
技术摘要:
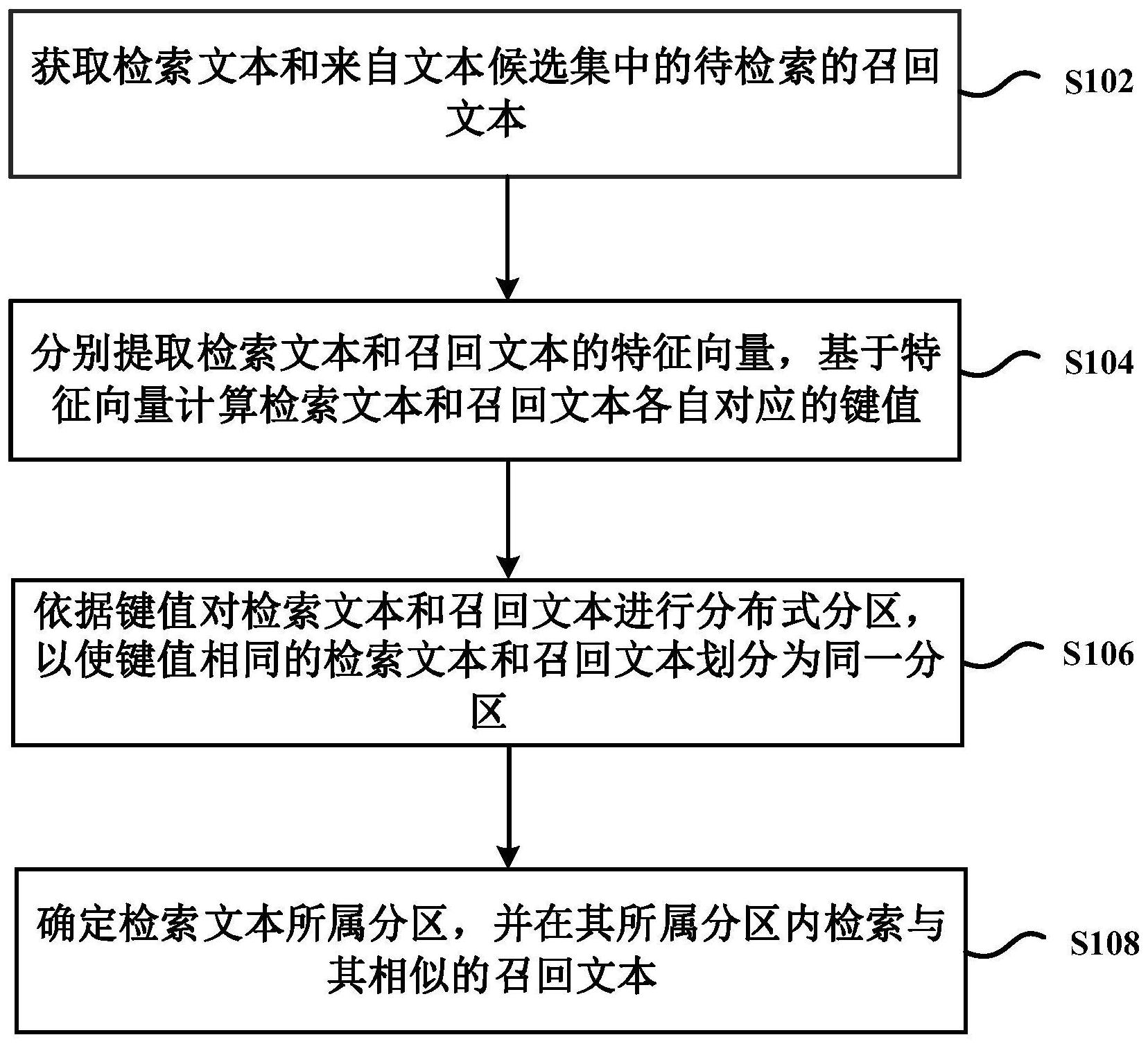
本发明提供了一种分布式相似句对的检索方法及装置,该方法包括:获取检索文本和来自文本候选集中的待检索的召回文本,然后分别提取检索文本和召回文本的特征向量,基于特征向量计算检索文本和召回文本各自对应的键值,进而依据键值对检索文本和召回文本进行分布式分区 全部
背景技术:
现有技术中,从海量的文本数据中检索出语义相似的文本具有广泛的应用,比如 可以应用在人机交互、搜索等场景中,可以用于亿级query特征向量对亿级网页title特征 向量做相似性召回。但是,该项技术一直是相关领域中的一个技术难点。 传统的检索方式是直接计算出特征向量之间的点积距离或者欧式距离并做排序, 例如在搜索场景中,用户的搜索是一个短文本query,待检索的全量的网页对应的网页列表 中包含相应的title,若要利用query召回出最相似的title,现有技术通常是将query和所 有的title做匹配,即直接将query的特征向量和title的特征向量做点积(矩阵乘矩阵),但 是,这种检索方式比较适应于单机且网页数据量有限的场景,而并不适合处理海量数据。目 前采用局部敏感哈希(LSH,Locality Sensitive Hashing)虽然可以更快的对检索结果进 行召回,但是计算过程仍然不适用分布式的全量召回。
技术实现要素:
鉴于上述问题,提出了本发明以便提供一种克服上述问题或者至少部分地解决上 述问题的分布式相似句对的检索方法及装置。 依据本发明一方面,提供了一种分布式相似句对的检索方法,包括: 获取检索文本和来自文本候选集中的待检索的召回文本; 分别提取所述检索文本和所述召回文本的特征向量,基于特征向量计算所述检索 文本和所述召回文本各自对应的键值; 依据所述键值对所述检索文本和所述召回文本进行分布式分区,以使键值相同的 检索文本和召回文本划分为同一分区; 确定所述检索文本所属分区,并在其所属分区内检索与其相似的召回文本。 可选地,获取检索文本和来自文本候选集中的待检索的召回文本,包括: 基于用户输入的搜索query获取所述检索文本; 调用包含待检索的召回文本的文本候选集,从所述文本候选集中获取召回文本。 可选地,基于特征向量计算所述检索文本和所述召回文本各自对应的键值,包括: 采用目标哈希函数对所述检索文本和所述召回文本的特征向量分别进行量化计 算,以得到相应的哈希值; 利用计算得到的哈希值分别作为所述检索文本和召回文本的键值。 可选地,基于特征向量计算所述检索文本和所述召回文本各自对应的键值之前, 还包括: 调取预置的哈希函数集合; 4 CN 111597295 A 说 明 书 2/10 页 从调取的所述哈希函数集合中获取所述目标哈希函数。 可选地,确定所述检索文本所属分区,并在其所属分区内检索与其相似的召回文 本,包括: 若所述检索文本包含多个,分别确定各检索文本所属分区; 将确定后的不同分区包含的检索文本和召回文本分别发送至不同计算节点; 各个计算节点从接收到的召回文本中检索与接收的检索文本相似的召回文本。 可选地,确定所述检索文本所属分区,并在其所属分区内检索与其相似的召回文 本,包括: 确定所述检索文本所属分区,计算所述检索文本与其所属分区内的召回文本的相 似度值; 从所述召回文本中选取相似度值大于预设相似度值的召回文本。 可选地,从所述召回文本中选取相似度值大于预设相似度值的召回文本之后,还 包括: 按照相似度值的大小对选取的召回文本进行排序; 选取排名前N的召回文本,将所述排名前N的召回文本作为所述检索文本的相似句 对检索结果,其中,N为正整数。 