
技术摘要:
本发明涉及一种基于在线学习的航天器临近操作自主控制方法及系统,针对航天器在近临近操作任务中所存在的视线场约束、接近走廊约束以及控制性能实时在线优化等实际工程问题,提出一种基于在线学习的临近操作自主控制技术的方法;本发明包括以下步骤:首先,基于对偶四 全部
背景技术:
随着航天技术的高速发展,航天器在轨任务的多样性和复杂性日益提高,任务载 体逐渐由单集成大航天器系统向多航天器系统扩展,任务类型也由传统的观测、通讯等基 本任务,衍生出了以航天器临近操作问题为代表的新兴在轨任务。航天器临近操作控制技 术衍生于交会对接、在轨维护补给等在内的重要任务场景。由于飞行安全、载荷特性和任务 需求等因素,在轨航天器经常需要满足各类运动约束。一方面,由于任务中的目标航天器有 的具有一些外张型载荷,出于安全考虑,追踪星的运动轨迹一般会被限制在一个以对接口 为轴心的锥形区域内,这一运动约束常被称为接近走廊约束。另一方面,为完成交会对接任 务,追踪星需要具备实时测量其与目标星间的相对运动状态的能力。但是,由于这类光学载 荷通常只具有有限的视场范围,追踪航天器的姿态需要被有效控制以使得目标星一直处于 这个有限视场内,称之为视场约束。另外,考虑到航天器携带燃料有限,任务的时效性等因 素,航天器的运动控制具有时效和经济的综合最优效应也是未来航天器控制系统设计中的 一个非常关键因素。所以研究在位姿约束条件下的航天器的控制性能优化问题就显得尤为 重要。 在国内外的相关研究中,解决此类任务相关的问题主要立足于两个方面,一方面 是基于人工势能函数的运动控制,另一方面是基于求解最优问题的进行路径的运动轨迹设 计。前者虽然能很好的解决在运动过程中的轨迹规避问题,但是其缺乏优化性能指标的功 能。后者虽然能兼顾约束规避和控制性能的优化,然而求解优化问题需要的时效都不能满 足航天任务的需求。因此,现有的航天器临近操作自主控制方法存在难以保证同时保证运 动约束性能优化以及计算时效的情况。
技术实现要素:
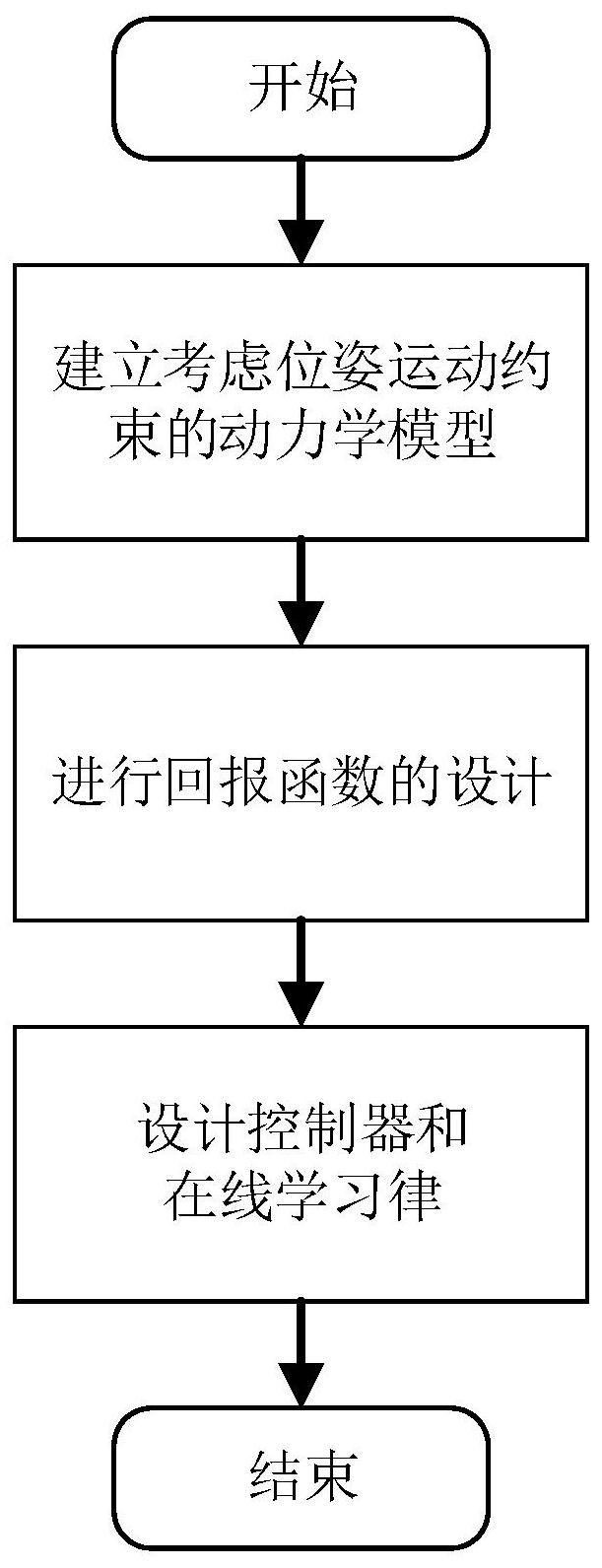
本发明的目的在于解决航天器临近操作自主控制任务中由于光学载荷以及航天 器本体结构造成的六自由度运动约束问题,本发明提供一种基于在线学习的航天器临近操 作自主控制方法及设备,通过设计与任务功能相关的回报函数,并利用在线数据设计控制 器的实时学习律,解决了航天器临近操作任务中的六自由度运动约束问题,在保证满足运 动约束的条件下,通过实时学习自主改进优化控制器的性能,提升了控制系统的航天器控 制系统的任务执行能力。 本发明提供一种基于在线学习的航天器临近操作自主控制方法,(1)根据航天器 临近操作任务的位姿动力学特性基于对偶四元数建立动力学模型,并在对偶四元数的框架 下刻画临近操作任务中的位姿运动学约束; (2)根据航天器临近操作任务的需求设计相应的在线学习中的回报函数; 5 CN 111596677 A 说 明 书 2/7 页 (3)根据(1)的动力学模型和(2)中的回报函数基于对偶四元数框架设计利用在线 数据设计学习控制方法。 