
技术摘要:
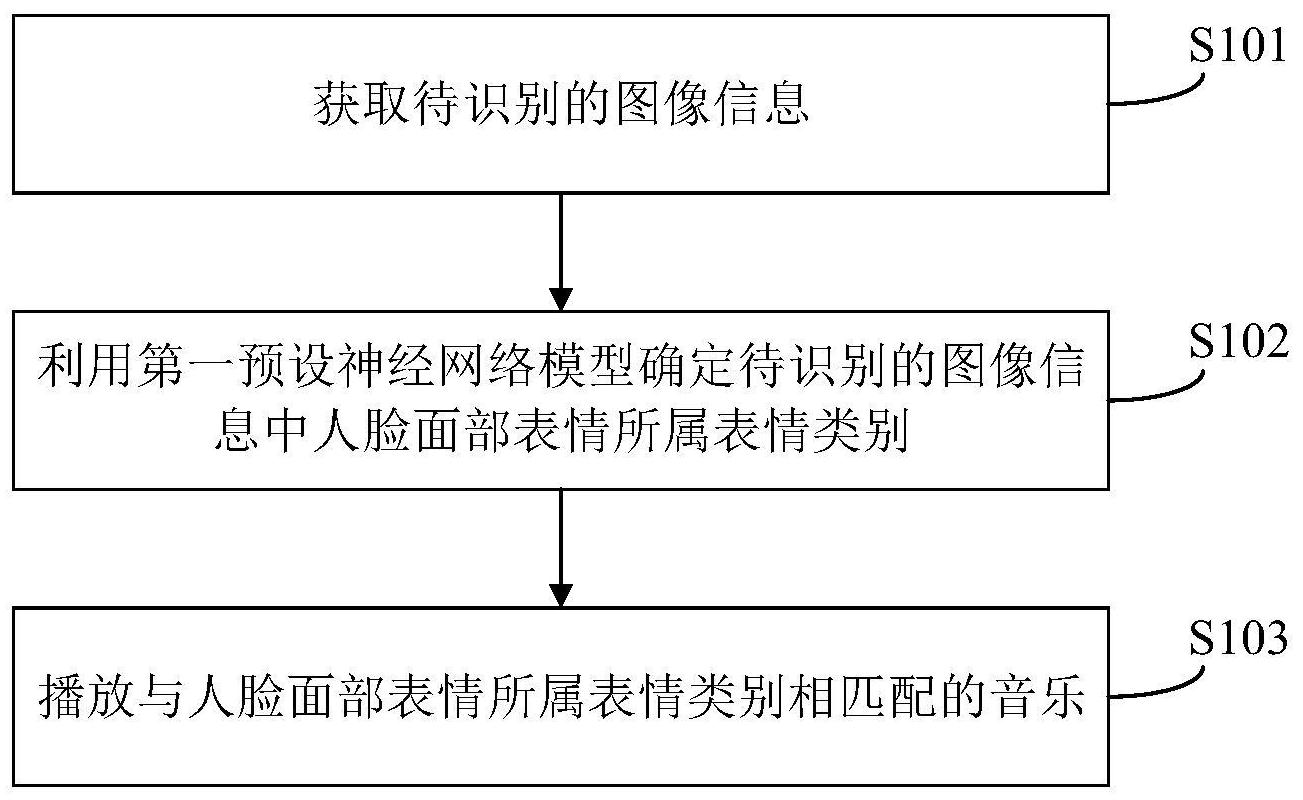
本申请适用于机器人技术领域,提供了一种音乐播放方法、装置及机器人,其中音乐播放方法,应用于机器人,所述音乐播放方法包括:获取待识别的图像信息,利用第一预设神经网络模型确定所述待识别的图像信息中人脸面部表情所属表情类别,播放与所述人脸面部表情所属表情 全部
背景技术:
由于机器人不仅能与用户互动,还能为用户播放指定的音乐,因而深受广大消费 者的喜爱。 现有技术是通过手机上的应用程序控制机器人进行音乐播放,在播放音乐之前, 需要用户开启手机上的无线通信模块,与机器人进行通信连接,该过程较为耗时,而且如果 用户在手机上误输入某些播放指令,将导致机器人无法及时播放预期的音乐,这将难以达 到精准控制机器人的目的。
技术实现要素:
本申请实施例提供了一种音乐播放方法、装置及机器人,通过智能识别用户的面 部表情,并根据识别结果控制音乐的播放,不仅能够节省播放音乐前所需的等待时间,还可 达到精准控制机器人的目的。 本申请实施例的第一方面提供了一种音乐播放方法,应用于机器人,所述音乐播 放方法包括: 获取待识别的图像信息; 利用第一预设神经网络模型确定所述待识别的图像信息中人脸面部表情所属表 情类别; 播放与所述人脸面部表情所属表情类别相匹配的音乐。 在一个实施例中,在利用第一预设神经网络模型确定所述待识别的图像信息中人 脸面部表情所属表情类别之前,还包括: 将所述待识别的图像信息输入已训练的第二预设神经网络模型进行人脸检测,输 出所述待识别的图像信息对应的目标人脸检测结果,其中,所述目标人脸检测结果包括所 述待识别的图像信息中人脸所在区域和所述人脸所在区域中的面部特征信息; 根据所述面部特征信息,对所述人脸所在区域中的人脸进行姿态校正,得到校正 后的人脸图像信息。 在一个实施例中,所述第二预设神经网络模型包括第二输入层、第二隐含层和第 二输出层,所述第二输入层包括N个子输入层,所述第二隐含层包括N-1个子隐含层,所述第 二输出层包括N-1个子输出层,N为大于3的整数; 所述将所述待识别的图像信息输入已训练的第二预设神经网络模型进行人脸检 测,输出所述待识别的图像信息对应的目标人脸检测结果包括: 将所述待识别的图像信息输入第一个子输入层进行可分离卷积操作,输出所述第 一个子输入层对应的特征图; 将所述第一个子输入层对应的特征图输入第二个子输入层进行可分离卷积操作, 4 CN 111597378 A 说 明 书 2/12 页 输出所述第二个子输入层对应的特征图; 将所述第一个子输入层对应的特征图和所述第二个子输入层对应的特征图输入 第一个子隐含层进行金字塔池化操作,输出所述第一个子隐含层对应的特征图; 将所述第一个子隐含层对应的特征图输入第一个子输出层进行单点无头人脸检 测,输出所述第一个子输出层对应的人脸检测结果; 