
技术摘要:
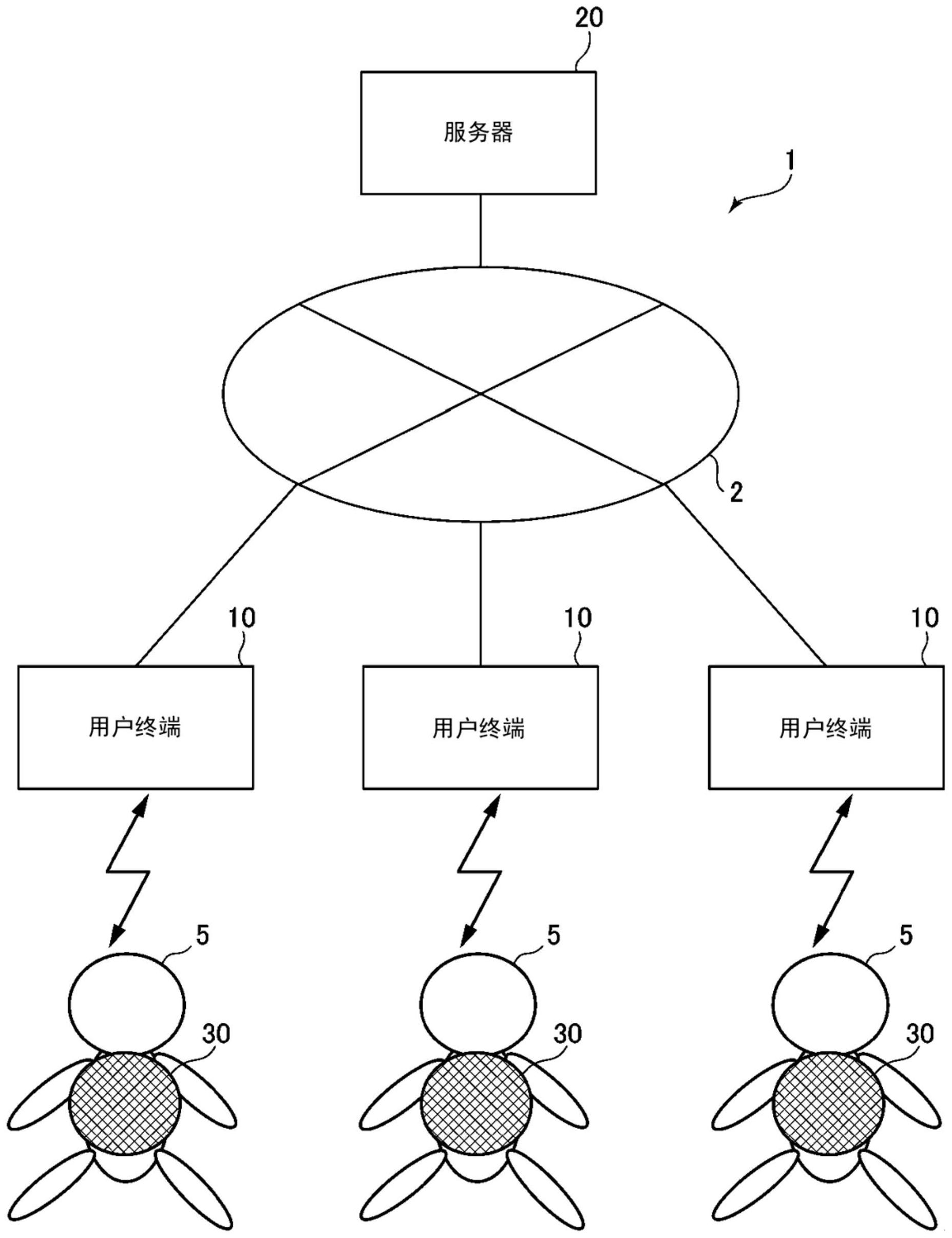
本发明提供声音数据提供系统、用户终端、记录介质、输出装置,能够提高应用程序的趣味性。声音数据提供系统包括用户终端、服务器、能够与用户终端进行通信的输出装置,服务器具备存储多个声音数据的存储单元,用户终端具备:显示单元,显示与多个声音数据中的任一个声 全部
背景技术:
近年来,作为以智能手机等为代表的小型的电子装置的用户终端迅速地普及,还 提供了很多在这种用户终端上执行的游戏等应用程序(application)。已知如下一种系统: 在这种应用程序中,通过被称为所谓的扭蛋的抽选处理,来向用户提供如游戏中使用的卡 片那样的在应用程序中使用的应用程序介质。在通过抽选处理进行的选择中,有时向用户 多次提供相同的卡片。在这种情况下,已知的是通过将相同的卡片进行合成,来改变卡片的 能力值(专利文献1)。 现有技术文献 专利文献 专利文献1:日本特开2018-114356号
技术实现要素:
发明要解决的问题 在上述应用程序中,通过将卡片进行合成来改变卡片的能力值,由此即使在通过 抽选获取了多个相同的卡片的情况下,也能够有效地使用所获取到的卡片,因此用户能够 维持进行抽选的动机。然而,在通过合成而不能改变能力值的声音数据的情况下,即使通过 抽选获取了相同的声音数据,也无法对用户提供新的价值。因此,特别是在付费进行抽选的 情况下,当提供与已经拥有的声音数据相同且没有新的利用价值的声音数据时,担心妨碍 用户对应用程序的趣味性。 本发明是为了解决这种问题而完成的,其主要目的在于提供一种能够提高应用程 序的趣味性的系统等。 用于解决问题的方案 作为本发明的一个方式的系统是一种声音数据提供系统,包括用户终端、能够与 用户终端进行通信的服务器以及能够与用户终端进行通信的输出装置,其中,服务器具备: 存储单元,其存储多个声音数据;以及通信单元,其向用户终端发送声音数据,用户终端具 备:显示单元,其显示与多个声音数据中的任一声音数据绑定的一个以上的声音数据选择 区域;输入单元,其受理由用户进行的从所述一个以上的声音数据选择区域中选择一个声 音数据选择区域的选择输入;以及通信单元,其从服务器接收与由用户选择的声音数据选 择区域绑定的声音数据即已选择的声音数据,并将所接收到的声音数据发送到输出装置, 输出装置具备:通信单元,其接收从用户终端发送的声音数据;以及声音输出单元,其基于 所接收到的声音数据来输出声音,在所述一个以上的声音数据选择区域中,构成为不对所 述一个以上的声音数据选择区域绑定相同的声音数据。 5 CN 111596884 A 说 明 书 2/13 页 另外,用户终端能够还具备控制单元,所述控制单元使得不能再次选择用户已经 选择过的声音数据选择区域。 并且,也可以是,通过抽选处理来决定对所述一个以上的声音数据选择区域绑定 的声音数据。 能够构成为,当选择了声音数据选择区域时,再次决定对所述一个以上的声音数 据选择区域绑定的声音数据。 