
技术摘要:
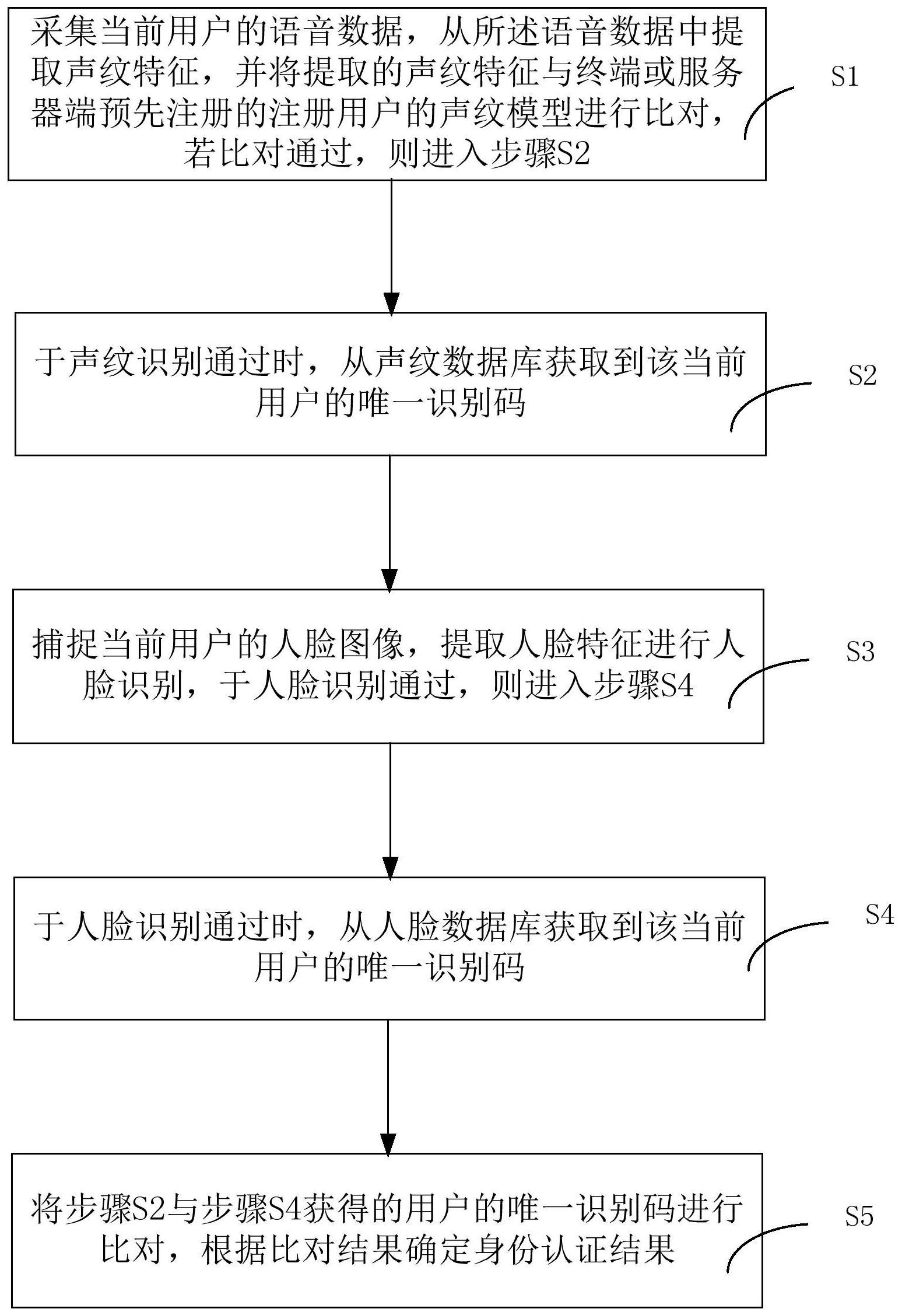
本发明公开了一种人脸声纹复核终端及其身份认证方法,所述方法包括如下步骤:步骤S1,采集当前用户的语音数据,从所述语音数据中提取声纹特征,并将提取的声纹特征与终端或服务器端预先注册的注册用户的声纹模型进行比对,若比对通过,则进入步骤S2;步骤S2,于声纹识 全部
背景技术:
随着移动互联网的高速发展以及手持终端设备如智能手机、平板电脑的普及,互 联网安全问题日益突出,目前,无论是银行的硬件数字证书还是动态口令牌,都只做到了对 可信终端的管理,无法对用户身份进行验证。 生物特征识别技术是利用人的生理特征或行为特征来进行个人身份的鉴定,目 前,已被用于生物识别的生物特征有声音、指纹、人脸、虹膜等,由于麦克风和摄像头普遍存 在于现有的移动终端,因此,通过声音或者人脸识别来进行身份认证是目前最方便、最经济 的解决方案。 其中,人脸识别技术是一种依据人的面部特征(如统计或几何特征等),自动进行 身份识别的一种生物识别技术。人脸识别利用摄像头采集含有人脸的图像或视频流,并自 动在图像中检测和跟踪人脸,再进一步对检测到的人脸图像进行相关的应用操作。技术上 包括图像采集、特征定位、身份的确认和查找等等。简单来说,就是从照片中提取人脸中的 特征,比如眉毛高度、嘴角等等,再通过已保存的特征进行对比输出结果。 人的声音涵盖了多个维度的信息,如说话内容、说话语气、声音特质等。声纹是指 对语音中所包含的、能够标明、标识说话人的语音特征,并基于这些语音特征所建立的语音 模型的一个总称,声纹识别是一种通过人的声音特质来辨别不同说话人的技术,不同的声 道结构决定了声纹的唯一性。声纹识别主要包括两大模块:声纹注册模块和声纹认证模块。 声纹注册是指采用预先选定的模型对用户的语音样本进行建模,生成该用户的声纹模型; 在用户请求身份验证时,利用对应的声纹模型对请求语音进行认证。 然而,目前的生物特征识别技术存在一些缺点: 1、对于人脸识别技术,攻击者可以通过外部攻击的手段来破解,如:照片攻击,通 过打印高清照片来模拟用户;视频攻击,录制一段用户的面部视频,在摄像头前播放;立体 面具攻击,使用普通的塑料或硬纸做成面具,将面具模拟成用户; 2、对于声纹识别技术,攻击者往往将用户的声音通过录音设备录制,在攻击时再 将录音播放进行破解。
技术实现要素:
