
技术摘要:
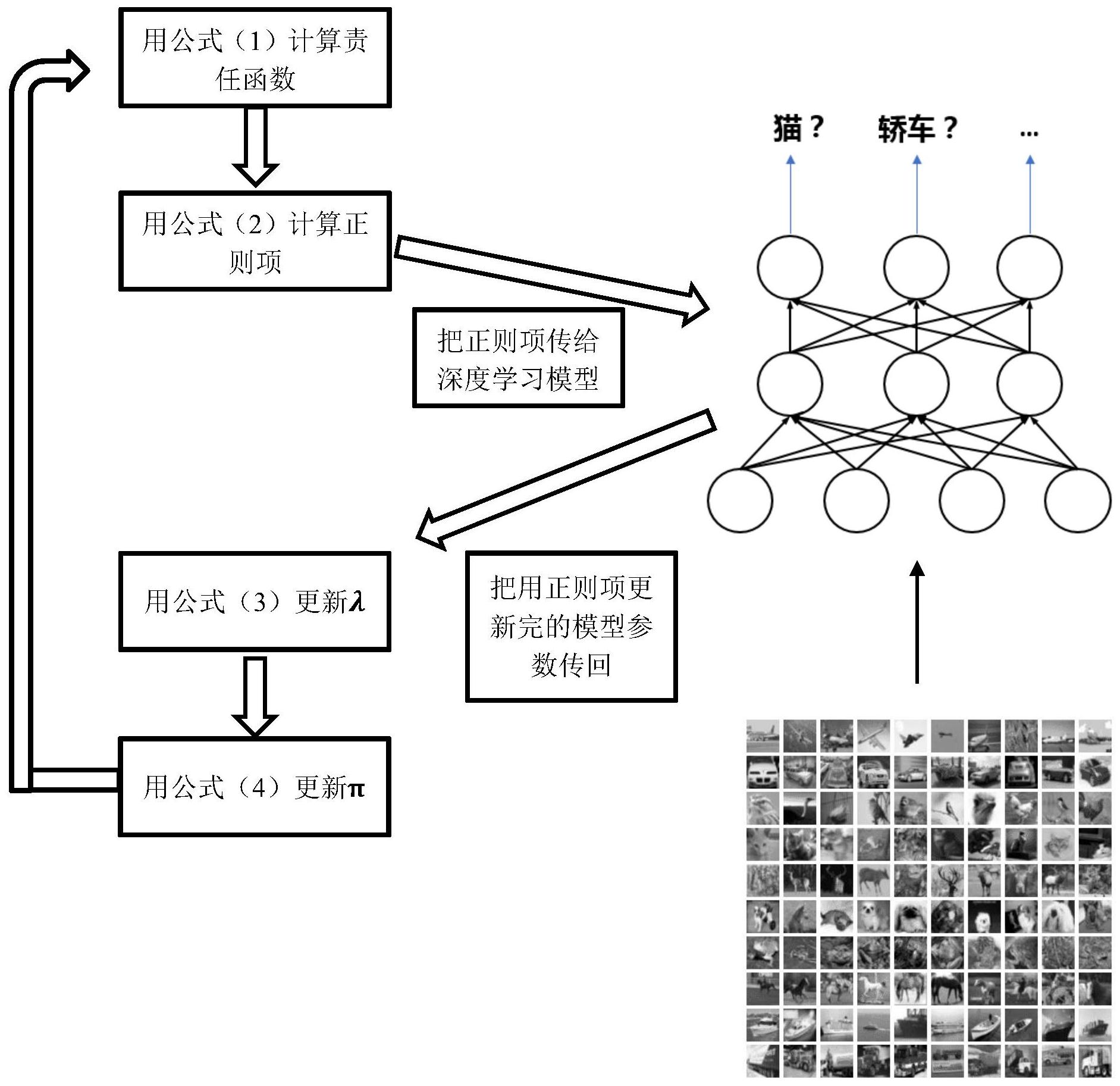
本发明公开了一种针对图像深度学习模型识别的自适应正则化优化处理方法。建立深度学习模型,提取出深度学习模型每一层的模型参数;首先计算混合高斯中高斯模型对于深度学习模型的每一层模型参数的责任函数;再采用以下公式处理获得自适应的正则项;依次重复步骤迭代处 全部
背景技术:
深度学习技术在近些年发展的非常迅猛,尤其是在图像识别领域。给定一幅图片, 深度学习模型现在可以非常准确地给出这个图像展示的物体的类别,比如猫,狗,鸟,汽车 等等。这个应用对于自动驾驶和人脸识别等都是十分适用的。现阶段图像识别的深度学习 模型准确率越来越高,同时它们的层数也变得越来越多。举一个著名的图像识别比赛, ILSVRC作为例子。从2012年到2015年,每年赢得比赛的深度学习模型的层数从8层上升到 152层。 但是,当模型层数变得越来越多,过拟合问题就变得越来越突出。过拟合是指在训 练数据有限的情况下,模型在训练图像上表现得非常好,但在新的测试图像上表现不好的 现象。过拟合现象在层数很多的模型中非常常见,而且也极大地影响着模型的性能。 幸运的是,过拟合问题能由正则化方法很好的解决。正则化方法的基本思路是在 优化目标函数中加一个惩罚项(正则项)以此来惩罚太过于复杂的模型。传统的正则化方法 包括L1正则化方法[可参考Williams PM.Bayesian regularization and pruning using a Laplace prior.Neural computation.1995 Jan;7(1):117-43.]以及L2正则化方法[可 参考Wang Y,Sun X,Liu L.A variable step size LMS adaptive filtering algorithm based on L2 norm.In2016 IEEE International Conference on Signal Processing , Communications and Computing(ICSPCC)2016 Aug 5(pp.1-6) .IEEE.]。但是这些方法都 是非常实验性的。比如说,对于一个有多层的深度学习模型,数据科学家需要对模型的每一 层试验得出一个固定的最好的正则项参数β,这个过程是十分耗时和辛苦的。特别是当深度 学习模型的层数上升到几百几千层的时候,这种手动试验得到每层合适的正则项参数就会 显得非常不现实。
技术实现要素:
为了解决











