
技术摘要:
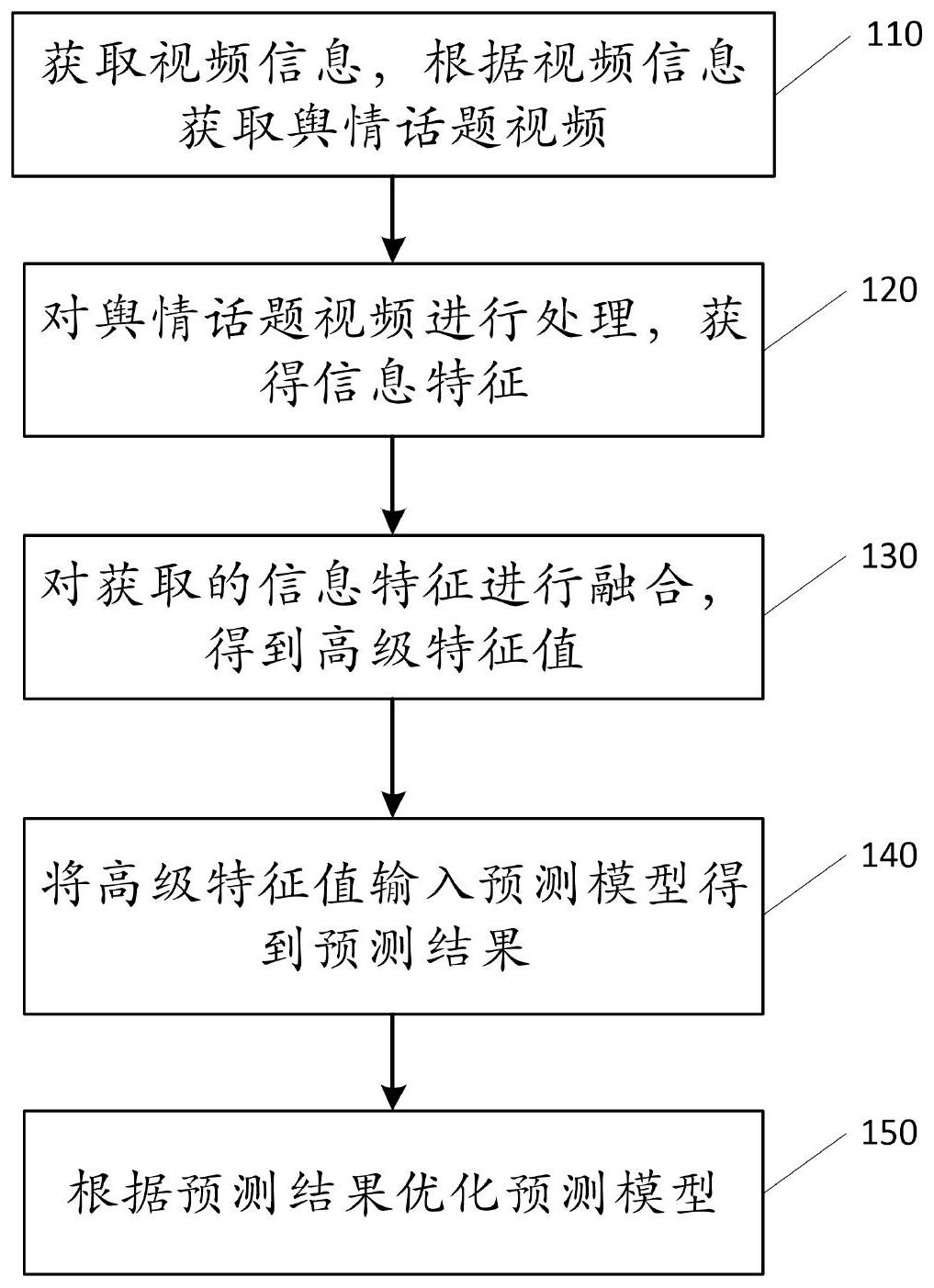
本申请公开了一种视频舆情的预测方法及预测系统,其中视频舆情的预测方法,具体包括如下步骤:获取视频信息,根据视频信息获取舆情话题视频;对舆情话题视频进行处理,获得信息特征;对获取的信息特征进行融合,得到高级特征值;将高级特征值输入预测模型得到预测结果 全部
背景技术:
随着移动互联网和5G通信技术的快速发展,视频作为更便捷有效的信息传播方 式,呈现出高速发展的态势。特别是随着短视频平台、直播行业的迅速崛起,视频量呈现出 爆炸式增长,网民均可以通过视频在网络上表达观点、传播思想。但随之而来的是有些网民 在网上传播负能量,造谣传谣,发表涉黄涉暴、低俗媚俗的不当言论,严重的甚至侮辱英烈, 损害党和政府的形象。因此加强视频舆情的监测,及时追踪视频舆情动态信息,根据已有信 息快速预测未来舆情趋势,从而制定更灵活、针对性更强的舆论监管和引导措施。对于净化 网络空间,加强网络空间治理,营造天朗气清、生态良好的亿万民众共同的精神家园具有重 要意义。 现有的舆情预测方法以基于文本的舆情预测为主,通过采集各大新闻网站、论坛、 微博、公众号等平台的文本信息、用户公开信息等,对文本信息进行预处理后,提取出舆情 信息,结合相应的舆情预测模型预测不同舆情信息的舆情变化指数。随着视频作为更广泛 的信息载体,如果用户发表的内容不存在文本信息,现有的文本舆情预测方法将无法监测 并利用相关舆情信息进行预测,如果用户发表的内容既存在文本信息也存在视频信息,现 有的文本舆情预测方法将只利用文本信息及相关舆情信息进行预测,因此对于舆情的预测 存在一定的偏差。 因此,如何能够有效的对视频舆情进行预测从而预测检测结果的正确性是本领域 人员目前急需解决的问题。
技术实现要素:
本申请的目的在于提供一种视频舆情的预测方法及预测系统,实现更加自动化、 智能化的视频舆情预测,并获得更为精准、精确的舆情态势。 为达到上述目的,本申请提供了一种视频舆情的预测方法,具体包括如下步骤:获 取视频信息,根据视频信息获取舆情话题视频;对舆情话题视频进行处理,获得信息特征; 对获取的信息特征进行融合,得到高级特征值;将高级特征值输入预测模型得到预测结果; 根据预测结果优化预测模型。 如上的,其中,根据视频信息获取舆情话题视频中,还包括,判断获取的视频信息 中是否存在相同的视频数据,若存在相同的视频数据,则将相同视频数据作为同一舆情话 题视频进行合并存储。 如上的,其中,获取信息特征具体包括:获取视频特征、获取文本特征、获取属性特 征以及获取传播特征。 如上的,其中,获取视频特征具体包括以下子步骤:获取低语义的视频特征矩阵; 5 CN 111582587 A 说 明 书 2/9 页 基于低语义的视频特征矩阵生成视频标签、主题、文字描述深层语义信息;将深层语义信息 向量化后作为视频特征。 如上的,其中,获取低语义的视频特征矩阵具体包括以下子步骤:利用卷积神经网 络提取舆情话题视频中的多帧图像的特征向量;融合多帧图像的特征向量得到低语义的视 频特征矩阵;其中融合多帧图像的特征向量得到低语义的视频特征矩阵具体包括以下子步 骤:获取每一帧图像的特征向量的通道注意力特征图,以及根据通道注意力特征图获取每 一帧图像的特征向量的空间注意力特征图;根据每一帧图像的空间注意力特征图获取多帧 图像的特征向量序列的时序注意力特征图;融合多帧图像的特征向量序列的时序注意力特 征图,获得视频特征矩阵。 