为克服上述现有技术存在的不足,本发明之目的在于提供一种人脸声纹复核终端 及其身份认证方法,以通过将声纹识别和人脸识别技术组合使用,提高身份识别的准确度 和安全性。 为达上述及其它目的,本发明提出一种人脸声纹复核终端,包括: 声纹识别验证单元,用于采集当前用户的语音数据,从所述语音数据中提取声纹 4 CN 111611568 A 说 明 书 2/7 页 特征,并将提取的声纹特征与终端或服务器端预先注册的注册用户的声纹模型进行比对, 若比对通过,则进入第一匹配单元; 第一匹配单元,用于于声纹识别通过时,从预先建立的声纹数据库获取到该当前 用户的唯一识别码 人脸捕捉验证单元,用于捕捉当前用户的人脸图像,提取人脸特征进行人脸识别, 于人脸识别通过,则进入第二匹配单元; 第二匹配单元,用于于人脸识别通过时,从预先建立的人脸数据库获取到该当前 用户的唯一识别码 比对单元,用于将所述第一匹配单元与第二匹配单元获得的用户的唯一识别码进 行比对,根据比对结果确定身份认证结果。 优选地,所述声纹识别验证单元进一步包括: 声纹特征提取模块,用于采集当前用户的语音数据,提取声纹特征; 声纹识别认证模块,用于计算所述声纹特征提取模块所提取的声纹特征与终端或 服务器端预先注册的注册用户的声纹模型之间的相似度,并判断声纹相似度是否大于预设 阈值,若大于预设阈值,则进入所述第一匹配单元。 优选地,所述人脸捕捉验证单元包括: 人脸捕捉模块,用于采集当前用户人脸图像,根据人脸图像确定人脸区域,于确定 的人脸区域标定面部关键点; 人脸识别认证模块,用于根据关键点特征计算该用户的人脸与预先存储的注册用 户的人脸模型的相似度,判断人脸相似度是否大于预设的阈值,若人脸相似度大于阈值则 人脸认证通过,进入所述第二匹配单元。 优选地,所述终端还包括: 人脸注册单元,用于采集注册用户的人脸图像样本,根据人脸图像样本建立注册 用户的人脸模型; 声纹注册单元,用于采集注册用户的语音数据,对语音数据提取声纹特征,建立注 册用户的声纹模型; 人脸数据库建立单元,用于建立人脸数据库,于所述人脸数据库中,对每个注册用 户建立唯一识别码及其对应的人脸特征的映射关系; 声纹数据库建立单元,用于建立声纹数据库,于所述声纹数据库中,对每个注册用 户建立唯一识别码及其对应的声纹特征的映射关系 为达到上述目的,本发明还提供一种人脸声纹复核终端的身份认证方法,包括如 下步骤: 步骤S1,采集当前用户的语音数据,从所述语音数据中提取声纹特征,并将提取的 声纹特征与终端或服务器端预先注册的注册用户的声纹模型进行比对,若比对通过,则进 入步骤S2; 步骤S2,于声纹识别通过时,从预先建立的声纹数据库获取到该当前用户的唯一 识别码; 步骤S3,捕捉当前用户的人脸图像,提取人脸特征进行人脸识别,于人脸识别通 过,则进入步骤S4; 5 CN 111611568 A 说 明 书 3/7 页 步骤S4,于人脸识别通过时,从预先建立的人脸数据库获取到该当前用户的唯一 识别码; 步骤S5,将步骤S2与步骤S4获得的用户的唯一识别码进行比对,根据比对结果确 定身份认证结果。 