
技术摘要:
本发明公开了一种面向深度强化学习模型的特征过滤防御方法,包括:(1)针对生成连续行为的DDPG模型,包括actor网络和critic网络,其中,所述actor网络包括动作估计网络和动作实现网络,所述critic网络包括状态估计网络和状态实现网络,对所述深度强化学习模型DDPG进行预 全部
背景技术:
随着人工智能技术的迅速发展,越来越多的领域都开始使用AI技术。自1956年“人 工智能”概念的首度提出以来,AI的受关注度就越来越高。其研究领域包括知识表示、机器 感知、机器思维、机器学习、机器行为,各种领域都取得了一定成就。强化学习也是一种多学 科交叉的产物,它本身是一种决策科学,所以在许多学科分支中都可以找到它的身影。强化 学习应用广泛,比如:直升机特技飞行、游戏AI、投资管理、发电站控制、让机器人模仿人类 行走等。 在游戏领域,为了提高用户体验,在很多场景下需要训练AI自动玩游戏,目前,游 戏训练场景接受度最高的是深度强化学习(Deep Reinforcement Learning,DRL),一般情 况下使用深度Q-learning网络(Deep Q-learning Network,DQN)来训练游戏AI自动玩游 戏。DRL网络充分利用了卷积神经网络处理大数据的能力,将游戏画面作为输入,同时融合 更多的游戏数据作为输入。然而神经网络极易受到对抗性攻击,专家学者们也提出了很多 攻击方法和防御方法,但是,针对深度强化学习的防御方法并没有成型的专利提出。随着深 度强化学习的应用越来越广泛,安全性必然成为其发展的重要隐患因素之一。为了解决这 一问题,本发明提出了有效的解决方法。 强化学习就是学习如何根据一个环境状态去决定如何行动,使得最后的奖励最 大。强化学习中两个最重要的特征就是试错(trial-and-error)和滞后奖励(delayed reward)。观察过程的状态容易被攻击者添加对抗扰动,攻击者也可直接攻击行动或奖励值 以达到攻击目的。奇异样本数据的存在会引起训练时间增大,同时也可能导致无法收敛,因 此,当存在奇异样本数据时,在进行训练之前需要对预处理数据进行归一化;反之,不存在 奇异样本数据时,则可以不进行归一化。智能体的行为直接受奖励值的影响,奖励值是根据 当前状态给出的,因此达到防御的最有效方式就是保证状态不受干扰。 如何防御状态不受干扰成为了迫不及待要解决的问题。
技术实现要素:
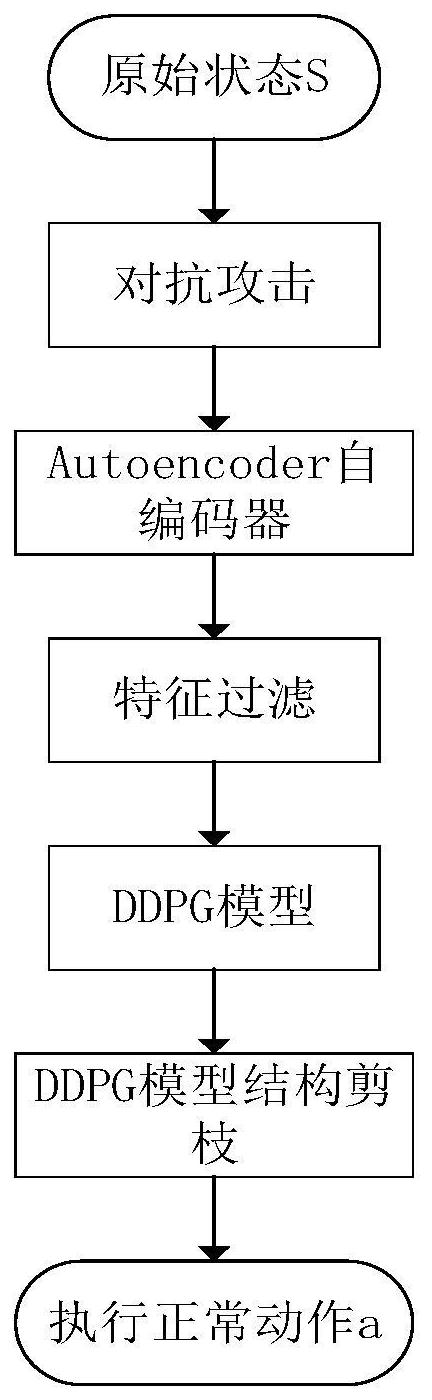
为了提高深度强化学习模型的鲁棒性以及学习效率,提高模型有效抵御对抗攻击 的能力,防止状态识别有误奖励值偏差太大从而使智能体采取错误的动作,本发明提出了 一种面向深度强化学习攻击的防御方法。 本发明的技术方案为: 一种面向深度强化学习模型的特征过滤防御方法,包括以下步骤: (1)针对生成连续行为的DDPG模型,包括actor网络和critic网络,其中,所述 actor网络包括动作估计网络和动作实现网络,所述critic网络包括状态估计网络和状态 4 CN 111600851 A 说 明 书 2/7 页 实现网络,对所述深度强化学习模型DDPG进行预训练,并将预训练阶段的当前状态、行为、 奖励值以及下一状态保存在缓存区; (2)训练自编码器,并利用训练好的自编码器的编码器对输入状态进行特征过滤, 获得过滤后的输入状态对应的特征图,并保存到缓存区; (3)对预训练后的DDPG模型中的卷积核进行剪枝,利用剪枝后的DPG模型进行动作 预测,输出并执行预测动作。 