
技术摘要:
本发明保护多音字读音消歧装置及方法。该装置包括数据处理模块用于:获取包含多音字的原始数据文本,并进行数据预处理,得到第一文本样本;特征提取模块用于:向第一文本样本中分别加入目标多音字的N条读音释义信息,得到N条第二文本样本;N由目标多音字的读音个数所决 全部
背景技术:
在语音合成等应用场景中,字音转换是重要的组成部分,这一环节的准确率直接 影响语音合成的可理解性。有些汉字有多种读音(多音字),比如“还”有“huan2”和“hai2”两 种读音。 对于多音字数据采集或文本拼音标注任务来说,使用人工标注的方式将耗费大量 的人力物力,因此多音字自动化注音技术,可提高数据生产效率并降低人工成本。 多音字读音消歧(在特定环境下自动地辨析多音字的读音)是多音字自动化注音 过程中的重点和难点,如何进行多音字读音消歧是目前研究的热门。
技术实现要素:
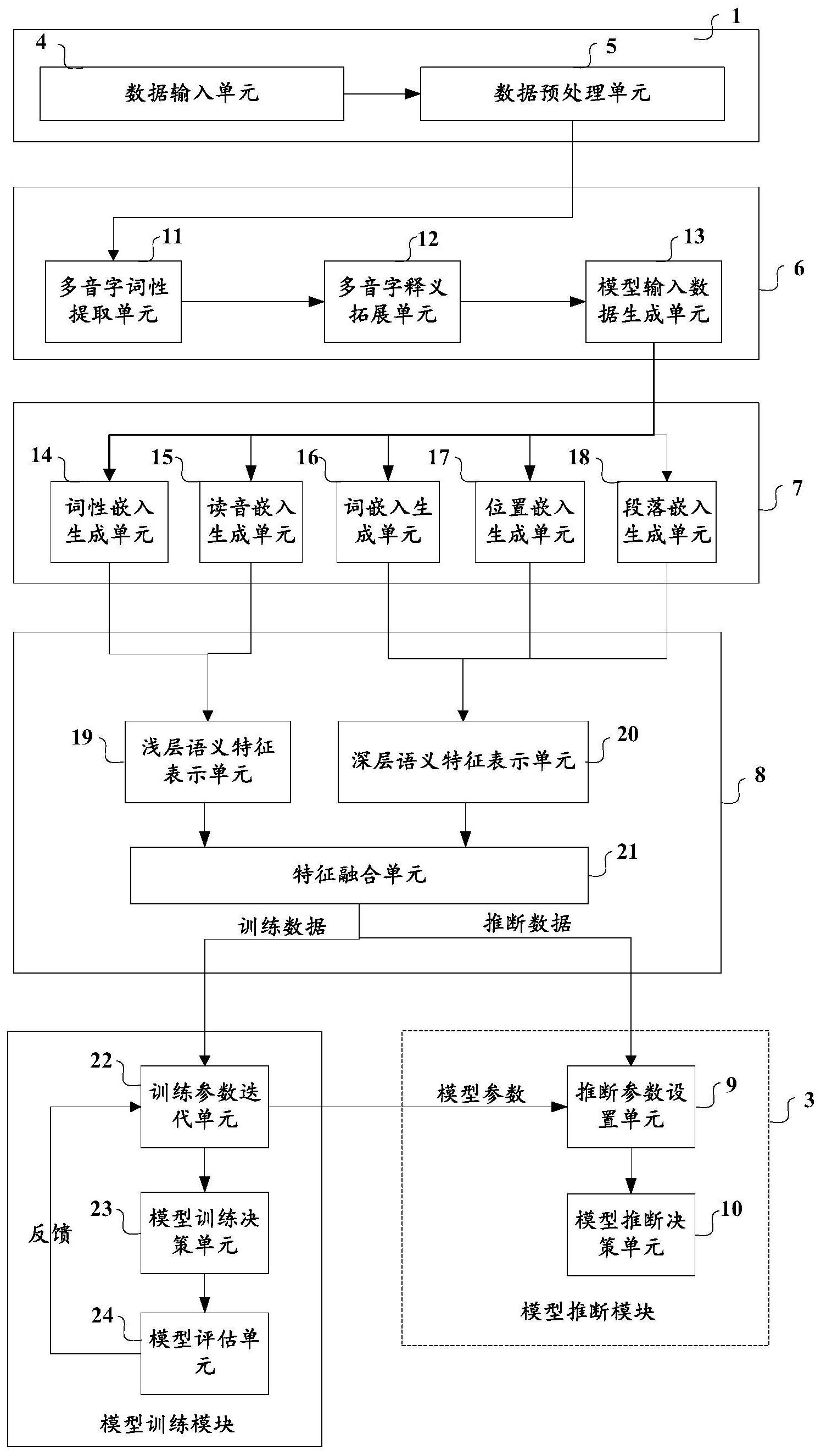
有鉴于此,本发明实施例提供一种多音字读音消歧装置及方法,以实现多音字读 音消歧。 为实现上述目的,本发明实施例提供如下技术方案: 一种多音字读音消歧装置,包括数据处理模块、特征提取模块和模型推断单元; 其中, 所述数据处理模块用于:获取包含多音字的原始数据文本,并进行数据预处理,得 到第一文本样本; 所述特征提取模块用于: 在预测阶段,向所述第一文本样本中分别加入所述目标多音字的N条读音释义信 息,得到N条第二文本样本;所述N由所述目标多音字的读音个数所决定;每一读音释义信息 包括:读音及相应的词典释义; 对目标文本样本进行特征提取,得到相应的多音字读音消歧特征;在预测阶段,所 述目标文本样本包括所述N个第二文本样本;所述目标文本样本中需进行多音字读音消歧 的多音字为目标多音字; 所述模型推断模块用于: 在预测阶段,将所述目标文本样本的多音字读音消歧特征输入训练好的多音字读 音消歧神经网络,由所述训练好的多音字读音消歧神经网络决策出所述目标多音字的最终 读音。 可选的,在样本准备阶段,所述数据处理模块获取的第一文本样本包括标签;所述 标签包括所述目标多音字的正确读音;在训练准备阶段,所述特征提取模块用于:向所述第 一文本样本中加入与所述正确读音对应的读音释义信息,得到正文本样本;向所述第一文 本样本中加入所述目标多音字的其他读音释义信息,得到负文本样本;将所述正文本样本 和负文本样本随机分配至预设的训练集或测试集。 