
技术摘要:
本发明提供一种基于自注意力机制模范生成对抗网络的人脸图像眼部补全方法,属于机器学习领域。首先选取一张属于同一身份的人的不同姿态的脸部照片作为参考,将对应的参考图像、参考图像的眼部、缺失图像、缺失图像的眼部以及10维的噪声向量输入到我们所构建的模型的生 全部
背景技术:
随着越来越多图像的产生,随之而来的问题也越来越多。在图像采集时可能由于 光照、设备、存储介质和图像传输过程的压缩等问题,导致图像受损或者受到噪声困扰,而 图像受损后的视觉表现效果较差,受损严重的图像更会导致人不能正确理解其要表达的内 容。因此图像修复是很多计算机视觉任务预处理的重要步骤之一,图像修复结果与目标追 踪、目标检测、图像分割等任务结果有直接联系。 图像补全是指利用缺失区域的周围图像信息按照一定的规则来对图像的缺失区 域进行填补以此生成完整的图像,并使得补全后的照片在视觉上真实语义上正确。并且它 还可以扩展到许多其他方面,比如图像或视频的剪裁、旋转、缝合、重新定位、重新合成、压 缩、超分辨率、去雨、去雾等。日常生活中,在拍照的时候不小心闭上眼睛,此时就可以通过 图像补全技术来使得人的眼睛睁开。摄影与影视领域,遇到图像损坏的问题,由于费用、时 间等一系列原因,不可能重新拍摄,此时就可以通过图像补全技术对损坏的照片或者视频 进行修复以供人们使用。医疗领域中,通过对模糊的医学影像进行修复,使其成为更加清晰 的影像以供医生诊断。刑侦领域中,警方拥有的嫌疑人的图片被故意遮挡,通过采用技术手 段将图像修复以抓捕嫌疑人。因此如何修复图像使图像变得视觉上完整且语义上正确是一 个具有重要应用价值的问题。 图像补全的目标是通过二进制掩模和自然图像来重构损坏的图像中的缺失区域, 从而生成真实的、自然的完整图像。传统的方法已经可以生成的相应的缺失部位,但这些的 传统方法只能在低层的局部外观上进行处理,无法利用图像中的高层语义信息,所以生成 缺失区域的详细结构及其边界比较模糊。 Pathak等人结合编码-解码器网络结构和GAN(Goodfellow I,Pouget-Abadie J, Mirza M,et al.Generative adversarial nets[C]//Advances in neural information processing systems .2014:2672-2680 .)提出了新的网络模型——上下文编码器 (Context Encoder,CE)(Pathak D,Krahenbuhl P,Donahue J,et al.Context encoders: Feature learning by inpainting[C]//Proceedings of the IEEE conference on computer vision and pattern recognition.2016:2536-2544.),其中CE用来学习图像特 征并生成缺失区域的预测图像,而GAN用来判别预测图像是CE生成的,还是来自训练集的。 当GAN无法判别是真实的图片还是CE生成的,本发明就认为网络达到了最佳状态,并且使用 了联合损失函数,将重构损失与生成对抗损失结合起来。虽然CE可以生成高质量的补全图 片,但只能处理矩形形状的缺失区域,不能处理任意形状的缺失区域,同时也不可以将CE应 用在高分辨率的图像。