
技术摘要:
本发明提出了一种基于可配置解析字段的流识别装置及方法,属于网络通信技术领域。本发明根据现有的解析图模型,用户在运行时指定解析图的一种,通过TCAM和RAM实现的解析表来根据当前状态及输入产生一个新的状态输出,实现数据包头的解析,主要用于解决现有流分类算法中 全部
背景技术:
随着互联网技术的不断发展和网络用户急剧增加,产生了大量的数据信息。数据 流是实时的、连续的、有序项的序列,数据流识别模块在网络处理器芯片/交换芯片/交换机 中有着重要的地位,其主要作用在于区分数据流。数据流识别模块根据数据包头中的信息 对数据流进行区分,进而根据不同的需要进行工作。数据流识别模块主要包括数据解析和 流表匹配等模块,其性能直接关系到网络处理器芯片/交换芯片/交换机的效率,也是能否 满足用户需求的关键。 对于数据包头中的信息字段的解析是流识别技术的开始,也是比较关键的一步, 对数据包头的解析主要有包头识别和字段提取两个部分。包头识别是指根据不同协议规定 的包头格式和长度识别出包头的序列,这个序列可以描述为一个解析图,不同应用场景中 的解析图可能是完全不同的;字段提取是指根据包头识别的结果提取有用的字段来进行数 据流的分类。 目前,对于数据包头中的字段解析是比较固定的,受协议限制,而且只适用于某种 特定应用场景的一个解析图。例如,专利“一种适用于多类字段的高速数据流分类装置及方 法”所述可以实现多类字段的高速数据流识别及分类,对于数据流预处理模块,按照用户定 义的所有匹配字段的属性,提取数据流中的关键信息并输出,包头解析要尽可能地提取出 所有相关的字段,然后进行匹配,这样不仅不够灵活,而且不能称之为协议无关。这种方式 对于包头字段的解析中,只是将一种特定的解析图的包头序列进行编码,然后通过窗口过 滤提取,这样提取到的字段长度宽度固定,顺序固定,而且不能适应新增的协议字段。
技术实现要素:
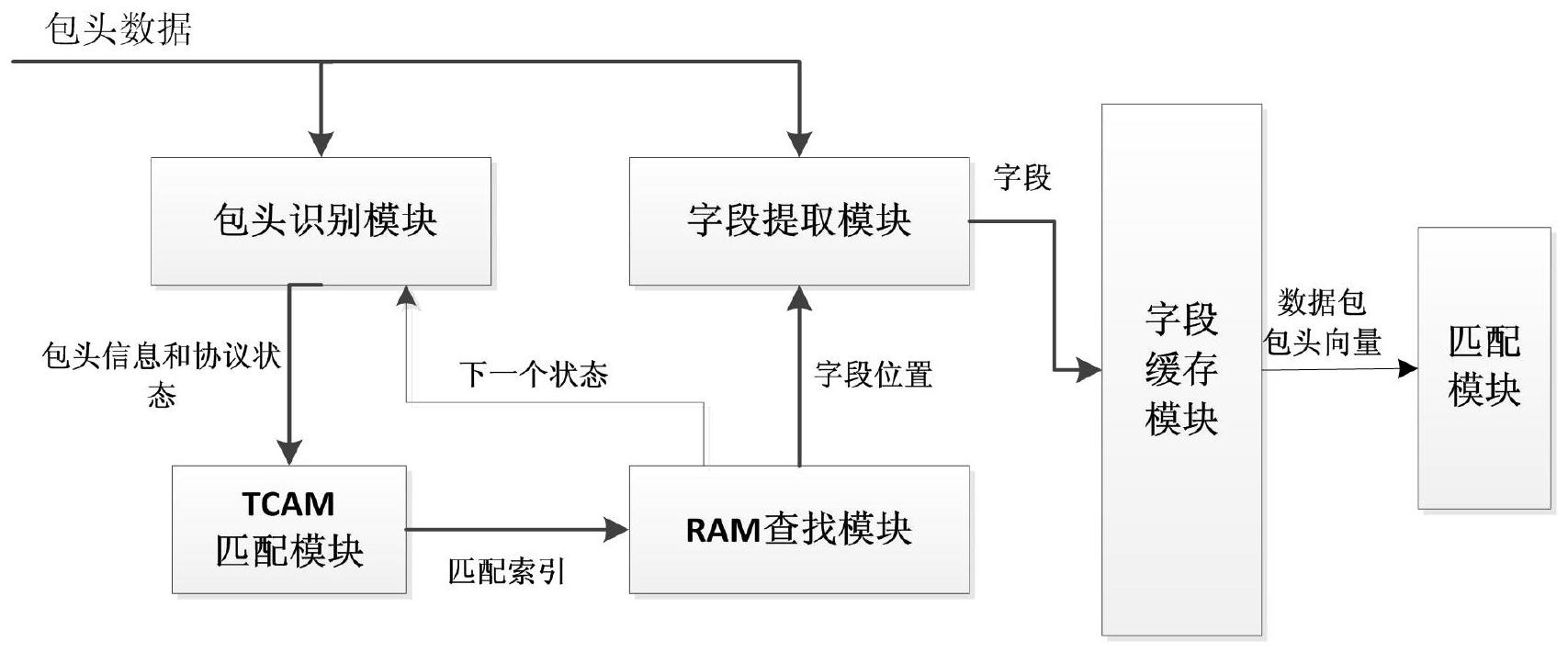
本发明的所要解决技术问题在于更改可配置,提出了一种基于可配置解析字段的 流识别装置及方法,解决现有技术流表数量固定、字段宽度固定、执行顺序固定和不易扩展 等问题。 为实现上述目的,本发明采取的技术方案为: 一种基于可配置解析字段的流识别装置,包括包头识别模块、TCAM匹配模块、RAM 查找模块、字段提取模块以及字段缓存模块; 包头识别模块,用于提取当前状态数据包的包头信息和协议状态,并将提取的信 息发送给TCAM匹配模块;还用于在接收到RAM查找模块输出的下一状态后,将下一状态作为 当前状态,提取当前状态数据包的包头信息和协议状态,并将提取的信息发送给TCAM匹配 模块; 4 CN 111600796 A 说 明 书 2/5 页 TCAM匹配模块,用于根据不同的应用场景需求,用户配置不同的流分类配置规则 表,并根据流分类配置规则表,将接收到的当前状态数据包的包头信息和协议状态进行匹 配,生成匹配索引,并将匹配索引作为RAM查找模块的索引地址发送至RAM查找模块; RAM查找模块,用于通过节点集群合并的方式根据用户需求配置相应的存储条目, 并根据TCAM匹配模块输出的索引地址查询内部存储条目,将查询的下一状态发送给包头识 别模块,并将当前状态数据包的包头协议和包头位置信息发送给字段提取模块;其中,存储 条目是合并条目,包括多个当前状态数据包的包头协议和包头位置信息以及对应的下一状 态数据包的包头协议和包头位置信息; 字段提取模块,用于根据RAM查找模块发来的包头协议和包头位置信息从接收的 数据包中提取当前状态数据包的字段信息,提取到对应的字段信息后存储至字段缓存模 块;字段信息包括目的MAC、源MAC、目的IP、源IP、目的端口和源端口信息; 字段缓存模块,用于存储当前状态数据包的字段信息,当前状态数据包的所有字 段信息提取完毕后,将提取信息输出至匹配模块进行流表匹配。 