依据本发明另一方面,还提供了一种分布式相似句对的检索装置,包括: 第一获取模块,适于获取检索文本和来自文本候选集中的待检索的召回文本; 计算模块,适于分别提取所述检索文本和所述召回文本的特征向量,基于特征向 量计算所述检索文本和所述召回文本各自对应的键值; 分区模块,适于依据所述键值对所述检索文本和所述召回文本进行分布式分区, 以使键值相同的检索文本和召回文本划分为同一分区; 检索模块,适于确定所述检索文本所属分区,并在其所属分区内检索与其相似的 召回文本。 可选地,所述第一获取模块还适于: 基于用户输入的搜索query获取所述检索文本; 调用包含待检索的召回文本的文本候选集,从所述文本候选集中获取召回文本。 可选地,所述计算模块还适于: 采用目标哈希函数对所述检索文本和所述召回文本的特征向量分别进行量化计 算,以得到相应的哈希值; 利用计算得到的哈希值分别作为所述检索文本和召回文本的键值。 可选地,还包括: 调取模块,适于在所述计算模块基于特征向量计算所述检索文本和所述召回文本 各自对应的键值之前,调取预置的哈希函数集合; 第二获取模块,适于从调取的所述哈希函数集合中获取所述目标哈希函数。 可选地,所述检索模块还适于: 若所述检索文本包含多个,分别确定各检索文本所属分区; 将确定后的不同分区包含的检索文本和召回文本分别发送至不同计算节点; 各个计算节点从接收到的召回文本中检索与接收的检索文本相似的召回文本。 5 CN 111597295 A 说 明 书 3/10 页 可选地,所述检索模块还适于: 确定所述检索文本所属分区,计算所述检索文本与其所属分区内的召回文本的相 似度值; 从所述召回文本中选取相似度值大于预设相似度值的召回文本。 可选地,还包括: 排序模块,适于在所述检索模块从所述召回文本中选取相似度值大于预设相似度 值的召回文本之后,按照相似度值的大小对选取的召回文本进行排序; 选取模块,适于选取排名前N的召回文本,将所述排名前N的召回文本作为所述检 索文本的相似句对检索结果,其中,N为正整数。 依据本发明再一方面,还提供了一种计算机存储介质,所述计算机存储介质存储 有计算机程序代码,当所述计算机程序代码在计算设备上运行时,导致所述计算设备执行 上文任意实施例中的分布式相似句对的检索方法。 依据本发明又一方面,还提供了一种计算设备,包括:处理器;存储有计算机程序 代码的存储器;当所述计算机程序代码被所述处理器运行时,导致所述计算设备执行上文 任意实施例中的分布式相似句对的检索方法。 在本发明实施例中,在进行相似句对的检索过程中可以先获取检索文本和来自文 本候选集中的待检索的召回文本,然后分别提取检索文本和召回文本的特征向量,基于特 征向量计算检索文本和召回文本各自对应的键值,进而依据键值对检索文本和召回文本进 行分布式分区,以使键值相同的检索文本和召回文本划分为同一分区,最后确定检索文本 所属分区,并在其所属分区内检索与其相似的召回文本。由此,本发明实施例通过依据键值 对检索文本和召回文本进行分布式分区,并使得同一分区内的检索文本和召回文本的键值 相同,由于键值相同的文本的特征向量是相似的,因此在分区内进行文本的检索可以有效 地缩小文本的检索范围,即缩小了文本的召回空间,进而在后续可以更加快速地检索到与 检索文本相似的召回文本。进一步地,不同分区内的检索文本在检索过程中可以互不干涉, 并行的利用各分区内的检索文本检索与其同一分区中的召回文本,既提高了检索文本的检 索效率,又节约了检索文本的检索时间。 上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段, 而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够 更明显易懂,以下特举本发明的











