
技术摘要:
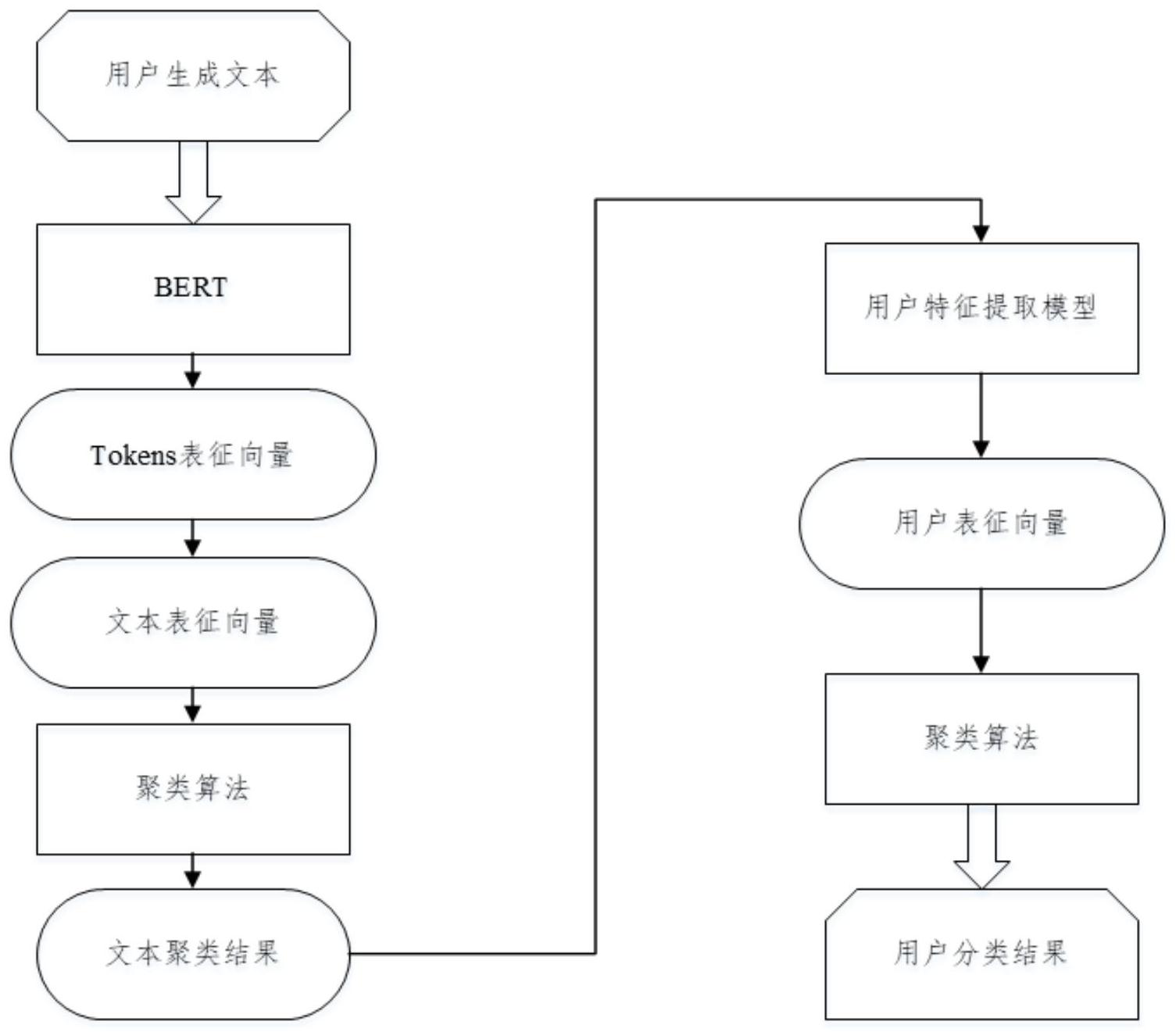
本发明公开了一种基于用户生成文本的无监督学习的用户分类方法,包括:获取用户生成文本,生成文本表征向量;使用无监督聚类算法对所有文本表征向量进行聚类,得到文本聚类结果;将得到的文本聚类结果中的文本类别作为用户特征;计算每一个用户的特征值,得到用户特征 全部
背景技术:
用户分类是数据挖掘的一个重要应用领域,通过将用户划分成不同的类别,确定 不同用户群体的需求,为不同的用户群体推送相应的信息,以实现信息精确的定向推送,个 性化服务、智能营销,社交等。根据互联网用户的相似性,对他们进行分类,可有益于广泛的 应用领域,如个性化服务,智能推荐,智能营销,社交等。 当前最新的技术方案包括基于用户使用应用程序的数据进行用户分类,无监督学 习方法确定用户的拓扑关系特征进而确定用户类别,基于提取的用户画像特征确定用户类 型和对用户操作应用程序的功能序列的词嵌入矩阵进行聚类等。例如公告号为CN 110837862 A的专利公开了一种用户分类方法包括:获取用户在应用中的操作数据,并进行 分析以得到由所述用户在所述应用中顺序使用的功能所组成的功能序列;对所述用户的功 能序列中的每个功能的名称进行词嵌入处理,得到所述每个功能对应的向量;将所述功能 序列中每个功能对应的向量顺序进行组合,得到对应所述用户的功能序列矩阵;对多个用 户分别对应的功能序列矩阵进行聚类处理,得到每个功能序列矩阵对应的用户所属的类 别。通过该发明,能够根据用户使用的功能序列对用户进行准确分类。 但是,这些用户分类方法通常需要花费很大代价设计、提取及处理所需数据且依 赖特定的数据;应用于某种特定的业务场景,通用性不足。
技术实现要素:
为了解决上述存在的技术问题,本发明提出了一种基于用户生成文本的无监督学 习的用户分类方法及装置,不需要标注数据,仅仅基于用户生成文本(UGT)进行两次无监督 聚类即能实现用户分类,方法简单快捷。 本发明的技术方案是: 一种基于用户生成文本的无监督学习的用户分类方法,包括以下步骤: S01:获取用户生成文本,生成文本表征向量; S02:使用无监督聚类算法对所有文本表征向量进行聚类,得到文本聚类结果;将 得到的文本聚类结果中的文本类别作为用户特征; S03:计算用户的特征值,得到用户特征向量; S04:使用无监督聚类算法对用户特征向量进行聚类,得到用户分类。 优选的技术方案中,所述步骤S01中包括以下步骤: S11:获取用户生成文本的每个token对应的表征向量; S12:对文本所有token的表征向量取平均并将结果向量作为文本表征向量,文本 表征向量为768维,用ST=(ST1,ST2,ST3,…,ST768)表示,每一维STi通过下述公式计算: 4 CN 111611376 A 说 明 书 2/6 页 其中,NT表示token的个数, 表示第j个token的表征向量的第i维的值,STi表示 文本表征向量ST的第i维的值。 优选的技术方案中,所述步骤S03中计算用户生成文本在文本类内与对应的类中 心的相似度,得到每一个用户的特征值。 