
技术摘要:
本发明提供了疾病蕴含训练集的构造方法,包括:基于预先存储的疾病数据集,建立疾病知识树结构;基于建立的疾病知识树结构,构造相应的蕴含关系和不蕴含关系;根据所述蕴含关系和不蕴含关系,构造疾病蕴含训练集。通过对疾病知识树结构进行加工处理得到蕴含和不蕴含关 全部
背景技术:
疾病蕴含关系对分析疾病之间的关系十分重要,一般对疾病蕴含关系是采用单纯 的人工进行构建的,但是人工构建不仅需要大量的专业知识,还需要大量的专业人员对目 前10万量级的疾病术语进行人工标注,工作量很大,耗时耗力,而且,还可能存在人为疏忽, 导致构造的疾病蕴含关系不合理,因此智能化构造疾病蕴含训练集就显得尤为重要。
技术实现要素:
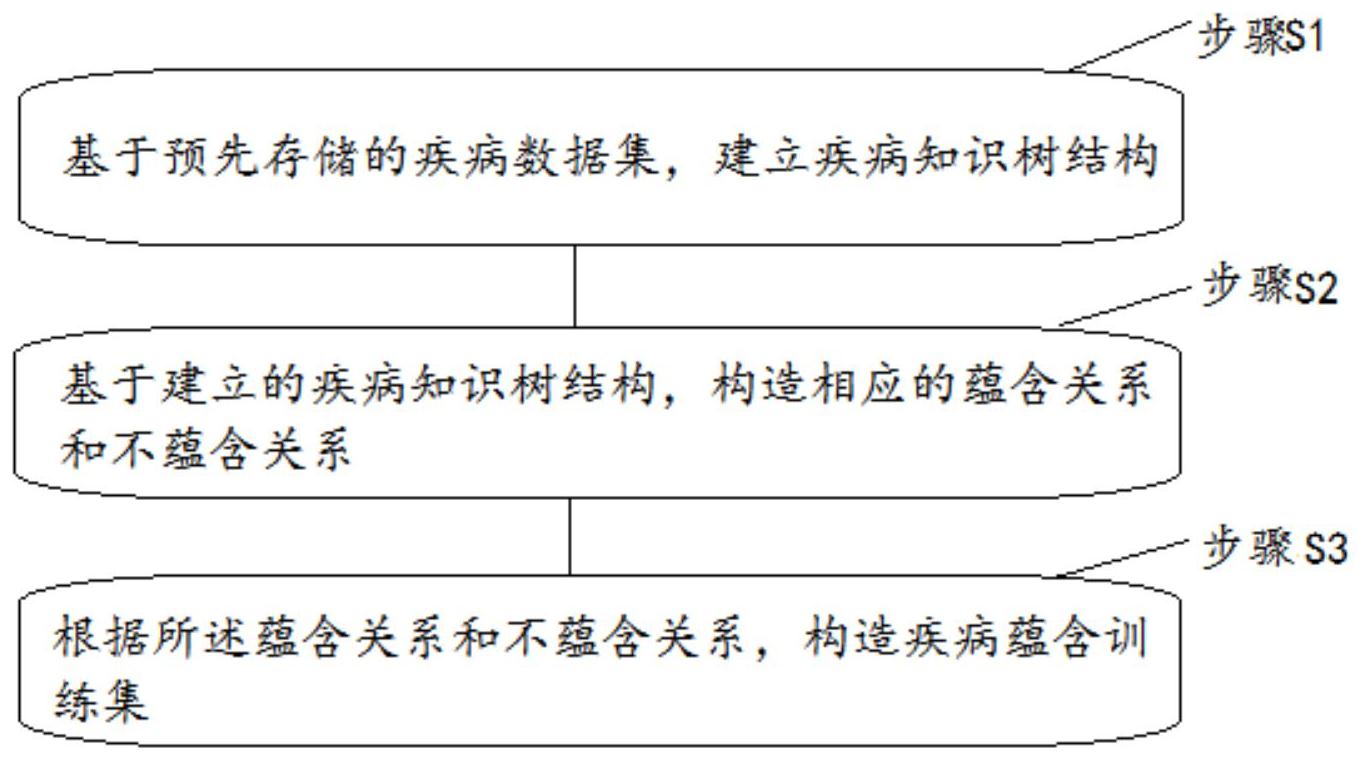
本发明提供疾病蕴含训练集的构造方法及装置,用以通过对疾病知识树结构进行 加工处理得到蕴含和不蕴含关系,并实现自动构造疾病蕴含数据集的目的,其速度快,可大 大减少人工的工作量。 本发明提供疾病蕴含训练集的构造方法,包括: 步骤S1:基于预先存储的疾病数据集,建立疾病知识树结构; 步骤S2:基于建立的疾病知识树结构,构造相应的蕴含关系和不蕴含关系; 步骤S3:根据所述蕴含关系和不蕴含关系,构造疾病蕴含训练集。 在一种可能实现的方式中,在执行所述步骤S1之后,且在执行所述步骤S2之前,包 括: 步骤S11:获取所述疾病知识树结构中的第一节点对应的第一预设词汇; 步骤S12:确定所获取的所述第一预设词汇对应的祖先节点的第二预设词汇; 步骤S13:判断所述第一预设词汇是否与所述第二预设词汇相同,若是,保留所述 第二预设词汇对应的祖先节点,并消除第一预设词汇对应的第一节点;否则,不执行任何操 作。 在一种可能实现的方式中,在执行所述步骤S13之后,且在执行所述步骤S2之前, 还包括: 步骤S131:获取所述疾病知识树结构中的第三预设词汇对应的待消除节点; 步骤S132:确定所有所述第三预设词汇在所述疾病知识树结构中的位置权重; 步骤S133:根据所确定的位置权重结果,获取第三预设词汇的最大位置权重; 步骤S134:根据所获取的最大位置权重,保留所述最大位置权重对应的待消除节 点,同时消除其余待消除节点。 在一种可能实现的方式中,在执行所述步骤S134之后,且在执行所述步骤S2之前, 还包括: 步骤1341:在所述步骤S134的基础上获取所述疾病知识树结构中的剩余节点,确 定所述剩余节点中的每个非叶子节点的节点长度,并将节点长度大于预设长度、且符合疾 病命名规则的非叶子节点标记为描述性节点,其余非叶子节点标记为非描述性节点,其中, 4 CN 111599478 A 说 明 书 2/8 页 所述描述性节点不作为构造疾病蕴含训练集的候选节点; 步骤S1342:获取所述疾病知识树结构中的叶子节点,根据所述叶子节点和与所述 叶子节点相关的非描述性节点,构造节点蕴含关系规则; 同时,根据所述剩余节点,构造新的疾病知识树结构。 在一种可能实现的方式中,在执行所述步骤S2的过程中,根据所述新的疾病知识 树结构,构造相应的蕴含关系,其步骤包括: 步骤S21:获取所述新的疾病知识树结构中的叶子节点; 步骤S22:基于所述新的疾病知识树结构,获取所述步骤S21所获取的叶子节点的 父节点; 步骤S23:根据所述节点蕴含关系规则,判断所获取的所述叶子节点和父节点是否 为描述性节点; 若所述叶子节点和所述父节点都是非描述性节点,则所述叶子节点和所述父节点 生成第一蕴含对; 若所述叶子节点不是描述性节点,且父节点是描述性节点,获取所述父节点对应 的第一个非描述性的祖先节点,则所述叶子节点和所述第一个非描述性的祖先节点生成第 二蕴含对;否则,不执行任何操作; 其中,根据所述步骤S23所生成的第一蕴含对和第二蕴含对,为构造的蕴含关系。 