
技术摘要:
本发明属于数据安全保护技术领域,公开了一种轨迹隐私保护方法、隐私保护系统、存储介质及移动设备,对每一时间戳下的位置进行聚类;连接不同时间戳下簇的中心,经过过滤得到重构轨迹数据集Ω;对重构轨迹数据集Ω进行筛选得到n条合适的重构轨迹;对筛选得到的n条重构 全部
背景技术:
随着基于位置的服务以及应用的广泛使用,越来越来的轨迹信息被收集。轨迹数 作为个体移动路径,在许多领域内具有很重要的价值。例如,学习群体时空移动模式,从而 改善基于位置的应用的用户体验效果;帮助城市规划者更好地制定规划策略,避免交通拥 塞。 尽管轨迹数据具有很重要的应用价值,但是轨迹数据的位置信息本质会带来用户 隐私泄漏问题。例如,如果轨迹数据没有处理直接发布出去,恶意攻击者可以通过背景知识 推测出用户的敏感信息,如家庭住址、工作地点、个人爱好等。同时,用户因为隐私顾虑,不 愿意去提交关于自身的轨迹数据信息,这将不利于政府以及研究人员的分析工作,相应的 应用服务质量改善也会受阻。因此,设计带有隐私保护的轨迹数据发布机制具有很重要的 意义。 目前,轨迹发布机制主要分为两类:发布单条轨迹和整个轨迹数据库。在单条轨迹 发布过程中,该轨迹中的每一个位置被看成一个记录。而在轨迹数据库发布过程中,每一条 轨迹被看成记录单位。二者的主要区别在于前者保护的是轨迹中的位置隐私,而后者保护 的是轨迹隐私。本发明的工作就是第二类轨迹数据库发布。 传统的隐私保护方法是基于分组的方式(如K-匿名,置信约束),但这些方法被发 现容易受到各种各样的攻击,如构造攻击,背景知识攻击等,因此并不能用于轨迹数据的发 布工作。 为了克服传统的隐私保护方法的缺陷,许多基于随机化的隐私保护模型被提出。 其中,差分隐私因能隔离背景知识,提供量化的隐私评估方法而成为主流的隐私保护模型。 差分隐私最早在2006被Dwork提出,它的主要思想是:单条记录存在与否对作用在数据集上 的查询的结果的影响控制在一定的范围内,同时通过概率将这种范围量化出来。通过差分 隐私保护模型,用户参与轨迹数据集的查询操作,不会泄露自身隐私。 Chen et al.首次提出基于前缀树的轨迹数据发布方式,将相同序列分组到同一 树分支,通过对树节点计数加噪满足差分隐私要求。后来,Chen et al.扩展了前缀树的工 作,采用可变长度n-gram模型去处理序列数据。Mehmet er al.通过真实轨迹的特征提取, 特征学习,噪音扰乱,来合成轨迹从达到隐私保护的效果。然而,以前工作都假定原始轨迹 包含相同的前缀或者长度为n的子序列,这种条件在现实中很难满足。 为移除以上假定,Hua et al.提出一种基于轨迹融合的一般时间序列数据发布方 式。主要是包括基于指数机制的位置泛化,以及基于拉普拉斯机制加噪的重构估计发布,因 为这两个过程都满足差分隐私,从而保证整个轨迹数据发布过程满足差分隐私。但是基于 拉普拉斯机制添加的噪音是从(-∞, ∞)取值,从而导致加噪后的轨迹计数泄漏用户隐私, 5 CN 111581662 A 说 明 书 2/15 页 同时,该发布方法轨迹融合时存在选项是移除原始轨迹得到的,降低轨迹数据可用性。为 此,Li et al.提出一种带有拉普拉斯噪音约束的轨迹融合发布方法,在轨迹融合过程中不 考虑移除原始轨迹得到的候选项,从而提高发布轨迹的有用性以及发布效率。 