
技术摘要:
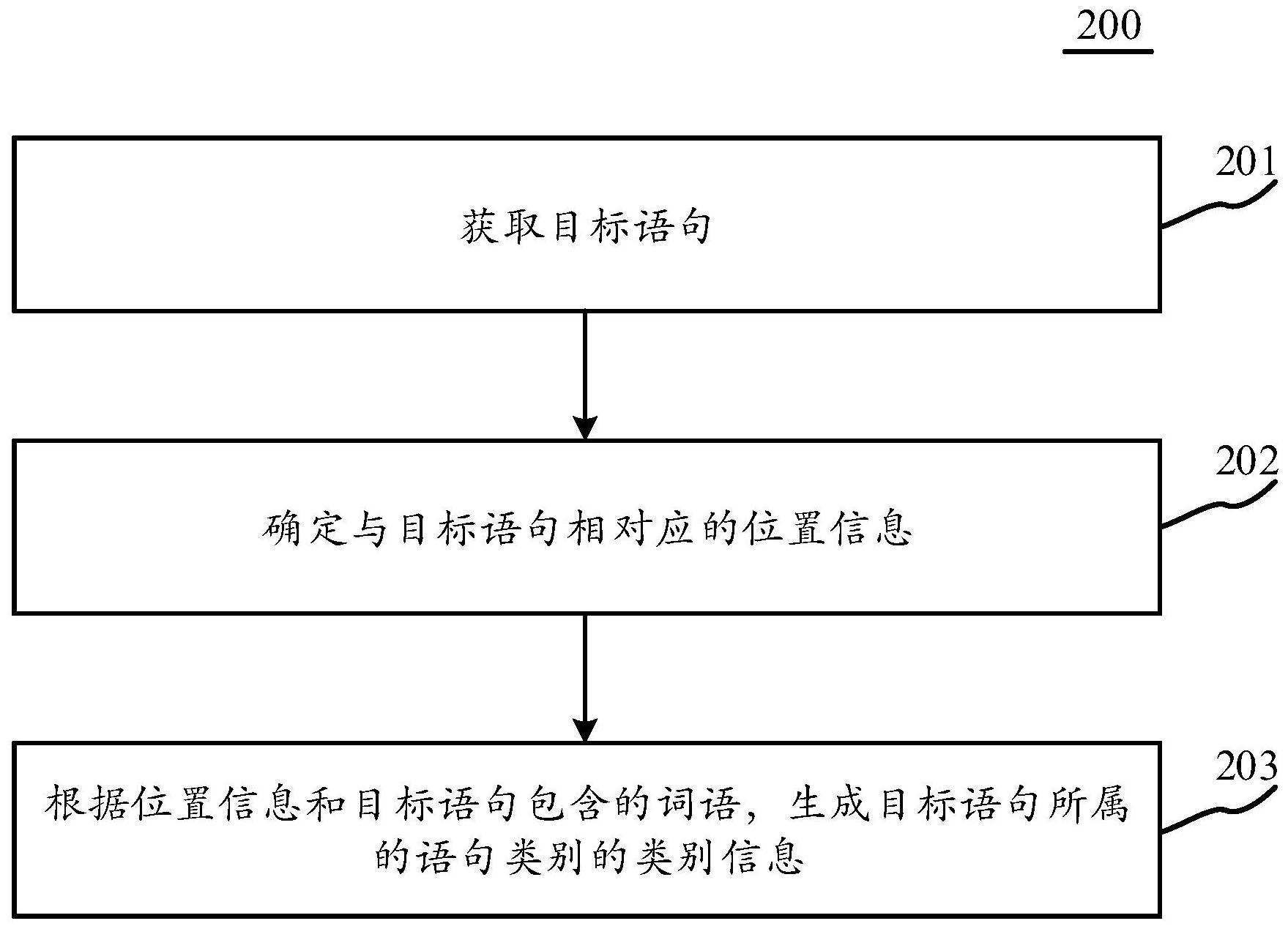
本公开的实施例公开了用于生成信息的方法和装置。该方法的一具体实施方式包括:获取目标语句;确定与目标语句相对应的位置信息,其中,位置信息包括:与目标语句相关的词语在包含该词语的语句中的位置,和/或,与目标语句相关的语句在包含该相关的语句的文本中的位置, 全部
背景技术:
包括:获取 目标语句;确定与目标语句相对应的位置信息, 其中,位置信息包括:与目标语句相关的词语在 包含该词语的语句中的位置,和/或,与目标语句 相关的语句在包含该相关的语句的文本中的位 置,其中,语句包含词语序列,文本包含语句序 列;根据位置信息和目标语句包含的词语,生成 目标语句所属的语句类别的类别信息。该实施方 式丰富了语句分类的方式,有助于提高语句分类 的速度和准确度。 CN 111581944 A CN 111581944 A 权 利 要 求 书 1/3 页 1.一种用于生成信息的方法,包括: 获取目标语句; 确定与所述目标语句相对应的位置信息,其中,所述位置信息包括:与所述目标语句相 关的词语在包含该词语的语句中的位置,和/或,与所述目标语句相关的语句在包含该相关 的语句的文本中的位置,其中,语句包含词语序列,文本包含语句序列; 根据所述位置信息和所述目标语句包含的词语,生成所述目标语句所属的语句类别的 类别信息。 2.根据权利要求1所述的方法,其中,所述根据所述位置信息和所述目标语句包含的词 语,生成所述目标语句所属的语句类别的类别信息,包括: 对所述位置信息和所述目标语句包含的词语进行向量化处理,得到向量数据; 将所述向量数据输入预先训练的分类模型,生成所述目标语句所属的语句类别的类别 信息,其中,所述分类模型用于从预先确定的语句类别集合中,确定与输入的向量数据相对 应的语句所属的语句类别。 3.根据权利要求2所述的方法,其中,所述分类模型包含多个二分类子模型;所述分类 模型包含的二分类子模型用于确定输入数据表征的语句属于所述语句类别集合中的各个 语句类别的相对概率。 4.根据权利要求1所述的方法,其中,所述确定与所述目标语句相对应的位置信息,包 括以下至少一项: 确定所述目标语句在目标文本中的位置的位置信息,其中,所述目标语句为所述目标 文本包含的语句; 确定所述目标语句在目标文本中的相邻语句,在所述目标文本中的位置的位置信息, 其中,所述目标语句为所述目标文本包含的语句; 确定所述目标语句包含的词语,在所述目标语句中的位置的位置信息; 确定所述目标语句在目标文本中的相邻语句包含的词语,在所述相邻语句中的位置的 位置信息,其中,所述目标语句为所述目标文本包含的语句。 5.根据权利要求1所述的方法,其中,所述目标语句为目标文本包含的语句;以及 所述确定与所述目标语句相对应的位置信息,包括: 从所述目标文本中,确定所述目标语句的在前相邻语句和在后相邻语句; 根据所述目标语句在所述目标文本中的位置信息、所述在前相邻语句在所述目标文本 中的位置信息和所述在后相邻语句在所述目标文本中的位置信息,确定与所述目标语句相 对应的位置信息。 