
技术摘要:
本公开提供了一种对数据集中的数据表进行抽样和校验的方法及装置。该数据集包括多个数据表,多个数据表具有多个共同指标。上述对数据集中的数据表进行抽样的方法包括:获取多个共同指标针对多个数据表中每个数据表的取值,得到针对每个数据表的一组取值;根据预定模型 全部
背景技术:
数据湖作为源业务系统数据库的缓存,采用原始格式进行数据存储的方式避免了 对原始数据进行加工或处理导致的数据不准确或者数据结构失真等问题。数据湖高质量数 据的重要性不言而喻,其中数据湖海量结构化数据和源业务系统的数据一致性又是数据质 量衡量的一项重要内容。 在实现本公开构思的过程中,发明人发现现有技术中至少存在如下问题:大型机 构的数据湖能够存储的数据量能够达到10PB(1PB=1024TB)级,若采取全量数据一致性比 较的方式会十分复杂,需要从各个源业务应用系统数据库中获取全量数据,然后和数据湖 中的数据表进行逐一对比数据一致性,这种方式虽然能检验所有的入湖数据,但是却耗费 大量的时间和人力资源,且验证过的数据表不一定会出现在当期的业务使用中,因此用全 量数据进行数据一致性校验会产生大量额外且不必要的工作。
技术实现要素:
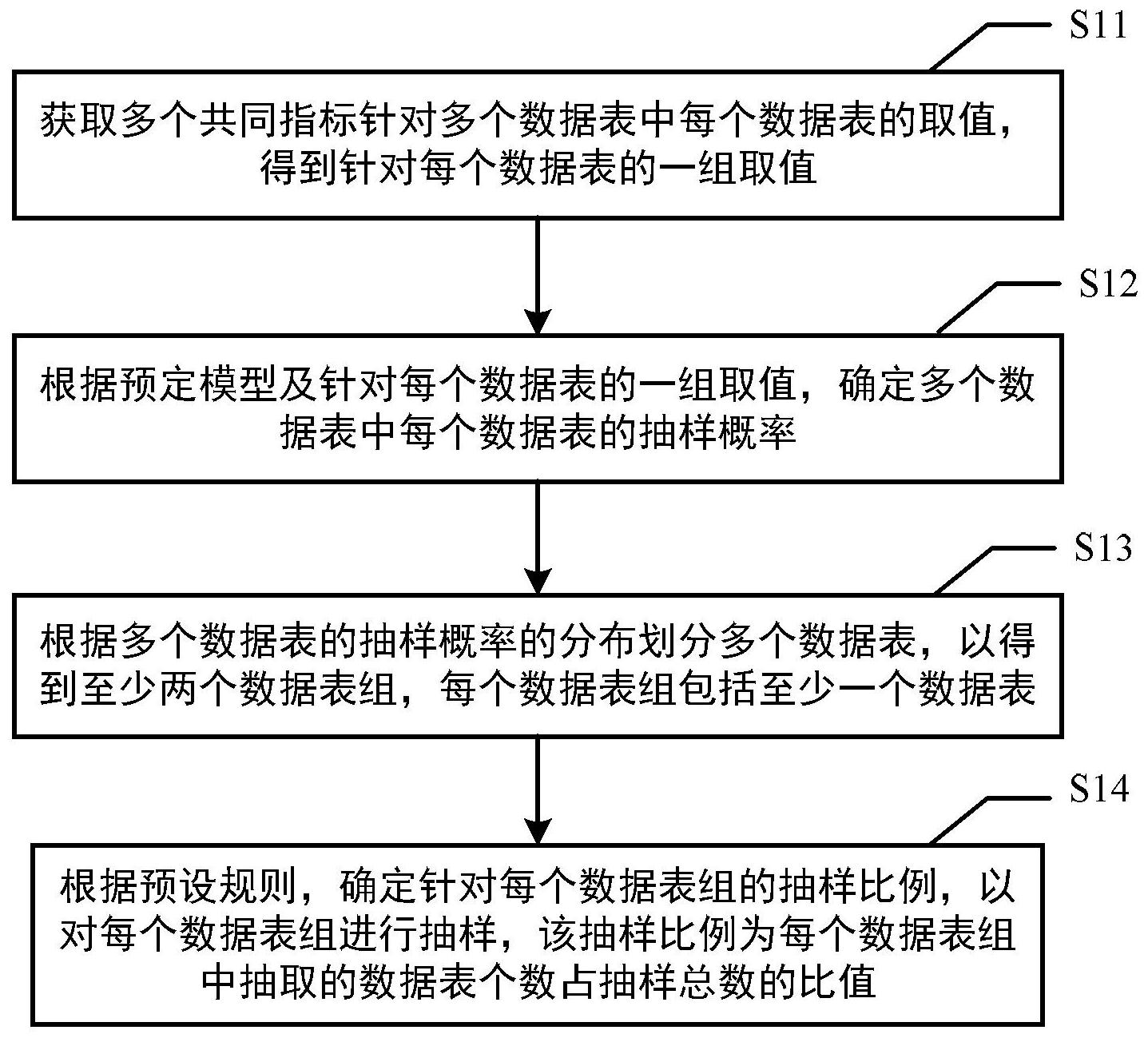
有鉴于此,本公开提供了一种能够高效且准确地对大型数据集中的数据表进行抽 样和校验的方法、装置、电子设备及计算机可读存储介质。 本公开的第一个方面提供了一种对数据集中的数据表进行抽样的方法。该数据集 包括多个数据表,多个数据表具有多个共同指标。上述方法包括:获取多个共同指标针对多 个数据表中每个数据表的取值,得到针对每个数据表的一组取值;根据预定模型及针对每 个数据表的一组取值,确定多个数据表中每个数据表的抽样概率;根据多个数据表的抽样 概率的分布划分多个数据表,以得到至少两个数据表组,每个数据表组包括至少一个数据 表;以及根据预设规则,确定针对每个数据表组的抽样比例,以对每个数据表组进行抽样, 该抽样比例为每个数据表组中抽取的数据表个数占抽样总数的比值。 根据本公开的实施例,上述方法还包括:构建预定模型。上述构建预定模型包括: 确定数据集中用于构建预定模型的多个样本数据表;获取多个共同指标针对多个样本数据 表中每个样本数据表的取值,得到分别对应多个样本数据表的多组取值;获取多个样本数 据表各自的实际抽样概率;以多组取值作为样本数据输入至初始模型,对应得到多个样本 数据表各自的预测抽样概率;以及根据多个样本数据表各自的预测抽样概率及各自的实际 抽样概率,优化初始模型,以得到预定模型;其中,初始模型采用的算法为逻辑回归算法。 