所述显示单元能够以使用户无法识别出对一个以上的声音数据选择区域绑定的 声音数据的方式,来显示声音数据选择区域。 所述显示单元能够显示多个声音数据选择区域,并将已经选择过的声音数据选择 区域与其它的声音数据选择区域以不同的方式进行显示。 也可以是,所述显示单元将已经选择过的声音数据选择区域呈现为已选择,将其 它的声音数据选择区域呈现为未选择。 也可以是,所述显示单元显示多个声音数据选择区域,所述显示单元将与已选择 的声音数据绑定的声音数据选择区域呈现为用于在输出装置中输出基于该已选择的声音 数据的声音的选择区域,将与其它的声音数据绑定的声音数据选择区域呈现为用于获取声 音数据的选择区域。 也可以是,服务器判定对所选择的声音数据选择区域绑定的声音数据是否以用户 能够利用的状态存储于服务器的存储单元,在判定为以能够利用的状态存储的情况下,服 务器的通信单元将所述声音数据发送到用户终端。 服务器的存储单元能够以包含一个以上的声音数据的一个组的形式进行存储。 也可以是,将表示规定的角色的角色识别信息与各组进行绑定,各组中包含的声 音数据为与对该组绑定的角色识别信息所表示的角色相关联的声音数据。 声音数据能够为对该声音数据的组绑定的角色识别信息所表示的角色的台词数 据。 能够形成为,在第一组的所有的声音数据成为已选择的情况下,将所述一个以上 的声音数据选择区域与其它组的声音数据进行绑定。 也可以是,所述输出装置还具备存储输出装置识别信息的存储单元,该输出装置 识别信息用于识别对该输出装置绑定的角色,所述输出装置的通信单元发送所述输出装置 识别信息,所述用户终端基于所述输出装置识别信息,不将除该输出装置所绑定的角色以 外的角色识别信息绑定的组中包含的声音数据发送到所述输出装置。 在执行了规定的对价支付处理的情况下,所述显示单元能够将通过执行对价支付 处理而被设为能够选择的一个以上的声音数据选择区域以能够选择的方式进行显示。 也可以是,所述多个声音数据包括仅在规定期间内与声音数据选择区域绑定的声 音数据。 所述服务器的存储单元能够将第一价值信息或第二价值信息以与所述多个声音 数据中的各个声音数据进行绑定的方式存储,并将与第一价值信息绑定的声音数据存储得 比与第二价值信息绑定的声音数据多,其中,该第二价值信息表示比第一价值信息的价值 高的价值。 能够形成为,所述一个以上的声音数据选择区域为多个声音数据选择区域,包括 6 CN 111596884 A 说 明 书 3/13 页 与一个声音数据绑定的声音数据选择区域以及与多个声音数据绑定的声音数据选择区域。 作为本发明的一个方式的用户终端具备:显示单元,其显示与多个声音数据中的 任一声音数据绑定的一个以上的声音数据选择区域;输入单元,其受理由用户进行的从所 述一个以上的声音数据选择区域中选择一个声音数据选择区域的选择输入;以及通信单 元,其从服务器接收与由用户选择的声音数据选择区域绑定的声音数据即已选择的声音数 据,并将所接收到的声音数据发送到输出装置,其中,在所述一个以上的声音数据选择区域 中,构成为不对所述一个以上的声音数据选择区域绑定相同的声音数据。 