存储器中存储有计算机程序,上述处理器被设置为通过所述计算机程序执行上述的机器 学习模型的编译优化方法。 在本发明实施例中,采用多次运行第一机器学习模型对一组预热数据进行处理的 方式,得到模型运行信息,通过模型运行信息确确定所述第一组操作中的张量形状未发生 变化的操作作为目标操作。在目标操作包括第一组操作中的多个操作的情况下,通过目标 编译器对第一机器学习模型中的所述目标操作进行合并,得到第二机器学习模型。达到了 引入机器学习模型编译运行时的张量信息,对机器学习模型进行优化的目的,从而实现了 提升机器学习模型的编译效率的技术效果,进而解决了由于在机器学习在编译时没有引入 运行时的采样信息,导致的编译周期长、浪费资源的技术问题。 附图说明 此处所说明的附图用来提供对本发明的进一步理解,构成本申请的一部分,本发 明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中: 图1是根据本发明实施例的机器学习模型的编译优化方法的硬件环境的示意图; 图2是根据本发明实施例的一种可选的机器学习模型的编译优化方法的应用框架 图; 图3是根据本发明实施例的机器学习模型的编译优化方法的流程图; 图4是根据本发明一个可选实施例的机器学习模型的编译优化方法示意图一; 图5是根据本发明一个可选实施例的机器学习模型的编译优化方法示意图二; 图6是根据本发明一个可选实施例的机器学习模型的编译优化方法示意图三; 图7是根据本发明一个可选实施例的机器学习模型的编译优化方法示意图四; 图8是根据本发明一个可选实施例的机器学习模型的编译优化方法示意图五; 图9是根据本发明一个可选实施例的机器学习模型的编译优化方法示意图六; 图10是根据本发明一个可选实施例的机器学习模型的编译优化方法示意图七; 图11是根据本发明实施例的机器学习模型的编译优化装置的结构框图; 图12是根据本发明实施例的一种可选的电子设备的结构示意图。