根据本公开的实施例,根据多个数据表的抽样概率的分布划分多个数据表包括: 根据多个数据表的抽样概率的分布确定抽样概率分布的极差,极差为抽样概率的最大值与 最小值的差;根据抽样概率的大小顺序对多个数据表进行排序;根据预设组数和极差确定 组距;以及以组距等距划分排序后的多个数据表,得到至少两个数据表组。 4 CN 111581197 A 说 明 书 2/14 页 根据本公开的实施例,根据预设规则,确定针对每个数据表组的抽样比例,以对每 个数据表组进行抽样包括:确定每个数据表组中所有数据表的抽样概率的平均值,得到针 对每个数据表组的平均概率值;根据平均概率值自大到小,向至少两个数据表组分配自大 到小的编号;确定向至少两个数据表组分配的编号的总和;以及确定针对每个数据表组的 抽样比例为每个数据表组的编号与总和的比值。 本公开的第二个方面提供了一种对数据集中的数据表进行校验的方法。该方法包 括:从源数据库中获取标准数据表;基于上述提及任一种抽样的方法从数据湖中的数据集 抽取数据表,以得到待校验数据表,数据湖中的数据表通过缓存源数据库中的标准数据表 得到;以及将待校验数据表与标准数据表进行一致性校验。 根据本公开的实施例,将待校验数据表与标准数据表进行一致性校验,包括以下 至少之一:校验待校验数据表与标准数据表中的表信息是否一致;校验待校验数据表中的 主键是否重复。表信息包括:表名、表中的字段以及表的记录,表中的字段包括:字段名、字 段类型及字段属性。上述主键用于唯一识别表的记录。 本公开的第三个方面提供了一种对数据集中的数据表进行抽样的装置。该数据集 包括多个数据表,多个数据表具有多个共同指标。上述装置包括:共同指标取值获取模块, 用于获取多个共同指标针对多个数据表中每个数据表的取值,得到针对每个数据表的一组 取值;数据表抽样概率确定模块,用于根据预定模型及针对每个数据表的一组取值,确定多 个数据表中每个数据表的抽样概率;数据表分组模块,用于根据多个数据表的抽样概率的 分布划分多个数据表,以得到至少两个数据表组,每个数据表组包括至少一个数据表;以及 抽样模块,用于根据预设规则,确定针对每个数据表组的抽样比例,以对每个数据表组进行 抽样,该抽样比例为每个数据表组中抽取的数据表个数占抽样总数的比值。 本公开的第四个方面提供了一种对数据集中的数据表进行校验的装置。