在 CE的基础上,Lizuka等人在他们的网络模型中采用了堆叠式的空 4 CN 111738940 A 说 明 书 2/6 页 洞卷积,并借助全局和局部一致性图像补全算法来生成高质量的结果(Iizuka S ,Simo- Serra E, Ishikawa H.Globally and locally consistent image completion[J].ACM Transactions on Graphics(ToG) ,2017,36(4):1-14.)。通过局部鉴别器、整体鉴别器与生 成器G 来进行图像修复,生成器G负责生成完整图片,整体判别器判别整体图像是否一致, 局部鉴别器负责判别生成的缺失区域与周围区域的纹理是否一致,然后迭代训练网络,使 得全局鉴别器与局部鉴别器不能区分出所输入的图像无论整体还是局部,是虚假的还是真 实的。该模型可以较好的生成完整图像,但是不能够生成复杂的结构纹理,以及训练时间过 久,不易收敛。Dolhansky等人通过一个符合现实情况的假定,即同一个人的多张不同姿态 的图片是很容易获得的,提出了范例GAN(Exemplar Generative Adversarial Networks, ExGAN)(Dolhansky B,Canton Ferrer C.Eye in-painting with exemplar generative adversarial networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition.2018:7902-7911.)。图1.1是范例生成对抗网络的结构 示意图。如图 ExGAN使用额外的参考信息来辅助模型的训练。ExGAN可以较好的生成缺失眼 睛部位,但是生成眼部区域并没关注广域的信息。 注意力机制已经成为必须捕捉广域依赖性的模型的组成成分之一。自我注意通过 关注同一序列中的所有位置来计算序列中某个位置的反应。Vaswani等人的研究表明仅使 用自注意力机制可以在机器翻译任务中取得目前最好的结果 (Vaswani A ,Shazeer N , Parmar N,et al.Attention is all you need[C]//Advances in neural information processing systems.2017:5998-6008.);Parmar等人提出了一种图像转换器模型,以将自 注意力添加到用于图像生成的自回归模型中(Parmar N , Vaswani A ,Uszkoreit J ,et al.Image transformer[J].arXiv preprint arXiv:1802.05751, 2018.);Wang等人将自 注意力形式化为一种非本地操作,以对视频序列中的时空依赖性进行建模(Wang X , Girshick R ,Gupta A ,et al .Non-local neural networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition.2018:7794-7803.); AttnGAN使用输入序列中单词嵌入的注意力,而不是内部模型状态的自我关注(Xu T,Zhang P ,Huang Q ,et al .Attngan: Fine-grained text to image generation with attentional generative adversarial networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition.2018:1316-1324.);而自注 意力机制则在图像的内部表示中有效地找到了广域的、长期的依赖关系。