6.根据权利要求5所述的方法,其中,所述根据所述目标语句在所述目标文本中的位置 信息、所述在前相邻语句在所述目标文本中的位置信息和所述在后相邻语句在所述目标文 本中的位置信息,确定与所述目标语句相对应的位置信息,包括: 从所述目标语句、所述在前相邻语句和所述在后相邻语句中,分别选取词语; 针对所选取的每个词语,确定该词语在包含该词语的语句中的位置信息,以获得所选 取的各个词语的位置信息; 将所述目标语句在所述目标文本中的位置信息、所述在前相邻语句在所述目标文本中 的位置信息、所述在后相邻语句在所述目标文本中的位置信息和所述各个词语的位置信 2 CN 111581944 A 权 利 要 求 书 2/3 页 息,确定为与所述目标语句相对应的位置信息。 7.根据权利要求6所述的方法,其中,所述根据所述目标语句在所述目标文本中的位置 信息、所述在前相邻语句在所述目标文本中的位置信息和所述在后相邻语句在所述目标文 本中的位置信息,确定与所述目标语句相对应的位置信息,还包括: 响应于确定所生成的所述目标语句所属的语句类别的类别信息不准确,执行以下步 骤: 从所述目标语句、所述在前相邻语句和所述在后相邻语句中,分别重新选取词语; 针对重新选取的每个词语,确定该词语在包含该词语的语句中的位置信息,以获得重 新选取的各个词语的位置信息; 将所述目标语句在所述目标文本中的位置信息、所述在前相邻语句在所述目标文本中 的位置信息、所述在后相邻语句在所述目标文本中的位置信息和所述重新选取的各个词语 的位置信息,确定为与所述目标语句相对应的位置信息。 8.根据权利要求6所述的方法,其中,所述从所述目标语句、所述在前相邻语句和所述 在后相邻语句中,分别选取词语,包括: 根据与所述语句类别集合中的每个语句类别相对应的词语序列中的词语的顺序,分别 从所述目标语句、所述在前相邻语句和所述在后相邻语句中选取预设数量个词语。 9.根据权利要求8所述的方法,其中,所述方法还包括: 获取文本集合,以及针对所述文本集合中的每个语句预先标注的语句类别,其中,预先 标注的语句类别为所述语句类别集合中的语句类别; 对所述文本集合中的各个文本进行分词处理,得到目标词语序列;以及 与所述语句类别集合中的每个语句类别相对应的词语序列通过如下步骤确定: 针对所述目标词语序列中的每个目标词语,计算该目标词语在该语句类别中出现的概 率的方差,得到与该目标词语相对应的方差; 根据所述目标词语序列中方差大于预设方差阈值的目标词语在该语句类别中出现的 概率,确定该目标词语在与该语句类别相对应的词语序列中的位置; 按照各个目标词语在与该语句类别相对应的词语序列中的位置,对各个目标词语进行 排序,以及将排序后的各个目标词语作为与该语句类别相对应的词语序列。 10.