
技术摘要:
本发明涉及机器人导航定位技术领域,具体是一种动态场景下的视觉定位方法及装置,所述方法包括:获取当前帧图像,提取所述当前帧图像的特征点;将所述当前帧图像输入预设深度学习网络进行语义分割,得到目标语义图像;根据所述目标语义图像确定所述当前帧图像的运动掩 全部
背景技术:
随着人工智能技术的发展,越来越多的智能移动机器人出现在生产生活中的各个 场景。从工业机器人到家政服务机器人,从无人机到水下探测机器人,智能化的一个重要条 件就是能够自主运动,即实现机器人的自主导航。智能移动机器人要实现各种环境下的自 主化移动,需要解决两个基本的问题分别是定位与建图,而其中核心就是同时定位与建图 (Simultaneous Localization and Mapping,SLAM)技术。 根据传感器类型的不同,SLAM技术主要可以分为激光SLAM和视觉SLAM。由于图像 在信息存储上的丰富性,以及图像对于一些更高层次工作(如语义分割与物体检测)的服务 型,视觉SLAM技术在近年来被广泛研究。现有的视觉SLAM技术往往都是一个完整的架构,包 含了特征提取、回环检测等部分,也已经在某些环境下取得了较好的试验结果。但是现有的 基于点特征的视觉SLAM技术都是基于静态环境假设的,而对于大多数的实际场景,绝对的 静态场景是不存在的,因此在位于动态环境时其位姿估计的准确性会急剧下降甚至无法工 作。与此同时,由于未对运动物体加以判断,在重建稠密点云地图的时候会导致“伪迹”的出 现,从而造成对环境的错误感知。
技术实现要素:
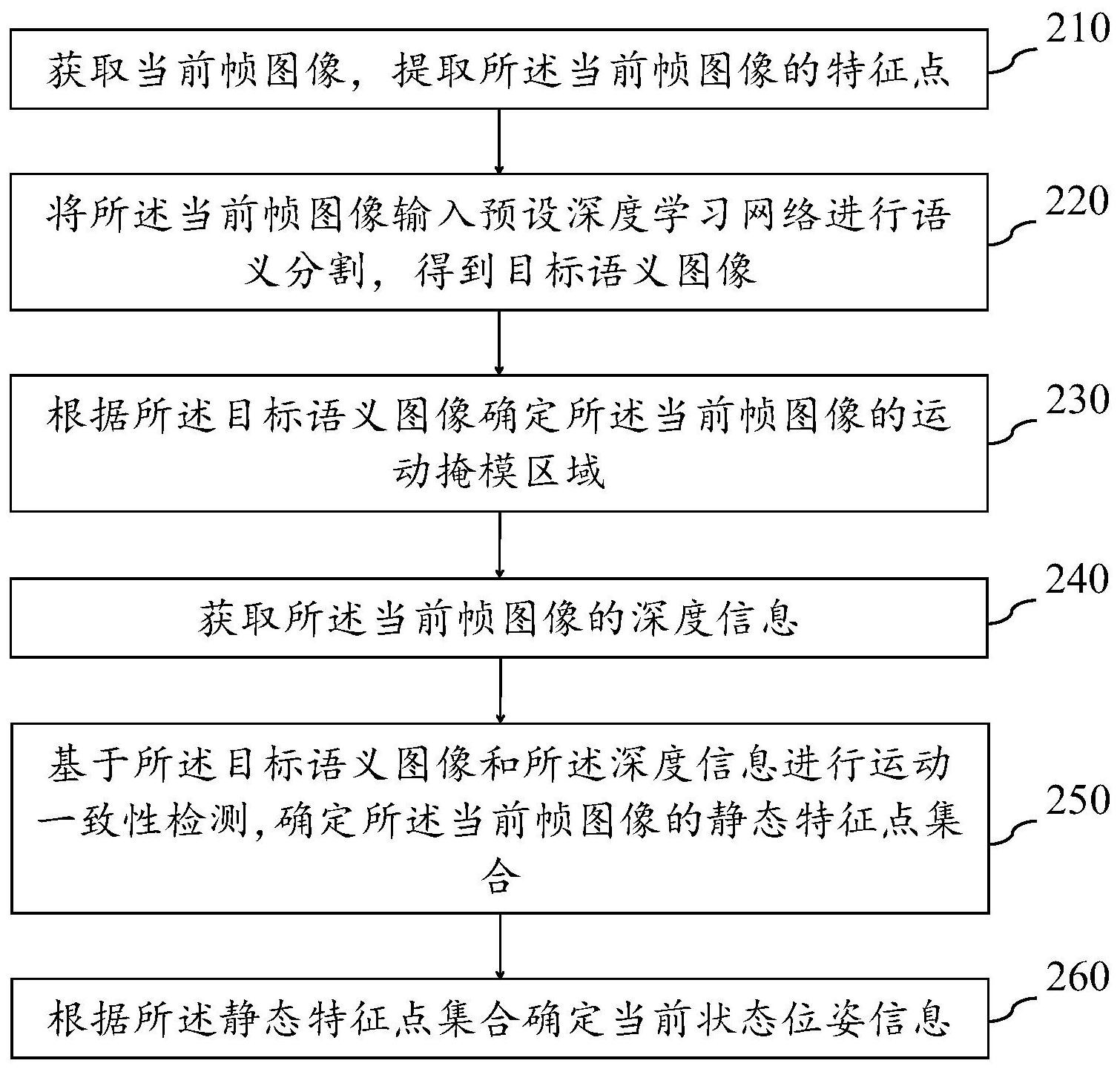
针对现有技术的上述问题,本发明的目的在于提供一种动态场景下的视觉定位方 法及装置,能够提高在动态环境中对位姿估计的精确性和鲁棒性。 为了解决上述问题,本发明提供一种动态场景下的视觉定位方法,包括: 获取当前帧图像,提取所述当前帧图像的特征点; 将所述当前帧图像输入预设深度学习网络进行语义分割,得到目标语义图像; 根据所述目标语义图像确定所述当前帧图像的运动掩模区域; 获取所述当前帧图像的深度信息; 基于所述目标语义图像和所述深度信息进行运动一致性检测,确定所述当前帧图 像的静态特征点集合; 根据所述静态特征点集合确定当前状态位姿信息。 