5 CN 111611810 A 说 明 书 2/13 页 可选的,在所述训练阶段:所述目标文本样本包括所述训练集或所述测试集中的 文本样本;任一文本样本为正文本样本,或负文本样本;所述装置还包括:模型训练模块,用 于在训练阶段对多音字读音消歧神经网络执行多次迭代训练,其中,每一次迭代训练包括: 多音字读音消歧神经网络基于所述训练集中文本样本的多音字读音消歧特征和标签进行 学习,得到学习后的多音字读音消歧神经网络;将所述测试集中的文本样本的多音字读音 消歧特征输入学习后的多音字读音消歧神经网络,根据所述学习后的多音字读音消歧神经 网络所输出的读音和相应标签计算正确率,所述正确率用于判断是否停止迭代训练。 可选的,所述特征提取模块至少包括:文本加工模块,用于:在预测阶段,向所述第 一文本样本中分别加入所述目标多音字的N条读音释义信息,得到N个第二文本样本,或者, 在样本准备阶段,向所述第一文本样本中加入与所述正确读音对应的读音释义信息,得到 正文本样本;向所述第一文本样本中加入所述目标多音字的其他任一读音释义信息,得到 负文本样本;嵌入生成模块,用于:提取所述目标文本样本的多通道特征;特征表示模块,用 于:根据所述多通道特征,提取所述目标文本样本的浅层语义特征和深层语义特征;对所述 浅层语义特征和深层语义特征进行拼接,并对拼接结果提取融合表示向量作为所述多音字 读音消歧特征。 可选的,所述文本加工子模块包括:多音字词性提取单元,用于在所述第一文本样 本中,为所述目标多音字所属的词添加词性;多音字释义拓展单元,用于:在预测阶段,向所 述第一文本样本中分别加入所述目标多音字的N条读音释义信息,或者,在样本准备阶段, 向所述第一文本样本中加入与所述正确读音对应的读音释义信息;向所述第一文本样本中 加入所述目标多音字的其他任一读音释义信息;模型输入数据生成单元,用于:在样本准备 阶段,将所述正、负文本样本随机分配至预设的训练集或测试集。 可选的,所述嵌入生成模块包括:词性嵌入生成单元,用于为所述目标多音字所属 的词所对应的词性,生成词性向量;读音嵌入生成单元,用于根据所述读音释义信息中的读 音,生成读音向量;词嵌入生成单元,用于将所述目标文本样本中每一个字符转换成词向 量;位置嵌入生成单元,用于生成所述目标文本样本中每一个字符的位置信息向量;段落嵌 入生成单元,用于:为所述目标文本样本中的每一个字符分配段落索引,不同的段落索引用 于表征相应的字符属于原始数据文本或释义信息;将每一字符的段落索引转换成唯一的段 落信息向量。 可选的,所述特征表示模块包括:浅层语义特征表示单元,用于对所述词性向量与 所述读音向量进行拼接,得到所述浅层语义特征;深层语义特征表示单元,用于从所述词向 量、所述位置信息向量和所述段落信息向量中,提取深层语义特征;特征融合单元,用于:对 所述浅层语义特征和深层语义特征进行拼接,并对拼接结果提取融合表示向量作为所述多 音字读音消歧特征。 