该装置包 括:标准数据表获取模块,用于从源数据库中获取标准数据表;待校验数据表获取模块,用 于基于上述提及的任一种抽样的方法从数据湖中的数据集抽取数据表,以得到待校验数据 表,数据湖中的数据表通过缓存源数据库中的标准数据表得到;以及一致性校验模块,用于 将待校验数据表与标准数据表进行一致性校验。 本公开的第五个方面提供了一种电子设备。该电子设备包括:一个或多个处理器; 存储器,用于存储一个或多个计算机程序;其中,当一个或多个计算机程序被一个或多个处 理器执行时,使得一个或多个处理器实现如上所述的方法。 本公开的第六个方面提供了一种计算机可读存储介质,其上存储有可执行指令, 其中,该指令被处理器执行时使处理器实现如上所述的方法。 本公开的第七个方面提供了一种计算机程序,该计算机程序包括计算机可执行指 令,所述指令在被执行时用于实现如上所述的方法。 根据本公开的实施例,可以至少部分地解决相关技术中对大容量的数据互中存储 的数据进行一致性比较时所存在的需要耗费大量人力和时间的问题,通过根据能够反映数 据表被抽取时的相对重要程度的抽样概率的分布来对多个数据表进行分组,可以使得多个 数据表的分组能够反映各个数据表的相对重要程度,之后通过对每个数据表组按照抽样比 例进行抽样,可以使得抽样得到的数据表具有较好的代表性,以保证后续对数据集中数据 和源业务系统中数据进行一致性校验时校验结果的准确性。 5 CN 111581197 A 说 明 书 3/14 页 附图说明 为了更完整地理解本公开及其优势,现在将参考结合附图的以下描述,其中: 图1示意性示出了根据本公开实施例的对数据集中的数据表进行抽样和校验的方 法及装置的应用场景; 图2示意性示出了根据本公开实施例的数据集的结构框图; 图3示意性示出了根据本公开实施例的对数据集中的数据表进行抽样的方法的流 程图; 图4示意性示出了图3所示的方法中操作S13的详细流程图; 图5示意性示出了图3所示的方法中操作S14的详细流程图; 图6示意性示出了图3所示的方法中还包括构建预定模型的操作S10的示意图; 图7示意性示出了根据本公开实施例的构建预定模型的流程图; 图8示意性示出了根据本公开实施例的对数据集中的数据表进行抽样的装置的框 图; 图9示意性示出了根据本公开实施例的对数据集中的数据表进行校验的方法流程 图; 图10示意性示出了根据本公开实施例的对数据集中的数据表进行校验的装置流 程图;以及 图11示意性示出了根据本公开实施例的适于实现上文描述的方法的电子设备的 方框图。