技术实现要素:
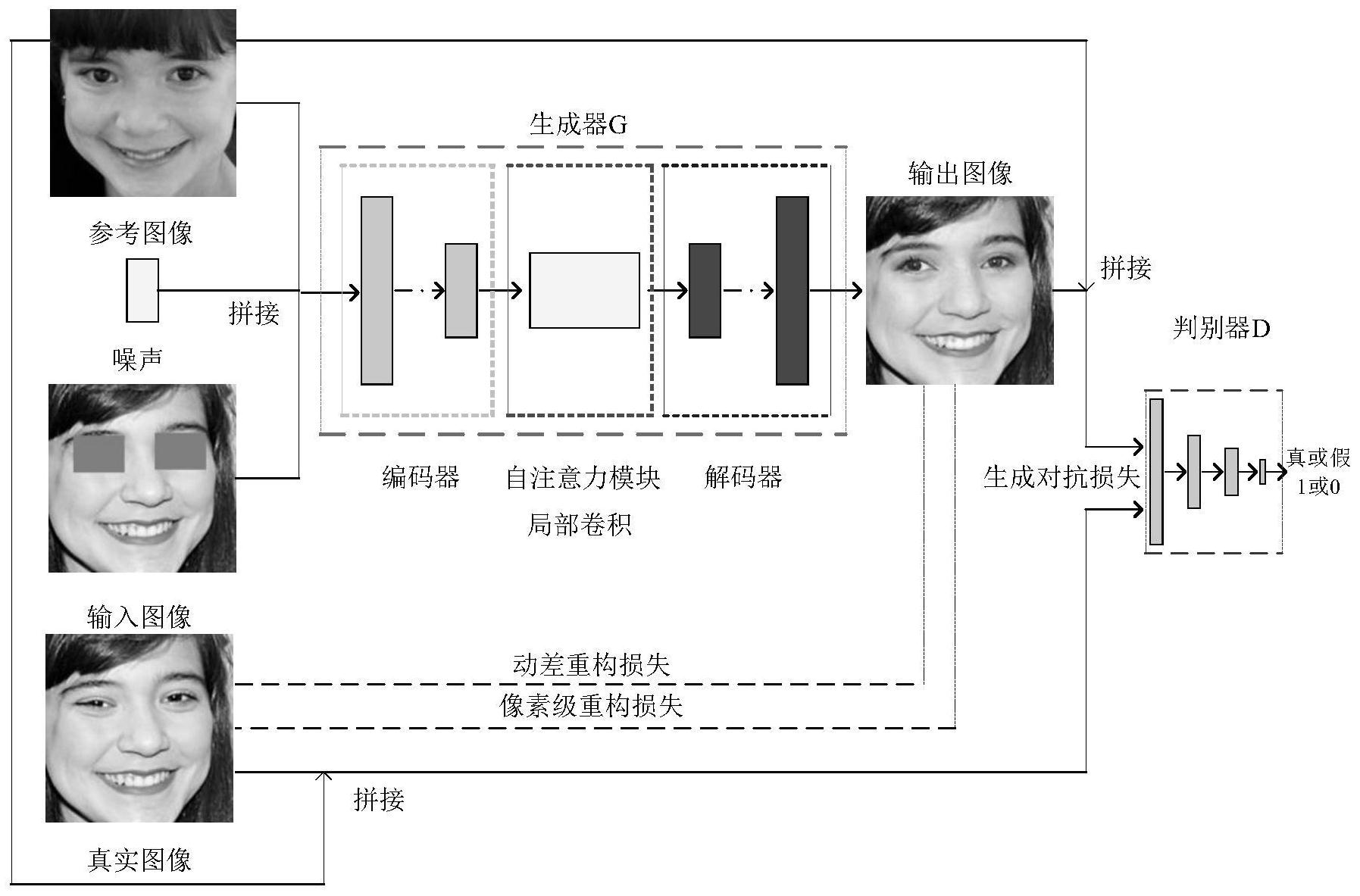
针对之前的图像补全模型没有关注广域的依赖关系,对一些结构复杂的类的细节 不能够很好的建模以及在卷积时,填充的元素可能对卷积结果是有害的等问题,本发明提 供一种基于自注意力机制机制的模范生成对抗网络 (ExSAGAN)用于人脸图像眼部补全。该 方法在相应数据集上的实验结果显示在FID、SSIM、MS-SSIM、PSNR和UQI等5项指标上均取得 了较好的结果,此外本发明还将本发明在图像上的补全结果与商业图像编辑软件Adobe Photoshop Elements 2019(APSE2019)的睁开闭眼功能进行了对比,结果显示本发明的模 型效果更好,而APES2019则只是简单的将参照图像的眼睛直接复制到缺失图像上。 为了达到上述目的,本发明采用的技术方案为: 5 CN 111738940 A 说 明 书 3/6 页 一种基于自注意力机制模范生成对抗网络的人脸图像眼部补全方法,所述人脸图 像眼部补全方法能够较好的生成人脸缺失眼部区域,使用自注意力机制能够自适应地关注 显著性,包括如下步骤: 步骤1:提取同一身份的参考图像的眼部区域,将参考图像、参考图像的眼部区域、 输入图像、输入图像的眼部区域和10维噪声向量作为生成网络的输入,输入到生成器G中, 生成器G根据输入信息经过卷积和反卷积操作之后,生成 K张不同的补全图像,此时再利用 动差重构损失,从K张输出的图像中找出与真实图像最相近似的补全图像,其中K预先设定 的,为2-4张。 所述的生成器G由编码器模块、自注意力模块、解码器模块组成,其中编码器模块 由卷积层构成,自注意力模块由残差网络和自注意力机制构成,自注意力机制应用在相邻 的残差块之间,解码器模块由反卷积层构成。具体过程为:首先,所述缺失图像、参考图像、 缺失图像的眼部、参考图像的眼部和10维噪声向量串联后,输入三个卷积层中:第一个卷积 层是采用局部卷积,应用谱归一化和ReLU激活函数;第二个卷积层与第一个卷积层的实现 相同,但卷积核大小及步长不同;第三个卷积层与第二个卷积层的实现完全相同。然后将其 输入到6个残差块中,其中在第三个和第四个残差块之间还有一个自注意力模块,当从第六 个残差块输出时,张量的维度保持不变;再经过两个转置卷积层,采用谱归一化、ReLU进行 激活后输入到第四个卷积层中,最终生成器G根据输入信息经过卷积和反卷积操作之后,生 成K张不同的补全图像,此时再利用动差重构损失,从K张输出的图像中找出与真实图像最 相近似的补全图像。 进一步的,所述的第一个卷积层卷积核的大小为7×7,步长为1;所述的第二个卷 积层卷积核的大小为4×4,步长为2;所述的第三个卷积层卷积核的大小为4×4,步长为2。 所述的转置卷积层卷积核的大小为5×5,步长为2。所述的第四个卷积层不进行归一化操 作,其他与第一个卷积层相同。 