其中,包头识别模块包括第一缓存模块和第一状态机; 第一缓存模块用于接收不同状态的数据包并缓存,提取当前状态数据包的包头信 息发送至TCAM匹配模块;并接收第一状态机输出的下一状态数据包的包头类型,将下一状 态作为当前状态,提取当前状态数据包的包头信息发送至TCAM匹配模块; 第一状态机用于将内部存储的所有数据包的包头协议类型编码为若干个协议状 态,初始状态是当前状态数据包的包头,将当前状态数据包的协议状态输出至TCAM匹配模 块;并根据RAM查找模块输入的下一状态进行跳转,将下一状态数据包的包头类型输出至第 一缓存模块。 其中,字段提取模块包括第二缓存模块、第二状态机和两个选择器; 第二状态机用于根据RAM查找模块输出的当前状态数据包的包头协议和包头位置 信息进行跳转,跳转时根据上一状态数据包的包头位置信息,将包头识别的起始移动到当 前要识别的包头位置,并控制第二缓存模块输出当前状态数据包的字段信息; 第二缓存模块用于接收数据包并进行缓存,在第二状态机的控制下输出当前状态 数据包的字段信息; 两个选择器用于根据RAM查找模块输出的包头位置信息打开对应的选择器,将第 二缓存模块输出的字段信息输出至字段缓存模块。 一种基于可配置解析字段的流识别方法,包括如下步骤: (1)接收数据包,识别当前状态数据包的包头信息和协议状态; (2)根据当前状态数据包的包头信息和协议状态生成匹配索引; (3)将匹配索引作为索引地址,根据索引地址查询存储条目,触发下一状态数据包 的识别,将下一状态数据包作为当前状态数据包,返回步骤(1),同时,根据当前状态数据包 的包头协议和包头位置信息从接收的数据包中提取对应的字段信息,并进行存储; (4)当前状态数据包的所有字段提取完毕后,将提取信息输出进行流表匹配。 本发明与现有技术相比,具有如下优点: 第一,本发明在包识别和字段提取模块中消除了针对特定包头类型的所有硬编码 逻辑,而由TCAM匹配模块和RAM查找模块中的数据指导这些模块的操作,实现可配置解析。 5 CN 111600796 A 说 明 书 3/5 页 因此本发明生成的流表数量、拓扑、宽度和深度都是可配置的。 第二,本发明将识别标头类型和长度所需的数据发送到RAM查找模块,为了实现巨 大解析图拓扑结构的状态存储,需要很多条目,为了优化RAM条目,采用节点集群合并的方 式,有效地减少了RAM条目,降低了存储资源的使用。 第三,本发明可以改善整体的数据流识别架构,即可以通过修改解析器来添加新 字段,从而后续的匹配过程可以通过修改匹配模块来匹配新字段,通过修改阶段指令来应 用新动作,以及通过修改排队规则来进行新排队。克服了现有方案只能完成特定字段提取 的缺点,进一步扩大了数据流识别的使用范围。 附图说明 图1为本发明实施例中装置的整体结构示意图; 图2为本发明实施例中包头识别过程示意图; 图3为本发明实施例中字段提取过程示意图。