在一种可能实现的方式中,在执行所述步骤S2的过程中,根据所述新的疾病知识 树结构,构造相应的不蕴含关系,其步骤包括: 步骤S41:获取所述新的疾病知识树结构中的叶子节点; 步骤S42:基于所述新的疾病知识树结构,获取所述步骤S41所获取的叶子节点的 叔父节点; 步骤S43:构造获取的所有所述叔父节点之间的蕴含负例; 步骤S44:基于文本相似度算法,判断所有所述叔父节点中的第一叔父节点和第二 叔父节点之间的编辑距离相似度,若编辑距离相似度小于预设距离相似度,则表明不将所 述第一叔父节点和第二叔父节点作为蕴含负例,且删除所述第一叔父节点和第二叔父节点 之间的不蕴含关系; 若编辑距离相似度不小于预设距离相似度,则表明可将所述第一叔父节点和第二 叔父节点作为蕴含负例,且保留所述第一叔父节点和第二叔父节点之间的不蕴含关系。 在一种可能实现的方式中,在执行所述步骤S44之后,还包括: 步骤S45:根据所述步骤S44的判断结果,获取所保留的所有所述第一叔父节点和 第二叔父节点之间的不蕴含关系。 在一种可能实现的方式中,所述步骤S44中,基于文本相似度算法,判断所有所述 叔父节点中的第一叔父节点和第二叔父节点之间的编辑距离相似度的步骤包括: 步骤S441:获取所述第一叔父节点的第一文本信息S1; 步骤S442:获取所述第二叔父节点的第二文本信息S2; 步骤S443:根据公式(1)确定所述第一文本信息S1和第二文本信息S2之间的的编 辑距离相似度; 5 CN 111599478 A 说 明 书 3/8 页 其中,sim(S1,S2)表示第一文本信息S1和第二文本信息S2的文本相似度;max( )表 示最大函数;len( )表示获取文本信息对应的字符串长度,len(S1)表示第一文本信息S1对 应的字符串长度;len(S2)表示第二文本信息S2对应的字符串长度;editDistance(S1,S2) 表示第一文本信息S1与第二文本信息S2之间的编辑距离。 本发明实施例提供疾病蕴含训练集的构造装置,包括: 建立模块,用于基于预先存储的疾病数据集,建立疾病知识树结构; 第一构造模块,用于基于建立的疾病知识树结构,构造相应的蕴含关系和不蕴含 关系; 第二构造模块,用于根据所述蕴含关系和不蕴含关系,构造疾病蕴含训练集。 本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变 得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明 书、权利要求书、以及附图中所特别指出的结构来实现和获得。 下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。 附图说明 附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实 施例一起用于解释本发明,并不构成对本发明的限制。在附图中: 图1为本发明实施例中疾病蕴含训练集的构造方法的流程图; 图2为本发明实施例中蕴含关系与不蕴含关系的结构图; 图3为本发明实施例中构造蕴含关系的流程图; 图4为本发明实施例中构造不蕴含关系的流程图; 图5为本发明实施例中疾病蕴含训练集的构造装置的结构图。