然而,已有工作表明,拉普拉斯机制并不是最优的加噪机制。已有工作提出一种拉 普拉斯机制的优化版本--Staircase机制,在同等隐私预算下,Staircase机制添加的噪音 量会更小。从而提高数据可用性。 通过上述分析,现有技术存在的问题及缺陷为:(1)移动设备的广泛使用使得个体 移动数据越来越容易被商家收集到。然而,如果这些移动数据处理不当,会引起隐私泄漏问 题。目前保护用户隐私的主流隐私保护模型-差分隐私,通常是添加服从拉普拉斯分布的噪 音来保护用户真实信息,存在噪音量过大问题,这会降低轨迹数据可用性。 (2)现有的基于k-means聚类的轨迹融合方法,数据处理效率较低。 (3)现有的轨迹方法假定原始轨迹包含相同的前缀或者长度为n的子序列,这种条 件在现实中很难满足。 解决以上问题及缺陷的难度为:如何有效处理高维轨迹数据;如何设计出满足差 分隐私模型的轨迹数据发布方案,以抵御各类背景知识攻击;如何提高轨迹数据发布的效 率,从而能够在实际应用中落地;如何平衡轨迹数据隐私保护与数据有用性,在提供足够强 的隐私保护下,尽可能高地提高轨迹发布的有用性。 解决以上问题及缺陷的意义为:通过设计出高效和带有差分隐私保护的轨迹数据 发布方法,有利用在服务器端实际部署;考虑到用户的隐私顾虑,有利于鼓励更多的用户提 交位置数据;政府以及相关研究机构能够接触到更多的位置数据,从而改善基于位置服务 的应用的质量。
技术实现要素:
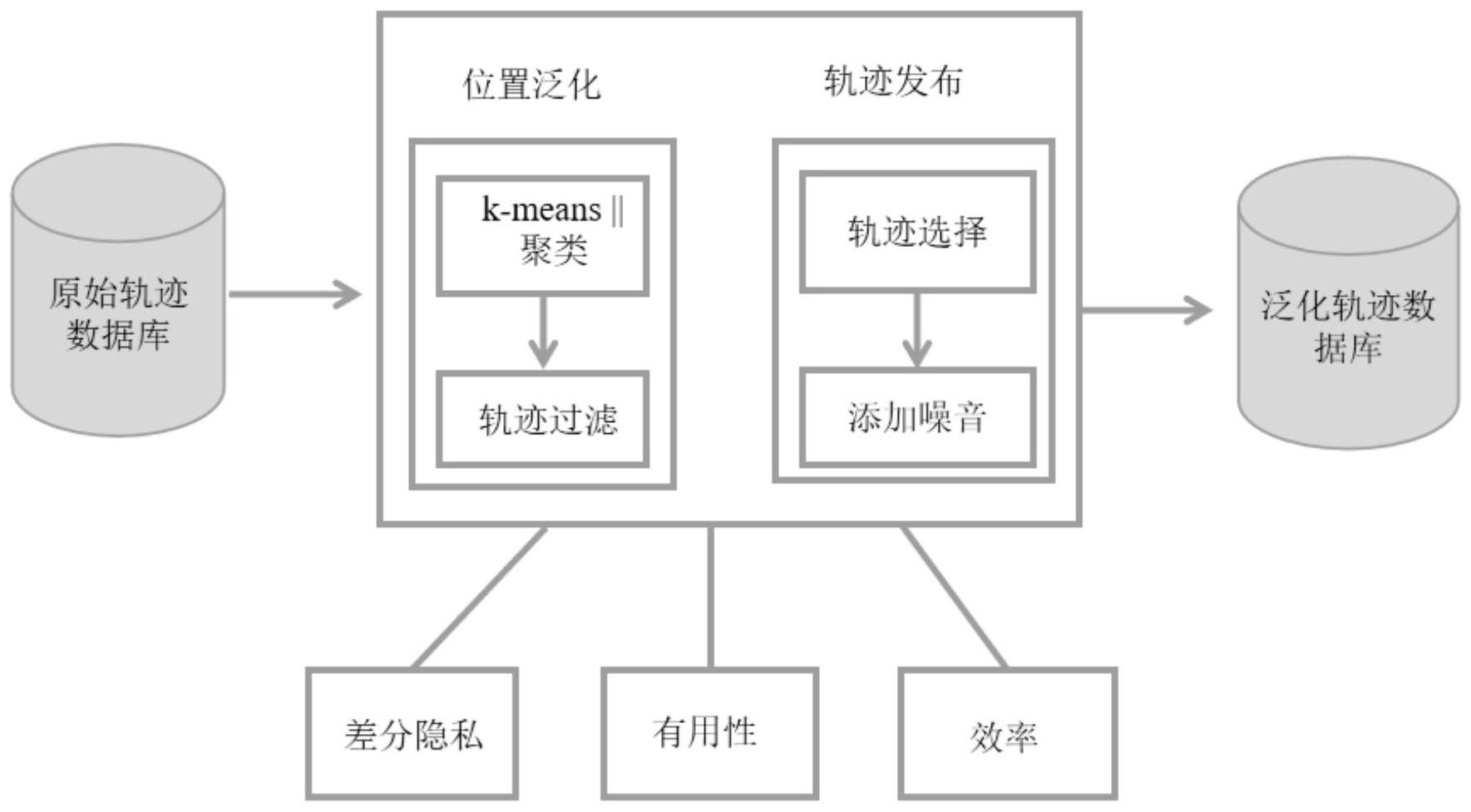
针对现有技术存在的问题,本发明提供了一种轨迹隐私保护方法、隐私保护系统、 存储介质及移动设备。 具体涉及一种基于聚类及staircase机制的轨迹隐私保护方法、轨迹隐私保护系 统、存储介质及移动设备。 本发明是这样实现的,一种轨迹隐私保护方法,包括: 步骤一,使用kmeans||聚类算法对每一时间戳下的位置进行聚类;使用k-means|| 聚类,能够缩短聚类时间,极大提高整体效率。 步骤二,连接不同时间戳下簇的中心,得到重构轨迹数据集Ω;对重构轨迹数据集 Ω进行筛选得到n条合适的重构轨迹; 步骤三,对筛选得到的n条重构轨迹进行满足差分隐私的Staiecase机制加噪,发 布重构轨迹及重构轨迹的加噪计数。 为简化问题,假定原始轨迹数据集包含8条轨迹,时间戳长度为4,如图3所示。对每 一时间戳下的位置点使用基于欧式距离度量的聚类算法进行聚类,得到不同的簇,以簇中 心代替该簇内所有的点如图4所示。对连接得到的泛化轨迹进行选择,以达到原始轨迹规 模。最后对泛化轨迹的计数加噪并发布,如表1所示。 进一步,步骤二筛选重构轨迹的方法包括: 6 CN 111581662 A 说 明 书 3/15 页 方式一,直接聚类,然后连接簇中心执行筛选过程; 方式二,聚类得到簇中心后,使用Staircse机制对簇中心进行扰乱,然后基于扰乱 后的簇中心进行轨迹重构与筛选操作。 进一步,方式二具体包括: 输入:原始轨迹数据集; 输入:原始轨迹数据集; 步骤1,遍历每一时间戳下位置集,进行k-means||聚类,使用Staircase机制分别 对簇中心进行加噪扰乱;扰乱时约束条件:如果簇心扰乱后偏离该簇范围,将簇心映射到簇 内最近点; 步骤2,基于每个时间戳下扰乱后的簇中心,执行筛选重构操作;筛选条件:任意连 接的簇中心之间的距离不大于原始轨迹中最大距离阈值。 