
技术摘要:
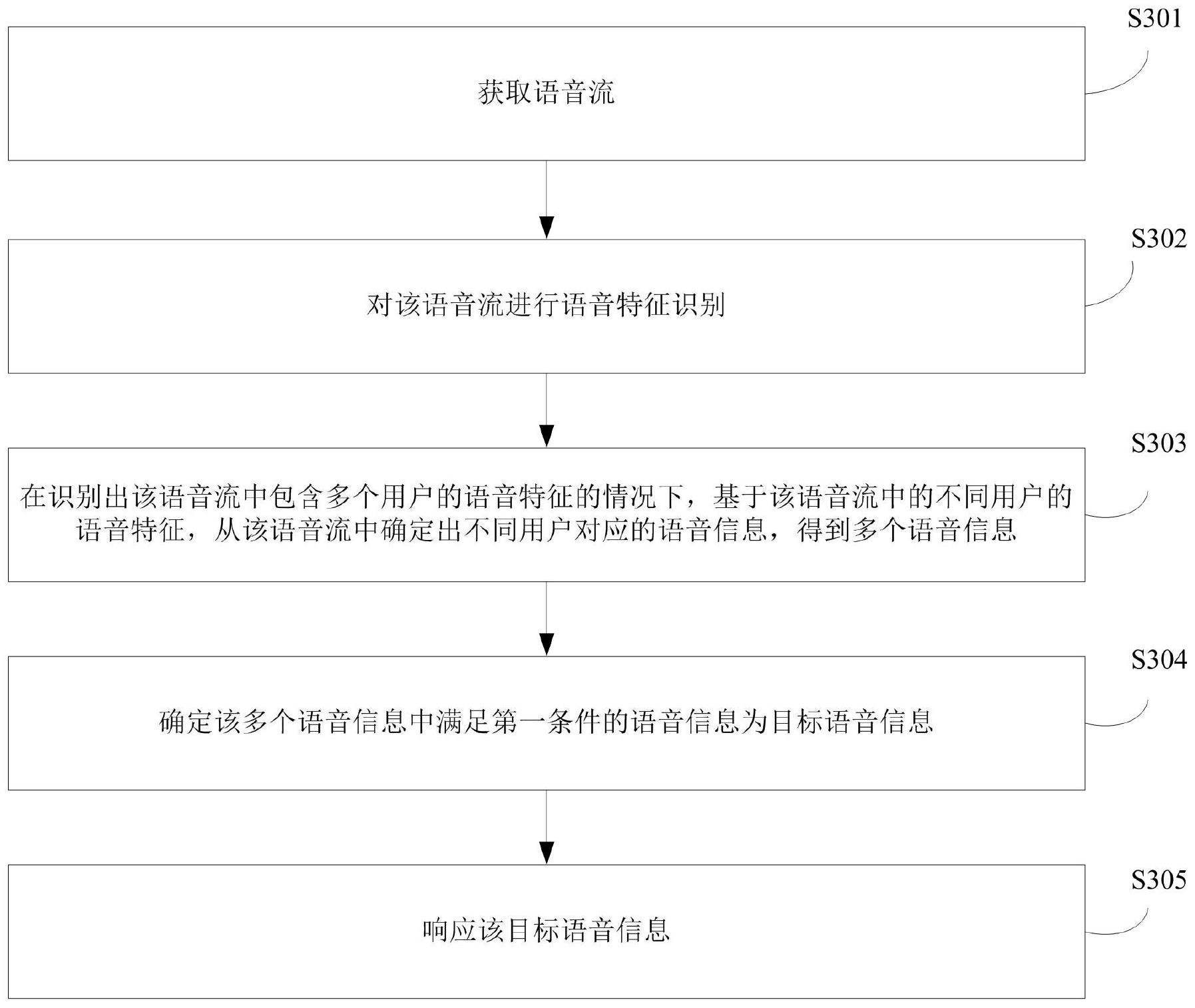
本申请公开了一种语音处理方法和装置,该方法包括:获取语音流;对语音流进行语音特征识别;在识别出语音流中包含多个用户的语音特征的情况下,基于语音流中的不同用户的语音特征,从语音流中确定出不同用户对应的语音信息,得到多个语音信息;确定多个语音信息中满足 全部
背景技术:
随着技术的不断发展,用户通过语音控制电子设备已经十分普遍。如,安装有语音 助手等语音处理软件的智能音箱,可以检测用户输入的语音,并确定该语音所指示的指令 并执行。 但是现有的语音助手在环境音复杂的场景下(如接收用户指令的同时还有其他人 在说话),很容易发生响应失败的问题。
技术实现要素:
为实现上述目的,本申请提供了一种语音处理方法和装置。 其中,一种语音处理方法,包括: 获取语音流; 对所述语音流进行语音特征识别; 在识别出所述语音流中包含多个用户的语音特征的情况下,基于所述语音流中的 不同用户的语音特征,从所述语音流中确定出不同用户对应的语音信息,得到多个语音信 息; 确定所述多个语音信息中满足第一条件的语音信息为目标语音信息; 响应所述目标语音信息。 优选的,所述确定所述多个语音信息中满足第一条件的语音信息为目标语音信 息,包括: 确定所述多个语音信息中包含有可执行的语音指令的语音信息为目标语音信息。 优选的,所述确定所述多个语音信息中满足第一条件的语音信息为目标语音信 息,包括: 确定所述多个语音信息中用于向语音识别设备输入语音指令的语音信息为目标 语音信息。 优选的,所述确定所述多个语音信息中用于向语音识别设备输入语音指令的语音 信息为目标语音信息,包括: 对所述多个语音信息中每个语音信息进行语义识别;根据所述语音信息的语义识 别结果,确定所述语音信息是否为用于向语音识别设备输入的语音指令;确定所述多个语 音信息中用于向语音识别设备输入语音指令的语音信息为目标语音信息; 和/或,确定所述多个语音信息中包含有唤醒词的语音信息为目标语音信息; 和/或,基于对所述多个语音信息的语义识别,确定所述多个语音信息之间的语义 关联关系;基于所述多个语音信息之间的语义关联关系,确定所述语音信息与所述多个语 音信息中的其他语音信息之间是否存在语句问答关系,并将与其他语音信息之间不存在语 4 CN 111583956 A 说 明 书 2/16 页 句问答关系的语音信息确定为目标语音信息; 和/或,确定所述语音信息所归属的用户是否关联有用户信息库;如所述语音信息 所归属的用户关联有用户信息库,结合所述语音信息的语义识别结果和所述用户信息库, 从所述多个语音信息中确定用于向语音识别设备输入语音指令的目标语音信息。 优选的,所述响应所述目标语音信息,包括: 在确定出所述目标语音信息包含有可执行的语音指令的情况下,响应所述目标语 音信息对应的语音指令。 优选的,所述确定所述多个语音信息中包含有可执行的语音指令的语音信息为目 标语音信息,包括: 识别所述多个语音信息中每个语音信息的语义; 根据所述语音信息的语义,确定语音指令库中与所述语音信息存在相关性的至少 一个语音指令以及所述语音信息与每个所述语音指令的相关程度; 在所述语音指令库中存在与所述语音信息的相关程度超过设定阈值的至少一个 语音指令的情况下,将所述超过设定阈值的至少一个语音指令确定为所述语音信息关联的 目标语音指令; 确定所述多个语音信息中关联有目标语音指令的语音信息为目标语音信息。 