进一步地,所述基于所述目标语义图像和所述深度信息进行运动一致性检测,确 定所述当前帧图像的静态特征点集合包括: 根据所述目标语义图像确定所述当前帧图像的背景区域; 根据所述当前帧图像的背景区域的特征点确定第一位姿信息; 基于所述第一位姿信息和所述深度信息确定所述运动掩模区域的特征点的类型, 所述类型包括动态特征点和静态特征点; 4 CN 111724439 A 说 明 书 2/9 页 剔除所述运动掩模区域的特征点中的动态特征点,保留静态特征点; 根据所述静态特征点和所述背景区域的特征点生成静态特征点集合。 进一步地,所述基于所述第一位姿信息和所述深度信息确定所述运动掩模区域的 特征点的类型包括: 根据所述第一位姿信息和所述深度信息计算所述运动掩模区域的特征点的运动 得分; 当所述运动得分小于预设阈值时,判定所述特征点为静态特征点; 当所述运动得分大于或等于预设阈值时,判定所述特征点为动态特征点。 具体地,所述根据所述第一位姿信息和所述深度信息计算所述运动掩模区域的特 征点的运动得分包括: 获取第一参考帧图像的运动掩模区域的特征点,将所述第一参考帧图像的运动掩 模区域的特征点与所述当前帧图像的运动掩模区域的特征点进行匹配,得到匹配点对;其 中,所述第一参考帧图像为所述当前帧图像的前一帧图像; 对所述匹配点对进行筛选,去除误匹配的匹配点对; 根据所述第一位姿信息和所述深度信息计算筛选后的匹配点对之间的距离,将所 述距离作为所述运动掩模区域的特征点的运动得分。 进一步地,所述根据所述目标语义图像确定所述当前帧图像的运动掩模区域之 后,还包括: 获取第一参考帧图像的第一运动掩模区域和第二参考帧图像的第二运动掩模区 域;其中,所述第一参考帧图像为所述当前帧图像的前一帧图像,所述第二参考帧图像为所 述第一参考帧图像的前一帧图像; 根据所述第一运动掩模区域和所述当前帧图像的运动掩模区域判断所述当前帧 图像是否发生漏检; 如果所述当前帧图像发生漏检,根据所述第一运动掩模区域和所述第二运动掩模 区域确定第一目标运动掩模区域; 将所述当前帧图像的运动掩模区域替换为所述第一目标运动掩模区域。 优选地,所述方法还包括: 如果所述当前帧图像未发生漏检,根据所述第一运动掩模区域和所述当前帧图像 的运动掩模区域确定第二目标运动掩模区域; 将所述当前帧图像的运动掩模区域替换为所述第二目标运动掩模区域。 进一步地,所述获取所述当前帧图像的深度信息之后,还包括: 利用预设形态学方法对所述深度信息进行修复。 进一步地,所述根据所述静态特征点集合确定当前状态位姿信息包括: 在产生新的关键帧时,建立所述静态特征点集合中的特征点、关键帧和地图点之 间的数据关联; 根据所述静态特征点集合中的特征点确定第二位姿信息; 根据所述第二位姿信息和所述数据关联进行位姿优化,确定当前状态位姿信息。 