进一步的,所述的自注意力机制的工作方式为: 是来自前一个隐藏层 的特征图,其中C是通道数,N是上一个隐藏层中特征的特征位置的数量。如公式1所示,对x 在特征空间f进行1×1卷积,进行线性变换和通道压缩,得到一个张量;对x在特征空间g进 行1×1卷积,进行线性变换和通道压缩,得到第二个张量; f(x)=Wfx,g(x)=Wgx (1) 其中, 和 是需要学习的两个不同的权重矩阵。 将第一个张量矩阵转置后与第二个张量矩阵相乘,再经过softmax得到注意力图, 将原始的x使用另一个1×1卷积h进行线性变换,然后与之前的注意力图矩阵相乘,再通过1 × 1 卷 积 v 进 行 线 性 变 换 ,得 到 自 注 意 力 特 征 图 。其 中 自 注 意 力 特 征 图 的计算方式如公式2和3所示。 6 CN 111738940 A 说 明 书 4/6 页 其中,βj,i是在合成第j个位置时注意第i个位置的程度,sij是中间的注意力图,xi 和xj为输入的特征图, 和 是需要学习的两个不同的权重矩阵。 最后,将自注意力特征图与原始的x进行加权求和,最终输出如公式4所示。 yi=γoi xi (4) 其中,γ是可学习的参数,并且初始化为0。引入可学习的γ可以使网络首先依靠 本地邻域的线索,然后逐渐学习为非局部的邻域分配更多的权重。 步骤2:将步骤1中生成器G生成的补全图像及其眼部与参考图像拼接,或者将真实 图像及眼部与参考图像拼接以后,输入到判别器D中,判别器通过5 层的相同的卷积层和2 层的全连接层,最终输出一个标量0或1,0代表图像是真的,1代表图像是假的。 所述的判别器D的结构为:判别网络的输入为采样自训练集中的样本图像或生成 器G生成的假的图像,经过五个相同的卷积层,卷积层采用局部卷积和 Leaky ReLU,卷积核 的大小为7×7,步长为2,再经过两个全连接层,最终输出 0或1代表图像真或假,其中,输出 0代表图像真,输出1代表图像假。 步骤3:由步骤1的生成器G和步骤2的判别器D完成模型的搭建,并对搭建后的模型 进行训练: 将K张相同的参考图像、K个不同的噪声向量和K张相同的输入图像拼接后输入生 成器G中,生成器G网络中采用的卷积方式为局部卷积,然后生成K 个不同的输出图像,利用 动差重构损失找到与真实图像最相近似的输出图像,接着将其输入到判别器D网络中,判别 真假。训练过程中,交替训练生成器G 和判别器D,在训练生成器G时,固定判别器的所有参 数;在训练判别器时,固定生成器G的所有参数。直到训练最终达到纳什均衡,判别不出输入 的图像是真的还是假的。 步骤4:模型训练完成后,对模型进行测试:将参考图像和输入图像以及噪声拼接 后输入到生成器G网络中,然后生成补全后的输出图像。 本发明的有益效果:基于自注意力机制模范生成对抗网络的人脸图像眼部补全方 法充分利用缺失眼部区域的周围信息,并且可以关注广域信息,实现的眼睛部位并没有简 单的复制参考图像的眼睛部位,而是根据不同身份生成对应的眼睛部位,没有陷入到模式 崩溃问题,生成的人脸图像自然且真实。 附图说明 图1为ExSAGAN方法的结构示意图; 图2为ExSAGAN的生成网络结构示意图; 图3为自注意力机制的示意图; 图4为ExSAGAN的判别网络结构示意图; 图5为ExSAGAN的训练阶段示意图; 图6为ExSAGAN的测试阶段示意图。 7 CN 111738940 A 说 明 书 5/6 页