优选的技术方案中,使用欧式距离计算用户特征值U=(F1,F2,…,Fn),每一维Fi用 下述公式计算: 其中,Ni表示某用户生成的文本中被聚类到类别i中的文本个数, 表示Ni中的 第j条文本与类别i的类中心的欧式距离相似度,n表示用户特征数,T是一个预设常量。 优选的技术方案中,使用余弦相似度计算用户特征值U=(F1,F2,…,Fn),每一维Fi 用下述公式计算: 其中,Ni表示某用户生成的文本中被聚类到类别i中的文本个数, 表示Ni中的 第j条文本与类别i的类中心的余弦相似度,n表示用户特征数。 本发明还公开了一种基于用户生成文本的无监督学习的用户分类装置,包括: 文本表征向量生成模块,获取用户生成文本,生成文本表征向量; 第一聚类模块,使用无监督聚类算法对所有文本表征向量进行聚类,得到文本聚 类结果;将得到的文本聚类结果中的文本类别作为用户特征; 用户特征向量提取模块,计算用户的特征值,得到用户特征向量; 第二聚类模块,使用无监督聚类算法对用户特征向量进行聚类,得到用户分类。 优选的技术方案中,所述文本表征向量生成模块生成文本表征向量的方法包括以 下步骤: S11:获取用户生成文本的每个token对应的表征向量; S12:对文本所有token的表征向量取平均并将结果向量作为文本表征向量,文本 表征向量为768维,用ST=(ST1,ST2,ST3,…,ST768)表示,每一维STi通过下述公式计算: 其中,NT表示token的个数, 表示第j个token的表征向量的第i维的值,STi表示 文本表征向量ST的第i维的值。 5 CN 111611376 A 说 明 书 3/6 页 优选的技术方案中,所述用户特征向量提取模块中计算用户生成文本在文本类内 与对应的类中心的相似度,得到每一个用户的特征值。 优选的技术方案中,使用欧式距离计算用户特征值U=(F1,F2,…,Fn),每一维Fi用 下述公式计算: 其中,Ni表示某用户生成的文本中被聚类到类别i中的文本个数, 表示Ni中的 第j条文本与类别i的类中心的欧式距离相似度,n表示用户特征数,T是一个预设常量。 优选的技术方案中,使用余弦相似度计算用户特征值U=(F1,F2,…,Fn),每一维Fi 用下述公式计算: 其中,Ni表示某用户生成的文本中被聚类到类别i中的文本个数, 表示Ni中的 第j条文本与类别i的类中心的余弦相似度,n表示用户特征数。 与现有技术相比,本发明的优点是: 本发明基于用户生成文本(UGT)生成文本表征向量,并进行聚类,将得到的文本类 别作为用户特征,计算量小,同时能保证一定的准确率。将用户生成文本在文本类内与对应 的类中心的相似度,进行用户表征的确定,同样计算量小,并且能够较准确表征用户的特 征。 本发明的方法不需要标注数据,仅仅基于用户生成文本(UGT)进行两次无监督聚 类即能实现用户分类,方法简单快捷。具有广泛的应用前景。 附图说明 下面结合附图及实施例对本发明作进一步描述: 图1为本发明基于用户生成文本的无监督学习的用户分类方法的流程图; 图2为本发明将用户特征从96维降维到2维后的用户分类结果示意图; 图3为本发明将用户特征从96维降维到3维后的用户分类结果示意图。