其中,所述深度强化学习模型DDPG的预训练过程包括: 针对状态估计网络,以实际Q值与估计Q值的平方损失为损失函数来更新状态估计 网络的参数; 针对动作估计网络,利用损失梯度来更新动作估计网络的参数; 将所述状态估计网络的参数复制给状态实现网络,以更新状态实现网络的参数; 将所述动作估计网络的参数复制给动作实现网络,以更新动作实现网络的参数。 其中,所述自编码器包括编码器和解码器两部分; 针对编码器部分的训练,首先采用RBM网络对编码器的卷积层进行逐层训练,逐层 训练结束后,根据编码器输入状态与解码器的输出状态的相似度来更新编码器所有卷积层 的参数; 针对解码器部分的训练,直接采用编码器的输入状态与解码器的输出状态的损失 来更新解码器的参数。 其中,采用以下公式计算编码器输入状态与解码器的输出状态的相似度KL(q(s)| |p(s)): 其中,q(s)是输入状态对应的概率分布,p(s)是解码器的输出状态对应的概率分 布,s表示输入状态,Ω表示状态总和。 其中,所述利用训练好的自编码器的编码器对输入状态进行特征过滤,获得过滤 后的输入状态对应的特征图的过程包括: 采用在伯努利随机变量X(i,j,k)对每个状态矩阵的位置(i,j,k)进行随机采样得 到一组随机值; 计算该一组随机值与位置(i,j,k)对应值总方差,以总方差最小化为目标滤除或 保留位置(i,j,k)对应值,以实现对输入状态的特征过滤。 其中,对预训练后的DDPG模型中的卷积核进行剪枝包括: 在结构剪枝过程中,细化了一组参数,这组参数保留了自适应网络的准确性,L(D| χ′)≈L(D|χ),相当于一个组合优化: min|L(D|χ′)-L(D|χ)|s.t||χ′||0≤η, 其中,D表示缓存区,参数χ包括动作估计网络的参数θ和状态估计网络的参数w,参 数χ″表示对参数θ和参数w剪枝后剩下参数,L(D|χ)表示根据缓存区D中的状态和动作值在 参数χ下计算的损失函数值,表示根据缓存区D中的状态和动作值在参数χ″下计算的损失函 数值; 5 CN 111600851 A 说 明 书 3/7 页 从一组参数χ开始,迭代地识别和删除最不重要的参数,通过在每次迭代中删除参 数,以确保最终满足||χ″||0≤η。 与现有技术相比,本发明具有的有益效果为: 1)使用Autoencoder模型有一定的去噪作用,可以提取更有价值的特征。2)总方差 测量图像中的微小变化量,总方差最小化使得图像中的微小扰动被去除。3)本发明防御方 法与深度强化学习的策略模型无关,可适用于任意策略网络。4)采用结构剪枝有效过滤掉 冗余的神经元,提高了训练效率。 附图说明 为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现 有技术描述中所需要使用的附图做简单地介绍,显而易见地,下面描述中的附图仅仅是本 发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动前提下,还可以根 据这些附图获得其他附图。 图1是面向深度强化学习模型的特征过滤防御方法的流程图; 图2是面向深度强化学习模型的特征过滤防御方法中深度强化学习原理图; 图3是面向深度强化学习模型的特征过滤防御方法中自编码器原理图; 图4是面向深度强化学习模型的特征过滤防御方法中基于结构剪枝的DDPG模型原 理图。











