
技术摘要:
一种数据处理方法及装置,所述方法包括:迭代执行以下过程,直到达到迭代终止条件:对特征词集合中的特征词进行近似词扩展,并将得到的扩展特征词添加至所述特征词集合;基于添加了扩展特征词后的所述特征词集合中的特征词构建若干训练样本;其中,所述若干训练样本中 全部
背景技术:
随着信息化的发展,互联网中包含着越来越多的企业的业务信息,监管机构可以 获取并分析这些信息,进而判断对应的企业是否属于违法违规企业。 通常,人们可以通过机器学习的方式,构建并训练分类模型,以根据企业业务信息 确定企业是否属于违法违规企业;但是,传统的机器学习方法为了保证生成模型的准确度, 在模型训练阶段需要使用大量的人工标注的样本,因此会消耗大量的人力资源。
技术实现要素:
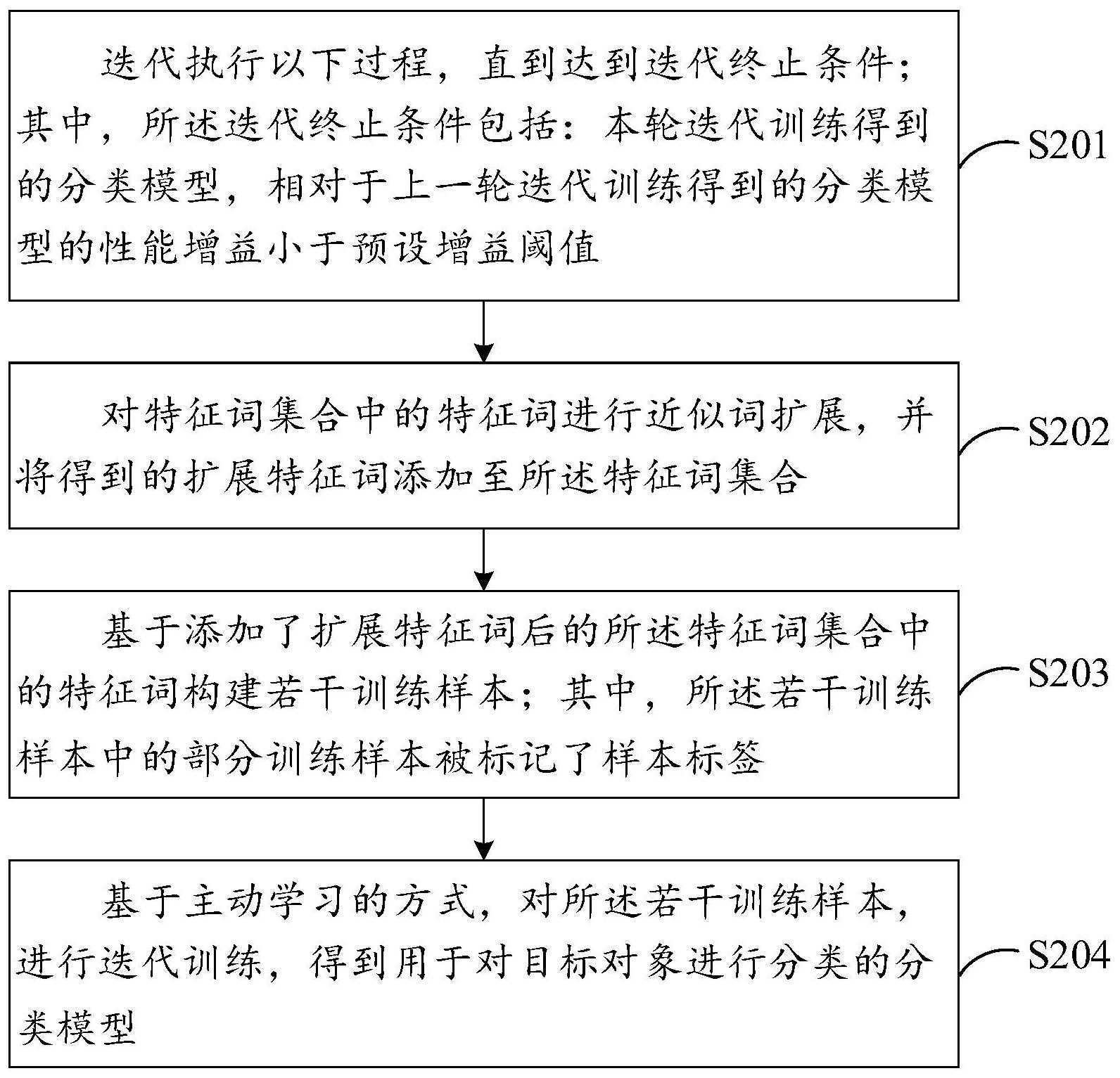
有鉴于此,本说明书公开了一种数据处理方法和装置。 根据本说明书实施例的第一方面,公开了一种数据处理方法,包括: 迭代执行以下过程,直到达到迭代终止条件;其中,所述迭代终止条件包括:本轮 迭代训练得到的分类模型,相对于上一轮迭代训练得到的分类模型的性能增益小于预设增 益阈值: 对特征词集合中的特征词进行近似词扩展,并将得到的扩展特征词添加至所述特 征词集合; 基于添加了扩展特征词后的所述特征词集合中的特征词构建若干训练样本;其 中,所述若干训练样本中的部分训练样本被标记了样本标签; 基于主动学习的方式,对所述若干训练样本,进行迭代训练,得到用于对目标对象 进行分类的分类模型。 根据本说明书实施例的第二方面,公开了一种数据处理装置,包括: 迭代控制模块,迭代执行以下过程,直到达到迭代终止条件;其中,所述迭代终止 条件包括:本轮迭代训练得到的分类模型,相对于上一轮迭代训练得到的分类模型的性能 增益小于预设增益阈值: 近似词扩展模块,对特征词集合中的特征词进行近似词扩展,并将得到的扩展特 征词添加至所述特征词集合; 训练样本构建模块,基于添加了扩展特征词后的所述特征词集合中的特征词构建 若干训练样本;其中,所述若干训练样本中的部分训练样本被标记了样本标签; 分类模型训练模块,基于主动学习的方式,对所述若干训练样本,进行迭代训练, 得到用于对目标对象进行分类的分类模型。 以上技术方案中,一方面,由于在训练阶段采用了主动学习的方式进行模型训练, 因此,训练样本中可以只有一部分样本被标记样本标签,所以无需人工对所有训练样本进 行标记,降低了模型训练过程中的人工成本; 另一方面,由于采用了近义词扩展的方式对特征词集合进行了补充,因此可以基 6 CN 111611390 A 说 明 书 2/14 页 于数量较少的初始样本生成数量丰富的训练样本,有助于提高分类模型的精确度和覆盖 度。 附图说明 此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本说明书的实 施例,并与说明书文本一同用于解释原理。 图1是本说明书示出的一利用分类模型对企业进行分类的流程示例图; 图2是本说明书示出的一数据处理方法的流程示例图; 图3是本说明书示出的一主动学习方法进行模型训练的流程示例图; 图4是本说明书示出的一迭代过程中特征词集和分类模型的变化示例图; 图5是本说明书示出的一倾向性指标区间划分的示例图; 图6是本说明书示出的一数据处理装置的结构示例图; 图7是本说明书示出的一用于数据处理的计算机设备的结构示例图。