进一步,步骤三中,对筛选得到的n条重构轨迹进行满足差分隐私的Staiecase机 制加噪的方法包括: 输入:计数阈值α=0,β,有原始轨迹经过的重构轨迹,隐私预算ε,灵敏度Δ,随机 数γ; 输出:重构轨迹及其加噪计数; (1)计算有原始轨迹经过的重构轨迹真实计数的最大值。设置阈值β=1.5*最大 值; (2)遍历有原始轨迹经过的重构轨迹: 加噪后的计数=真实计数 Staircase(Δ,γ,ε); 判断加噪后计数是否属于[0,β],如果大于β,则令其为β,如果小于0; 则令其为0; (3)遍历筛选得到的重构轨迹: 加噪后的计数=Staircase(Δ,γ,ε); 判断加噪后计数是否属于[0,β],如果大于β,则令其为β,如果小于0; 则令其为0。 进一步,步骤三中,重构轨迹发布的方法包括: 第一步,包含原始轨迹位置的泛化轨迹集 有k条轨迹;对应Noisy为原始计数基 础上噪音Lap(1/ε2);在m^s-k条泛化轨迹集中抽取适当轨迹,m是每个时刻分组数,s是时间 戳长度,同时发布相应Noisy,Noisy=0 Lap(1/ε2); 第二步,对 的噪音计数排序,即C1>C2>…>Ck,抽取到的轨迹对应的Noisy都是 在上面的小区间里;Noisy取值在对应区间,应抽取的轨迹数为Numi,i∈[1,k];Noisy取值 在对应区间的概率分别 有如下表达式: 进一步,步骤三中,差分隐私的Staiecase机制包括:在位置泛化阶段没有扰乱,重 7 CN 111581662 A 说 明 书 4/15 页 构发布算法满足ε2-差分隐私;具体包括: D和D'是一对邻近轨迹数据集,不同的那条轨迹表示为Tx; 表示重构轨迹数据集 中轨迹Tx对应的泛化轨迹;则从序列nci(D)输出候选项r={r1,r2,...,rΩ}的概率为: 包括以下三种概率: 概率1:对于任何泛化轨迹 得到Pr[nci(D)=ri]=Pr[nci(D')=ri]; 概率2:对于任何 的加噪计数等于它的真实计数加上 Staircase噪音, 概率3:对于任何 的加噪计数为添加Staircase噪音,得 到 进一步,步骤三中,差分隐私的Staiecase机制进一步包括扰乱过程体现在位置泛 化中簇心扰动与重构估计发布中计数扰动,单时间戳下差分位置泛化过程满足ε1-差分隐 私;具体包括: D和D'是一对邻近轨迹数据集,不同的那条轨迹表示为Tx;单个位置点存在与否对 聚类结果的影响非常小,单个时间戳下聚类得到簇为ci(i=1,..,m),令 为Tx对应的簇心, 对簇心进行扰乱包括: 1):对于任何 Pr[ci(D)→c']=Pr[ci(D')→c']; 2):对于 进一步,步骤三中,差分隐私的Staiecase机制进一步包括整个轨迹发布过程满足 |T|·ε1 ε2-差分隐私;位置泛化算法M1输出序列r1,重构发布算法M2输出序列r2,则经过算 法M1与算法M1处理后得到序列r的概率为 Pr[M(D)=r]=Pr[M1(D)=r1]·Pr[M2(D)=r2]; 整个机制在领接轨迹数据集D和D'上的隐私分析为 8 CN 111581662 A 说 明 书 5/15 页 本发明的另一目的在于提供一种接收用户输入程序存储介质,所存储的计算机程 序使电子设备执行所述轨迹隐私保护方法,包括下列步骤: 步骤I,使用kmeans 聚类算法对每一时间戳下的位置进行聚类; 步骤II,连接不同时间戳下簇的中心,得到重构轨迹数据集Ω;对重构轨迹数据集 Ω进行筛选得到n条合适的重构轨迹; 步骤III,对筛选得到的n条重构轨迹进行满足差分隐私的Staiecase机制加噪,发 布重构轨迹及重构轨迹的加噪计数。 