作为本发明的一个方式的程序是一种由用户终端执行的程序,该程序用于使所述 用户终端作为以下单元发挥功能:显示单元,其显示与一个以上的声音数据中的任一声音 数据绑定的一个以上的声音数据选择区域;输入单元,其受理由用户进行的从所述一个以 上的声音数据选择区域中选择一个声音数据选择区域的选择输入;以及通信单元,其从服 务器接收与由用户选择的声音数据选择区域绑定的声音数据即已选择的声音数据,并将所 接收到的声音数据发送到输出装置,其中,在所述一个以上的声音数据选择区域中,构成为 不对所述一个以上的声音数据选择区域绑定相同的声音数据。 作为本发明的一个方式的输出装置是具备接收声音数据的通信单元和声音输出 单元的输出装置,其中,所述通信单元从用户终端接收与在用户终端中由用户选择的声音 数据选择区域绑定的声音数据即已选择的声音数据,所述声音输出单元能够仅输出基于所 接收到的所述声音数据的声音。 当所述通信单元接收到多个声音数据时,所述声音输出单元能够将基于所接收到 的所述多个声音数据的声音以规定的时间差输出。 也可以是,所述输出装置为模仿出规定形象的玩具体,构成为能够安装于布制玩 偶。 发明的效果 根据本发明,能够避免向用户提供相同的声音数据,从而能够提高应用程序的趣 味性。 附图说明 图1是本发明的一个实施方式所涉及的系统的整体结构。 图2是本发明的一个实施方式所涉及的系统的硬件结构图。 图3是本发明的一个实施方式所涉及的系统的功能框图。 图4是本发明的一个实施方式所涉及的应用程序画面的一例。 图5是示出本发明的一个实施方式所涉及的处理的流程图。 图6是本发明的一个实施方式所涉及的应用程序画面的一例。 图7是本发明的一个实施方式所涉及的应用程序画面的一例。 图8是本发明的一个实施方式所涉及的应用程序画面的一例。 图9是示出本发明的一个实施方式所涉及的处理的流程图。 附图标记说明 1:声音数据提供系统;2:网络;5:玩具;10:用户终端;11:处理器;12:显示装置; 13:输入装置;14:存储装置;15:通信装置;16:总线;20:服务器;21:处理器;22:显示装置; 7 CN 111596884 A 说 明 书 4/13 页 23:输入装置;24:存储装置;25:通信装置;26:总线;30:输出装置;31:处理器;32:声音输出 装置;34:存储装置;35:通信装置;36:总线;40、60、80:声音数据管理画面;101:控制单元; 102:显示单元;103:输入单元;104:存储单元;105:通信单元;201:控制单元;202:显示单 元;203:输入单元;204:存储单元;205:通信单元;301:控制单元;302:声音输出单元;304: 存储单元;305:通信单元。