根据权利要求9所述的方法,其中,所述计算该目标词语在该语句类别中出现的概 率的方差,得到与该目标词语相对应的方差,包括: 确定该目标词语的词频集合,其中,词频集合中的词频表征包含该目标词语的语句被 标注为所述语句类别集合中的语句类别的次数,该目标词语的词频集合中的词频的数量与 所述语句类别集合中的语句类别的数量相等; 计算该目标词语的词频集合中的各个词频之和,得到该目标词语的总词频; 计算该目标词语的词频集合中的各个词频,分别与该目标词语的总词频的商,得到该 目标词语在该语句类别中出现的概率; 计算该目标词语在该语句类别中出现的概率的方差,得到与该目标词语相对应的方 差。 11.根据权利要求8所述的方法,其中,所述方法还包括: 响应于确定所生成的所述目标语句所属的语句类别的类别信息不准确,调整与所述语 3 CN 111581944 A 权 利 要 求 书 3/3 页 句类别集合中的语句类别相对应的词语序列,采用调整后的词语序列替代调整前的词语序 列。 12.根据权利要求1-11之一所述的方法,其中,所述方法还包括以下至少一项: 根据所述目标语句所属的语句类别,生成所述目标语句的回复语句; 播放与所述目标语句所属的语句类别相对应的音频; 呈现与所述目标语句所属的语句类别相对应的图像; 控制目标设备执行与所述目标语句所属的语句类别相对应的操作。 13.一种用于生成信息的装置,包括: 第一获取单元,被配置成获取目标语句; 确定单元,被配置成确定与所述目标语句相对应的位置信息,其中,所述位置信息包 括:与所述目标语句相关的词语在包含该词语的语句中的位置,和/或,与所述目标语句相 关的语句在包含该相关的语句的文本中的位置,其中,语句包含词语序列,文本包含语句序 列; 第一生成单元,被配置成根据所述位置信息和所述目标语句包含的词语,生成所述目 标语句所属的语句类别的类别信息。 14.一种电子设备,包括: 一个或多个处理器; 存储装置,其上存储有一个或多个程序, 当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实 现如权利要求1-12中任一所述的方法。 15.一种计算机可读介质,其上存储有计算机程序,其中,所述程序被处理器执行时实 现如权利要求1-12中任一所述的方法。 4 CN 111581944 A 说 明 书 1/19 页 用于生成信息的方法、装置、设备和介质 技术领域 本公开的实施例涉及计算机技术领域,具体涉及用于生成信息的方法和装置。
技术实现要素:
现阶段,存在大量对语句进行分类的需求。实践中,可以根据需求对语句进行各种 各样的分类。例如,确定语句是否为黄色、反动、暴力类型的语句。再例如,通过对文本进行 情感分析,确定文本中所蕴含的情感信息,以实现对语句的情感类别划分。 现有技术中,在对语句进行分类时,通常需要基于整个语句确定时间步的输入。例 如,将整个语句作为一个时间步的输入,或者,将整个语句进行向量化后,作为一个时间步 的输入。