本发明的另一目的在于提供一种存储在计算机可读介质上的计算机程序产品,包 括计算机可读程序,供于电子装置上执行时,提供用户输入接口以实施所述轨迹隐私保护 方法。 本发明的另一目的在于提供一种执行所述轨迹隐私保护方法的移动设备。 结合上述的所有技术方案,本发明所具备的优点及积极效果为: (1)不需要假定原始轨迹具有相同的前缀或者子序列,在实际应用中,更加符合实 际情况; (2)基于差分隐私模型发布轨迹数据,能够抵御背景知识攻击,为用户轨迹数据提 供可靠的隐私保护; (3)对原始的轨迹数据扰动较小,发布的泛化轨迹数据集具有较高的应用机制; (4)系统运行效率性能较以往工作作出大幅度提升,在实际应用中更容易落地。 本发明对轨迹融合过程进行改进,提出两种基于K-means||聚类的改进轨迹融合 方法,提高轨迹融合效率与数据有用性。本发明对重构轨迹计数加噪机制进行改进,提出一 种改进Staircase机制的计数加噪方式,实现更小的误差,提高轨迹数据发布的有用性。在 真实轨迹数据集进行实验,从数据有用性与效率两方面对比本发明提出的机制与传统工 作。实验结果表明,本发明提出的发布机制效率更高、数据可用性更好。本发明提出的两种 一般时间序列重构方法能够提供更高的数据有用性,时间效率更高。 本发明相比于现有技术,对比的技术效果或者实验效果有:从数据有用性与系统 运行效率两方面,与已有的工作INFOCOM15和IS17进行对比。 为了综合评价所提方法的性能,本发明分别改变了隐私预算和分组数。本发明选 择的隐私预算为0.5和1.5,组数为10、20、30、40、50、60、70、80。从图5和图6可以看出,本发 明提出的两种方案的Hausdorff距离大多小于INFOCOM15和IS17,说明NPCG和PCG的数据效 用更高。本发明注意到PCG的效用高于本发明的NPCG,这与前面的分析不一致。这可能与分 配的少量隐私预算有关。在NPCG中,偏离簇范围的点被映射到簇中最近的点,这提高了数据 的有用性。 本发明改变隐私预算(选择0.5和1.0)和位置区域的分组数目(本发明选择10,20, 30、40、50、60、70、80)。为了一个更全面的比较,本发明选择了四种带有不同半径的查询框, 9 CN 111581662 A 说 明 书 6/15 页 随机运行超过500次,选择平均作为最终结果。如图7和图8所示,在不同的查询半径和组数 下,本发明提出的两种方案的数据效用总是高于IS17和INFOCOM15。由于上面提到的原因, PCG提供了比NPCG更高的数据实用程序,在比较机制中执行性能最好。此外,本发明注意到 F1-measure,即,数据有用性,会随着组的数量增加而增加。由于分组数量越大,被合并相同 分组的轨迹会越来越少,数据精度损失会越来越少,因此数据有用性会随着分组数量的增 加而增加。 本发明首先看的是在不同组数和隐私预算的情况下,NPCG和PCG的平均噪声产生 时间。本发明选择的组数为10、20、30、40、50、60、70、80,隐私预算是0.1,0.5 1.0,1.5 2.0. 