如上的,其中,其中通道注意力特征图 表示为: 其中,MLP为多 层感知机网络,σ(·)为激活函数,AvgPool为平均池化,MaxPool为最大值池化, 为 hadamard乘积,Ac表示获得通道注意力的函数,vi表示多帧图像特征向量序列中的某一帧图 像的特征向量; 空间注意力特征图 表示为: 其中,AvgPool 为平均池化,MaxPool为最大值池化, 为hadamard乘积,σ(·)为激活函数, 表示通道注 意力特征图,ω表示网络参数,As表示获得空间注意力的函数; 时序注意力特征图 表示为: 其中,ω0、ω1、ω2、b为网 络参数,h为隐状态,T表示矩阵转置, 表示空间注意力特征图, 为hadamard乘积,σ(·) 为激活函数,其中 表示由空间注意力特征图 组成的矩阵, At表示获得时序注意力的函数,tanh表示双曲正切函数。 其中视频特征矩阵F具体表示为: 其中,ω表示网络参数,H、W分别为视频帧通道的高度、宽度,其中 表示由时序注意力特征图 组成的矩阵。 如上的,其中,对获取的信息特征进行融合,得到高级特征值具体包括以下子步 骤:根据信息特征建立特征融合模型;将信息特征输入特征融合模型,获得高级特征值;其 中t时刻高级特征j的特征值 具体表示为: j∈[0,6],其中,MStacking为叠 加多个特征融合模型的元模型,M(·)为特征融合模型,FV表示视频特征,FW文本特征,FP表 示属性特征,FS表示传播特征,MV、MW、MP表示元模型,MS表示时序模型。 如上的,其中,将高级特征输入预测模型Mpredict中,得到预测结果,其中预测结果 包括预测得到的t时刻的舆情热度指数Pt以及t 1时刻的高级特征值 具体表示为: 6 CN 111582587 A 说 明 书 3/9 页 其中, 表示t时刻的预测模型, 表示表示t时刻高级特征j的高级特征值。 如上的,其中,根据预测结果优化预测模型包括,在t 1时刻,根据预测的高级特征 值 和真实高级特征值 的误差训练网络,得到t 1时刻的预测模型 其中t 1时刻 的预测模型 具体表示为: 其中, 表示预测的高级特征值, 表示真实高级特征值,concat表示矩阵沿着某一个维度进行连接,training表示训练过程。 一种视频舆情的预测系统,具体包括获取单元、处理单元、融合单元以及预测优化 单元;获取单元,用于获取视频信息,根据视频信息获取舆情话题视频;处理单元,用于对舆 情话题视频进行处理,获得信息特征;融合单元,用于对获取的信息特征进行融合,得到高 级特征值;预测优化单元,用于将高级特征值输入预测模型进行预测,并根据预测结果优化 预测模型。 本申请具有的有益效果是: 本申请提供的视频舆情的预测方法及预测系统,可充分发挥人工智能相关技术的 优势,深度挖掘视频数据及相关信息中的舆情信息,深度表征舆情态势发展趋势,快速迭代 更新舆情预测模型,实现自动化、智能化的视频舆情预测,大幅提高对舆情话题的预测准确 度。 附图说明 为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现 有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本 申请中记载的一些实施例,对于本领域普通技术人员来讲,还可以根据这些附图获得其他 的附图。 图1是根据本申请实施例提供的视频舆情的预测方法流程图; 图2是根据本申请实施例提供的视频舆情的预测系统的内部结构图; 图3是根据本申请实施例提供的视频舆情的预测系统的子模块的内部结构图。