对于所述第二输入层中第i个子输入层,i为大于2且小于或等于N的整数,第i个子 输入层为剩余N-2个子输入层中的任一个子输入层,所述剩余N-2个子输入层为所述第二输 入层中除所述第一个子输入层和第二个子输入层之外的子输入层,将第i-1个子输入层对 应的特征图输入所述第i个子输入层进行可分离卷积操作,输出所述第i个子输入层对应的 特征图; 将所述第i个子输入层对应的特征图和第i-2个子隐含层对应的特征图输入第i-1 个子隐含层进行金字塔池化操作,输出所述第i-1个子隐含层对应的特征图; 将所述第i-1个子隐含层对应的特征图输入第i-1个子输出层进行单点无头人脸 检测,输出所述第i-1个子输出层对应的人脸检测结果; 根据所述N-1个子输出层各自对应的人脸检测结果,确定所述待识别的图像信息 对应的目标人脸检测结果。 在一个实施例中,所述利用第一预设神经网络模型确定所述待识别的图像信息中 人脸面部表情所属表情类别包括: 将所述校正后的人脸图像信息输入已训练的第一预设神经网络模型进行人脸面 部表情的识别,确定所述人脸面部表情所属表情类别。 在一个实施例中,所述第一预设神经网络模型包括第一输入层、第一隐含层和第 一输出层,所述将所述校正后的人脸图像信息输入已训练的第一预设神经网络模型进行人 脸面部表情的识别,确定所述人脸面部表情所属表情类别包括: 将所述校正后的人脸图像信息输入所述第一输入层进行可分离卷积操作,输出目 标特征图; 将所述目标特征图输入所述第一隐含层进行特征融合,输出所述人脸面部表情属 于各个预设表情类别的预测值; 将所述预测值输入所述第一输出层进行归一化处理,得到所述人脸面部表情属于 各个预设表情类别的预测概率,并确定预测概率最大的预设表情类别为所述人脸面部表情 所属表情类别。 在一个实施例中,在所述获取待识别的图像信息之前,还包括: 获取用户的语音信息; 当获取的所述语音信息包含预设关键词时,开启所述机器人的图像获取功能。 在一个实施例中,在所述播放与所述人脸面部表情所属表情类别相匹配的音乐之 前,还包括: 向用户推荐与所述人脸面部表情所属表情类别相匹配的音乐; 接收所述用户对推荐的所述音乐的反馈信息; 相应的,所述播放与所述人脸面部表情所属表情类别相匹配的音乐包括: 当所述反馈信息为正面反馈时,播放推荐的所述音乐。 5 CN 111597378 A 说 明 书 3/12 页 本申请实施例与现有技术相比存在的有益效果是:本申请实施例可以通过第一预 设神经网络模型智能识别用户的面部表情,并根据识别结果控制音乐的播放,不仅能够节 省播放音乐前所需的等待时间,还可达到精准控制机器人的目的;本申请实施例还可以通 过第一预设神经网络模型快速对校正后的人脸图像信息中的面部表情进行识别,并通过第 二预设神经网络模型快速对待识别的图像信息进行人脸检测,有利于降低识别的错误率和 提高机器人的智能性,具有较强的易用性和实用性。 