通过对系统模型的分析可知,NPCG的噪声产生时间主要体现在基于约束Stiarcase噪声的 轨迹计数数扰动中,而PCG则体现在质心扰动和轨迹计数扰动中,这意味着PCG的扰动过程 更加复杂。如图9和图10所示,PCG的时间成本要高得多。本发明可以注意到,随着隐私预算 的增加,产生噪音的时间会减少。由于隐私预算越大,添加的噪声越少,因此隐私保护水平 越低。 这里描述了在不同隐私预算0.5,1.0,1.5,2.0与不同分组情况下平均轨迹融合时 间。结果如图11和图12所示。与噪声产生过程相似,PCG的平均轨迹生成时间比NPCG要长。本 发明也注意到轨迹生成的时间成本随着群组数量的增加而增加,但是随着隐私预算的增加 而保持稳定。实际上,对比图9和图11或图10和图12,本发明可以发现,本发明提出的方法的 总时间成本主要由聚类工作决定。 最后,本发明比较了本发明提出的机制和INFOCOM15,IS17的时间。本发明改变分 组的数量(本发明选择10、20、30、40、50、60、70、80),并查看平均生成时间的时间成本如何 变化。本发明工作与INformcom15与IS17做比较。在INFOCOM15中,位置泛化过程中使用指数 机制筛选 不同划分情况。因为s中划分情况是通过每次移除一条原始估计聚类的得 到的,这将破坏数据的可用性,IS17中移除这s种情况。本发明设置 s=10。如图13和图 14所示,在隐私预算为0.1时,本发明提出轨迹发布机制NPCG较工作INFOCOM15运行时间减 少了85%到94%,较工作IS17运行时间减少了70%到92%。在隐私预算为0.5时,NPC发布方 案较INFOCOM15减少了82%到98%,较IS17减少里75%到95%。同时,比较NPCG和PCG的运行 时间,发现在隐私预算为0.1时,PCG较NPCG要多出30%的时间,在隐私预算为0.5时,PCG较 NPCG要多出42%的时间。 附图说明 图1是本发明实施例提供的基于聚类及staircase机制的轨迹隐私保护方法流程 图。 图2是本发明实施例提供的基于聚类及staircase机制的轨迹隐私保护方法原理 图。 图3是本发明实施例提供的原始轨迹数据集图。 图4是本发明实施例提供的轨迹聚类图。 图5本发明实施例提供的两种方法的豪斯托夫距离(epsilon=0.5)。 图6本发明实施例提供的两种方法的豪斯托夫距离(epsilon=1.0)。 图7本发明实施例提供的两种方法的的F1-measure(epsilon=0.5)。 10 CN 111581662 A 说 明 书 7/15 页 图8本发明实施例提供的两种方法F1-measure(epsilon=1.0)。 图9本发明实施例提供思路1的平均噪音生成时间(NPCG)。 图10本发明实施例提供思路2的平均噪音生成时间(PCG)。 图11本发明实施例提供思路1的平均轨迹生成时间(NPCG)。 图12本发明实施例提供思路2的平均轨迹生成时间(PCG)。 图13本发明实施例提供的两种思路的平均轨迹生成时间比较(epsilon=0.1)。 图14本发明实施例提供的两种思路的平均轨迹生成时间比较(epsilon=0.5)。 图15本发明实施例提供的两种思路的互信息(epsilon=0.5)。 图16本发明实施例提供的两种思路的互信息(epsilon=1.5)。











