
技术摘要:
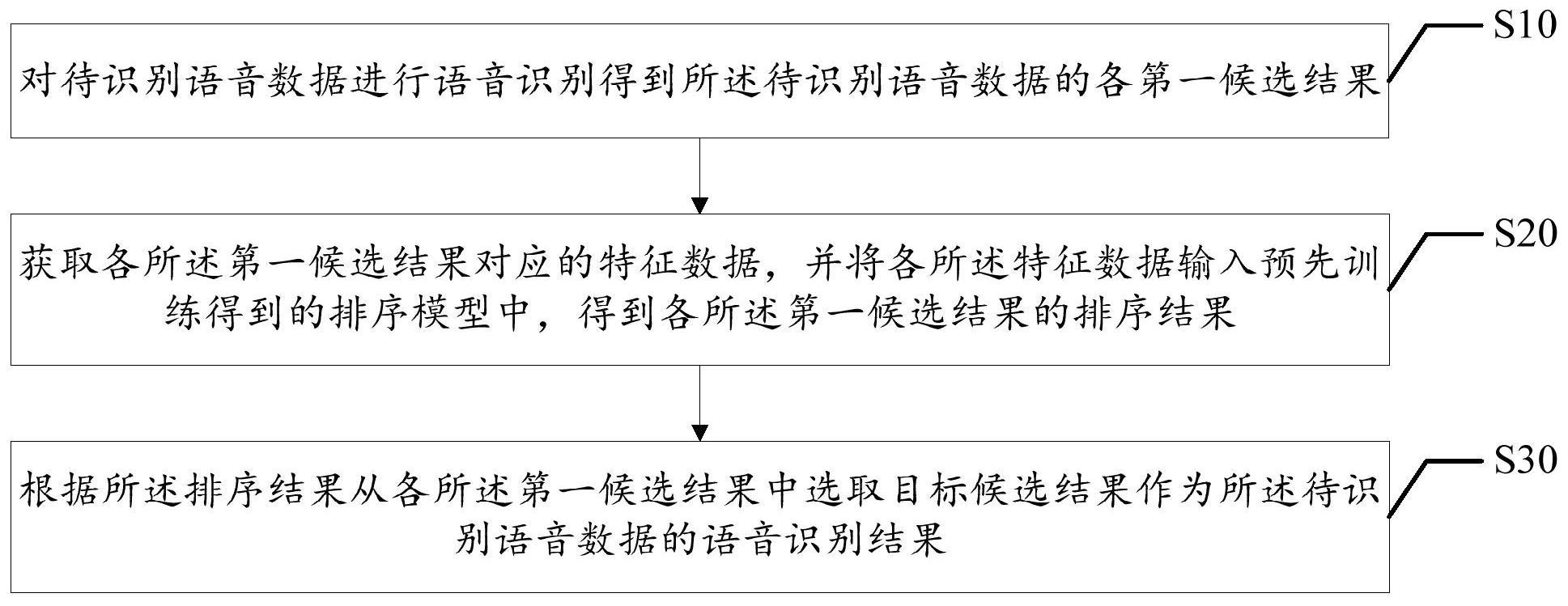
本发明公开了一种语音识别方法、设备、系统及计算机可读存储介质,所述方法包括:对待识别语音数据进行语音识别得到所述待识别语音数据的各第一候选结果;获取各所述第一候选结果对应的特征数据,并将各所述特征数据输入预先训练得到的排序模型中,得到各所述第一候选 全部
背景技术:
随着语音数据处理技术的发展,语音识别系统已经广泛地应用于各个领域。语音 识别系统中,对N-候选重打分(N-best Hypotheses Rescoring)是一个重要的部分,对语音 识别效果有至关重要的影响。N-候选是对语音数据识别得到的N个候选结果,N-候选重打分 是对N个候选结果重新进行打分排序。目前采用的N-候选重打分的方式是先用语音模型 (Acoustic Model)和语言模型(Language Model)对每个候选进行评估打分,然后将语音模 型评分和语言模型评分组合起来给出N-候选的最终排序结果,取排名第一的候选作为最终 的语音识别结果。但是这种先给出语音模型评分和语言模型评分,再线性组合两种得分的 方式,需要根据经验来设置得分的线性组合方式,具有很大的不确定性,从而导致语音识别 效果不够准确。
技术实现要素:
本发明的主要目的在于提供一种语音识别方法、设备、系统及计算机可读存储介 质,旨在解决目前N-候选重打分的方式,需要根据经验来设置得分的线性组合方式,具有很 大的不确定性,从而导致语音识别效果不够准确的问题。 为实现上述目的,本发明提供一种语音识别方法,所述方法包括以下步骤: 对待识别语音数据进行语音识别得到所述待识别语音数据的各第一候选结果; 获取各所述第一候选结果对应的特征数据,并将各所述特征数据输入预先训练得 到的排序模型中,得到各所述第一候选结果的排序结果; 根据所述排序结果从各所述第一候选结果中选取目标候选结果作为所述待识别 语音数据的语音识别结果。 可选地,所述获取各所述第一候选结果对应的特征数据的步骤包括: 采用预设的打分模型对各所述第一候选结果进行打分,得到各所述第一候选结果 对应的打分值,其中,所述打分模型包括至少一个语音模型和/或至少一个语言模型; 将各所述第一候选结果的打分值对应作为各所述第一候选结果的特征数据。 可选地,所述获取各所述第一候选结果对应的特征数据的步骤包括: 采用预设的至少一个语言表征模型对各所述第一候选结果进行处理,得到各所述 第一候选结果对应的向量表示; 将各所述第一候选结果的向量表示对应作为各所述第一候选结果的特征数据。 可选地,所述获取各所述第一候选结果对应的特征数据,并将各所述特征数据输 入预设的排序模型,得到各所述第一候选结果的排序结果的步骤之前,还包括: 对训练语音数据进行语音识别得到所述训练语音数据的各第二候选结果; 4 CN 111554276 A 说 明 书 2/12 页 获取各所述第二候选结果对应的特征数据,以及获取各所述第二候选结果的排序 标签; 将各所述第二候选结果对应的特征数据和各所述第二候选结果的排序标签作为 一条训练数据,并根据获取到的各条训练数据得到训练数据集; 采用所述训练数据集对待训练排序模型进行训练得到所述排序模型。 