优选的,所述对所述语音流进行语音特征识别,包括: 对所述语音流进行声纹识别; 所述在识别出所述语音流中包含多个用户的语音特征的情况下,基于所述语音流 中的不同用户的语音特征,从所述语音流中确定出不同用户对应的语音信息,包括: 在识别出所述语音流中包含多个用户的声纹特征的情况下,基于所述语音流中的 不同用户的声纹特征,从所述语音流中确定出不同用户对应的语音信息。 优选的,所述获取语音流,包括: 响应于接收到的包含唤醒词的语音信号,获取语音流; 所述确定所述多个语音信息中满足第一条件的语音信息为目标语音信息,包括: 将所述多个语音信息中,语音特征与所述语音信号的语音特征相同的语音信息确 定为目标语音信息。 优选的,所述在识别出所述语音流中包含多个用户的语音特征的情况下,基于所 述语音流中的不同用户的语音特征,从所述语音流中确定出不同用户对应的语音信息,包 括: 在识别出所述语音流中包含多个用户的语音特征的情况下,根据语音流中不同用 户的语音特征以及所述语音流中不同用户的语音特征对应的起始时刻点和结束时刻点,从 所述语音流中确定出对应的语音信息。 其中,一种语音处理装置,包括: 语音流获取单元,用于获取语音流; 特征识别单元,用于对所述语音流进行语音特征识别; 语音提取单元,用于在识别出所述语音流中包含多个用户的语音特征的情况下, 基于所述语音流中的不同用户的语音特征,从所述语音流中确定出不同用户对应的语音信 息,得到多个语音信息; 5 CN 111583956 A 说 明 书 3/16 页 目标确定单元,用于确定所述多个语音信息中满足第一条件的语音信息为目标语 音信息; 语音响应单元,用于响应所述目标语音信息。 通过以上方案可知,本申请会对获取到的语音流进行语音特征识别,由于不同用 户的语音特征不同,因此,在识别出语音流中包含多个用户的语音特征的情况下,可以基于 语音流中不同用户的语音特征,确定出该语音流中不同用户的语音信息。在此基础上,通过 响应该多个用户对应的多个语音信息中满足条件的目标语音信息,从而实现了对语音流中 满足条件的语音信息进行响应,减少了由于语音流中语音信息复杂而导致无法响应或者无 法准确响应语音指令的情况。 附图说明 为了更清楚地说明本申请实施例中的技术方案,下面将对实施例描述中所需要使 用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于 本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他 的附图。 图1为本申请实施例提供的语音处理方法所适用的一种场景架构示意图; 图2为本申请实施例提供的语音识别设备的一种组成结构示意图; 图3为本申请实施例提供的语音处理方法的一种实现流程示意图; 图4为本申请实施例提供的语音处理方法的又一种实现流程示意图; 图5为本申请实施例提供的语音处理方法的再一种实现流程示意图; 图6为本申请实施例提供的语音处理方法的再一种实现流程示意图; 图7为本申请实施例提供的语音处理方法在一种应用场景中的实现流程示意图; 图8为本申请实施例提供的语音处理装置的一种组成结构示意图。 说明书和权利要求书及上述附图中的术语“第一”、“第二”、“第三”“第四”等(如果 存在)是用于区别类似的部分,而不必用于描述特定的顺序或先后次序。应该理解这样使用 的数据在适当情况下可以互换,以便这里描述的本申请的实施例能够以除了在这里图示的 以外的顺序实施。