本申请实施例的第二方面提供了一种音乐播放装置,包括: 图像获取模块,用于获取待识别的图像信息; 确定模块,用于利用第一预设神经网络模型确定所述待识别的图像信息中人脸面 部表情所属表情类别; 播放模块,用于播放与所述人脸面部表情所属表情类别相匹配的音乐。 在一个实施例中,所述确定模块具体用于: 将所述校正后的人脸图像信息输入已训练的第一预设神经网络模型进行人脸面 部表情的识别,确定所述人脸面部表情所属表情类别。 在一个实施例中,所述第一预设神经网络模型包括第一输入层、第一隐含层和第 一输出层,所述确定模块具体包括: 可分离卷积单元,用于将所述校正后的人脸图像信息输入所述第一输入层进行可 分离卷积操作,输出目标特征图; 第一预测单元,用于将所述目标特征图输入所述第一隐含层进行特征融合,输出 所述人脸面部表情属于各个预设表情类别的预测值; 第二预测单元,用于将所述预测值输入所述第一输出层进行归一化处理,得到所 述人脸面部表情属于各个预设表情类别的预测概率,并确定预测概率最大的预设表情类别 为所述人脸面部表情所属表情类别。 在一个实施例中,所述音乐播放装置还包括: 人脸检测模块,用于将所述待识别的图像信息输入已训练的第二预设神经网络模 型进行人脸检测,得到所述待识别的图像信息对应的目标人脸检测结果,其中,所述目标人 脸检测结果包括所述待识别的图像信息中人脸所在区域和所述人脸所在区域中的面部特 征信息; 校正模块,用于根据所述面部特征信息,对所述人脸所在区域中的人脸进行姿态 校正,得到校正后的人脸图像信息。 在一个实施例中,所述第二预设神经网络模型包括第二输入层、第二隐含层和第 二输出层,所述第二输入层包括N个子输入层,所述第二隐含层包括N-1个子隐含层,所述第 二输出层包括N-1个子输出层,N为大于3的整数,所述人脸检测模块具体包括: 第一可分离卷积单元,用于将所述待识别的图像信息输入第一个子输入层进行可 分离卷积操作,输出所述第一个子输入层对应的特征图; 第二可分离卷积单元,用于将所述第一个子输入层对应的特征图输入第二个子输 入层进行可分离卷积操作,输出所述第二个子输入层对应的特征图; 第一金字塔池化单元,用于将所述第一个子输入层对应的特征图和所述第二个子 输入层对应的特征图输入第一个子隐含层进行金字塔池化操作,输出所述第一个子隐含层 6 CN 111597378 A 说 明 书 4/12 页 对应的特征图; 第一人脸检测单元,用于将所述第一个子隐含层对应的特征图输入第一个子输出 层进行单点无头人脸检测,输出所述第一个子输出层对应的人脸检测结果; 对于所述第二输入层中第i个子输入层,i为大于2且小于或等于N的整数,第i个子 输入层为剩余N-2个子输入层中的任一个子输入层,所述剩余N-2个子输入层为所述第二输 入层中除所述第一个子输入层和第二个子输入层之外的子输入层, 