可选地,所述获取各所述第二候选结果的排序标签的步骤包括: 获取所述训练语音数据的真实文本; 分别计算各所述第二候选结果相对于所述真实文本的误识率; 按照各所述误识率对各所述第二候选结果进行排序,得到各所述第二候选结果的 排序标签。 可选地,所述特征数据包括所述第一候选结果的打分值和/或所述第一候选结果 的向量表示。 可选地,所述对待识别语音数据进行语音识别得到所述待识别语音数据的各第一 候选结果的步骤包括: 对所述待识别语音数据进行语音特征提取,得到所述待识别语音数据的语音特征 数据; 采用预设语音模型和预设语言模型对所述语音特征数据进行识别,得到所述待识 别语音数据的各第一候选结果。 为实现上述目的,本发明提供一种语音识别装置,所述装置包括: 识别模块,用于对待识别语音数据进行语音识别得到所述待识别语音数据的各第 一候选结果; 排序模块,用于获取各所述第一候选结果对应的特征数据,并将各所述特征数据 输入预先训练得到的排序模型中,得到各所述第一候选结果的排序结果; 选取模块,用于根据所述排序结果从各所述第一候选结果中选取目标候选结果作 为所述待识别语音数据的语音识别结果。 为实现上述目的,本发明还提供一种语音识别设备,所述语音识别设备包括:存储 器、处理器及存储在所述存储器上并可在所述处理器上运行的语音识别程序,所述语音识 别程序被所述处理器执行时实现如上所述的语音识别方法的步骤。 此外,为实现上述目的,本发明还提出一种计算机可读存储介质,所述计算机可读 存储介质上存储有语音识别程序,所述语音识别程序被处理器执行时实现如上所述的语音 识别方法的步骤。 本发明中,通过对待识别语音数据进行语音识别得到各个候选结果,再获取各个 候选结果的特征数据,调用预先训练得到的排序模型来对各个特征数据进行处理,得到各 个候选结果的排序结果,并基于排序结果从各候选结果中选出最后的语音识别结果。本发 明中,采用预先设置并训练好的排序模型对各个候选结果的特征数据进行排序,由于排序 模型通过训练已学习到了如何依据特征数据进行排序,并不是根据人为经验设置如何排 序,相比于依据人为经验设置的线性评分组合方式,能够获得更加准确的排序结果,从而能 够获得更加准确的语音识别结果。本发明中将各个候选结果的特征数据输入该排序模型中 进行排序得到排序结果,相比于先获取各个候选的评分进行组合,再依据评分进行排序的 5 CN 111554276 A 说 明 书 3/12 页 方式,本发明中的排序方式更加直接、简单。此外,相比于现有的对评分进行线性组合以对 N-候选重打分,再依据评分进行排序的方式,本发明中,由于是基于各个候选结果的特征数 据进行排序,特征数据不仅限于各个候选结果的打分值,也即,本发明中的排序依据可以不 仅限于打分值,从而使得排序依据更加丰富,能够得出更加准确的排序结果,进而能够获得 更加准确的语音识别结果。 附图说明 图1为本发明实施例方案涉及的硬件运行环境的结构示意图; 图2为本发明语音识别方法第一实施例的流程示意图; 图3为本发明实施例涉及的一种语音识别流程示意图; 图4本发明语音识别装置较佳实施例的功能示意图模块图。 本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。