可选的,所述模型训练模块包括:训练参数迭代单元,用于:初始化待训练的多音 字读音消歧神经网络的模型参数,并对模型参数进行更新;模型训练决策单元,用于根据所 述文本样本的多音字读音消歧特征,决策所述文本样本中添加的读音是否正确;所述模型 训练决策单元包括待训练的多音字读音消歧神经网络;模型评估单元,用于根据所述模型 训练决策单元输出的决策结果和相应标签,计算损失值并反馈给所述训练参数迭代单元, 所述损失值用于所述训练参数迭代单元更新模型参数。 6 CN 111611810 A 说 明 书 3/13 页 可选的,所述模型推断模块包括:推断参数设置单元,用于加载训练好的模型参 数,得到训练好的多音字读音消歧神经网络;模型推断决策单元,用于根据所述N个第二文 本样本的多音字读音消歧特征,决策出所述目标多音字的最终读音;所述模型推断决策单 元包括所述训练好的多音字读音消歧神经网络。 一种多音字读音消歧方法,包括: 获取包含多音字的原始数据文本,并进行数据预处理,得到第一文本样本;所述第 一文本样本中的多音字为目标多音字; 向所述第一文本样本中分别加入所述目标多音字的N条读音释义信息,得到N条第 二文本样本;所述N由所述目标多音字的读音个数所决定;每一读音释义信息包括:读音及 相应的词典释义; 对目标文本样本进行特征提取,得到相应的多音字读音消歧特征;在预测阶段,所 述目标文本样本包括所述N个第二文本样本; 将所述目标文本样本的多音字读音消歧特征输入训练好的多音字读音消歧神经 网络,由所述训练好的多音字读音消歧神经网络决策输出所述目标多音字的最终读音。 可见,在本发明实施例中,在获取原始数据文本后,先进行预处理,得到第一文本 样本,再向第一文本样本中加入目标多音字的N条读音释义信息,将第一文本样本扩充为目 标文本样本。每一第二文本样本包含目标多音字的一个读音及相应的词典释义。再将这目 标文本样本的多音字读音消歧特征输入训练好的音字读音消歧神经网络,得到目标多音字 的最终读音,从而实现了多音字读音消歧。 附图说明 图1为本发明实施例提供的多音字读音消歧装置的一种示例性结构; 图2为本发明实施例提供的预测阶段的示例性流程; 图3为本发明实施例提供的多音字读音消歧装置的另一种示例性结构; 图4为本发明实施例提供的第二文本样本的示意图; 图5为本发明实施例提供的段落索引示意图; 图6为本发明实施例提供的提取融合表示向量的示意图; 图7为本发明实施例提供的多音字读音消歧方法的示例性流程。