第i可分离卷积单元,用于将第i-1个子输入层对应的特征图输入所述第i个子输 入层进行可分离卷积操作,输出所述第i个子输入层对应的特征图; 第i-1金字塔池化单元,用于将所述第i个子输入层对应的特征图和第i-2个子隐 含层对应的特征图输入第i-1个子隐含层进行金字塔池化操作,输出所述第i-1个子隐含层 对应的特征图; 第i-1人脸检测单元,用于将所述第i-1个子隐含层对应的特征图输入第i-1个子 输出层进行单点无头人脸检测,输出所述第i-1个子输出层对应的人脸检测结果; 确定单元,用于根据所述N-1个子输出层各自对应的人脸检测结果,确定所述待识 别的图像信息对应的目标人脸检测结果。 在一个实施例中,所述音乐播放装置还包括: 语音获取模块,用于获取用户的语音信息; 控制模块,用于当获取的所述语音信息包含预设关键词时,开启所述机器人的图 像获取功能。 在一个实施例中,所述音乐播放装置还包括: 推荐模块,用于向用户推荐与所述人脸面部表情所属表情类别相匹配的音乐; 接收模块,用于接收所述用户对推荐的所述音乐的反馈信息; 相应的,播放模块具体用于: 当所述反馈信息为正面反馈时,播放推荐的所述音乐。 本申请实施例的第三方面提供了一种机器人,包括存储器、处理器以及存储在所 述存储器中并可在所述处理器上运行的计算机程序,上述处理器执行上述计算机程序时实 现上述第一方面中任一项所述的音乐播放方法。 本申请实施例的第四方面提供了一种计算机可读存储介质,该计算机可读存储介 质上存储有计算机程序,上述计算机程序被处理器执行时实现上述第一方面中任一项所述 的音乐播放方法。 本申请实施例的第五方面提供了一种计算机程序产品,当计算机程序产品在机器 人上运行时,使得机器人执行上述第一方面中任一项所述的音乐播放方法。 可以理解的是,上述第二方面至第五方面的有益效果可以参见上述第一方面中的 相关描述,在此不再赘述。 附图说明 为了更清楚地说明本申请实施例中的技术方案,下面将对实施例或现有技术描述 中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些 实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些 7 CN 111597378 A 说 明 书 5/12 页 附图获得其他的附图。 图1是本申请实施例一提供音乐播放方法的流程示意图; 图2-a是本申请实施例二提供音乐播放方法的流程示意图; 图2-b是本申请实施例二提供第二预设神经网络模型的示意图; 图2-c是本申请实施例二提供的人脸所在的区域的示意图; 图2-d是本申请实施例二提供对人脸进行姿态校正前后的对比示意图; 图3是本申请实施例三提供的音乐播放装置的结构示意图; 图4是本申请实施例四提供的机器人的结构示意图。