进一步地,所述方法还包括: 基于所述目标语义图像、所述当前状态位姿信息及所述静态特征点集合生成静态 5 CN 111724439 A 说 明 书 3/9 页 物体点云数据; 根据所述静态物体点云数据进行静态物体点云地图的稠密重建。 本发明另一方面保护一种动态场景下的视觉定位装置,包括: 第一获取模块,用于获取当前帧图像,提取所述当前帧图像的特征点; 语义分割模块,用于将所述当前帧图像输入预设深度学习网络进行语义分割,得 到目标语义图像; 确定模块,用于根据所述目标语义图像确定所述当前帧图像的运动掩模区域; 第二获取模块,用于获取所述当前帧图像的深度信息; 检测模块,用于基于所述目标语义图像和所述深度信息进行运动一致性检测,确 定所述当前帧图像的静态特征点集合; 定位模块,用于根据所述静态特征点集合确定当前状态位姿信息。 由于上述技术方案,本发明具有以下有益效果: 本发明的动态场景下的视觉定位方法通过对图像进行语义分割,并根据语义分割 结果和深度信息进行运动一致性检测,剔除运动掩模区域的动态特征点,将运动掩模中的 静态特征点加入静态特征点集合,并利用所述静态特征点集合实现位姿优化,并重建出稠 密的静态物体点云地图。能够提高在动态环境中对位姿估计的精确性和鲁棒性,提高所述 静态物体点云地图的准确度,从而提高对环境的感知的准确度。 另外,本发明的动态场景下的视觉定位方法基于运动连续性假设,对相邻帧图像 的语义分割结果进行融合,补偿漏分割的情况,能够进一步提高本方法的准确性。 附图说明 为了更清楚地说明本发明的技术方案,下面将对实施例或现有技术描述中所需要 使用的附图作简单的介绍。显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对 于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其 它附图。 图1是本发明一个实施例提供的动态场景下的视觉定位系统的结构示意图; 图2是本发明一个实施例提供的动态场景下的视觉定位方法的流程图; 图3是本发明另一个实施例提供的动态场景下的视觉定位方法的流程图; 图4是本发明另一个实施例提供的动态场景下的视觉定位方法的流程图; 图5是本发明另一个实施例提供的动态场景下的视觉定位方法的流程图; 图6A是本发明一个实施例提供的ORB-SLAM2系统的测试结果示意图; 图6B是本发明一个实施例提供的DS-SLAM系统的测试结果示意图; 图6C是本发明一个实施例提供的动态场景下的视觉定位方法的测试结果示意图; 图7是本发明另一个实施例提供的动态场景下的视觉定位装置的结构示意图。