优选地,于步骤S5中,若比对结果为两者一致,则本次身份验证通过,若两者结果 不一致,则提示本次身份验证失败。 优选地,步骤S1进一步包括: 步骤S100,采集当前用户的语音数据,提取声纹特征; 步骤S101,计算声纹特征提取模块所提取的声纹特征与终端或服务器端预先注册 的注册用户的声纹模型之间的相似度,并判断声纹相似度是否大于预设阈值,若大于预设 阈值,进入步骤S2,否则提示声纹验证失败。 优选地,步骤S3进一步包括: 步骤S300,采集当前用户人脸图像,根据人脸图像确定人脸区域,于确定的人脸区 域标定面部关键点; 步骤S301,根据关键点特征计算该当前用户的人脸特征与预先存储的注册用户的 人脸模型的相似度,判断人脸相似度是否大于预设的阈值,若人脸相似度大于阈值则人脸 认证通过,进入步骤S4,否则提示人脸识别验证失败。 优选地,于步骤S1之前,还包括如下步骤: 步骤S01,采集注册用户的人脸图像样本,根据人脸图像样本建立注册用户的人脸 模型; 步骤S02,采集注册用户的语音数据,对语音数据提取声纹特征,建立注册用户的 声纹模型; 步骤S03,建立人脸数据库,于所述人脸数据库中,对每个注册用户建立唯一识别 码及其对应的人脸特征的对应关系; 步骤S04,建立声纹数据库,于所述声纹数据库中,对每个注册用户建立唯一识别 码及其对应的声纹特征的对应关系。 与现有技术相比,本发明一种人脸声纹复核终端及其身份认证方法通过采集用户 语音数据进行声纹识别,于声纹识别通过后从预先建立的声纹数据库获取到该当前用户的 唯一识别码,然后通过采集人脸图像进行人脸识别,于人脸识别通过时,从预先建立的人脸 数据库获取到该当前用户的唯一识别码,最后将根据声纹识别获得的用户唯一识别码与根 据人脸识别获得的用户唯一识别码进行比对,根据比对结果确定身份认证结果,实现了人 脸与声纹双重认证的身份认证方式,通过本发明,可提高用户身份验证通过的准确度,增强 抗外部攻击的安全性。 附图说明 图1为本发明一种人脸声纹复核终端的结构示意图; 图2为本发明一种人脸声纹复核终端的身份认证方法的步骤流程图; 图3为本发明实施例中脸声纹复核终端的身份认证流程图。 6 CN 111611568 A 说 明 书 4/7 页