具体实现步骤如下: 第一步建立航天器临近操作任务的位姿动力学模型如下: 其中, 表示被控航天器与目标航天器的相对位姿, 为其相对时间的 导数, 为对偶四元数的集合, 为对偶四元数乘法,被控航天器与目标航天器的相对对偶 角速度、被控航天器相对于惯性参考系的对偶角速度以及目标航天器相对于惯性参考系的 对偶角速度分别表述为 和 为 相对时间的导数, 表示由力fb 和力矩τb组成的对偶控制输入, 表示对偶惯量矩阵由转动惯量Jb和质量 组成m b ,I 3 为三阶单位矩阵 ,ε为对偶单元其满足性 质ε≠0 ,ε2 =0。上式中 基于对偶四元数的性质刻画接近走廊约束和视线场约束。由于任务中的目标航天 器有时具有较大的空间规模和一些外张型载荷,故出于安全考虑,追踪星的运动轨迹通常 被限制在一个以对接口为轴心的圆锥包络内。可以通过对偶四元数的形式刻画为: 式中, cpath表示目标航天器对接口 方向的单位方向向量, 表示关于cpath的叉乘矩阵,θ表示约束轴心包络圆锥的半锥角,o 表示对偶数的内积运算。另外,由于任务中的被控航天器上搭载由测量相对位姿的导航载 荷,其姿态需要被有效控制以使得目标航天器一直处于这个圆锥视场内,这类约束可被称 为视线场约束,具体可以通过对偶数四元数的形式刻画为: 式中, csight表示被控航天器载荷 方向的单位方向向量, 表示关于csight的叉乘矩阵,α表示约束载荷视线场约束圆锥的半 锥角。 第二步,设计航天器临近操作任务的回报函数。在航天器临近操作任务中,控制的 最终目标是使得被控航天器到达期望的位置和姿态,所以期望状态回报函数可以设计为: 6 CN 111596677 A 说 明 书 3/7 页 其中, 表示单位对偶四元数, Qq和Qω分别 表示位姿和速度的权重矩阵。在航天器临近操作任务中的约束即为被控航天器不期望达到 的位置和姿态。在此,位置约束回报函数设计为: 式中,c1为第一步中的接近走廊约束不等式左侧部分,β1为位置约束权重因子。类 似的,姿态约束回报函数设计为: 式中,c2为第一步中的视线场约束不等式左侧部分,β2为姿态约束权重因子。综上 所述,总的回报函数设计为: γ=γstate γpath γsight 基于上式所设计的回报函数,可以对航天器的自主控制的结果给与相应的回报, 以满足航天器临近操作任务的需求。 第三步,设计基于在线学习的航天器临近操作自主控制方法,在线学习控制策略 设计如下: (1)所设计的控制器为: 其中, 航天器的运动状态可以集成表示为 表示基底函数,west表示对应的估计权重向量, 表示关于对偶向量 的偏导数运算。 (2)控制器中权重向量的学习律为: 其中,μ1和μ2为大于零系数,tk1和tk2为采样时间节点, 为贝尔曼误差, 为最佳权重向量w与估计权重向量之差, 辅助变量用于在线数据的采集,具体设计为: Ψ(t,tk2,tk1)=ψ1(tk2,tk1)west ψ2(tk2tk1) 其 中 ,学 习 辅 助 变 量ψ 1 ( t , t k 1 ) ,ψ 2 ( t , t k 1 ) 分 别 设 计 为 , 式中,k>0为调节参 7 CN 111596677 A 说 明 书 4/7 页 数,tk1和tk2为学习时间节点,其关系应满足 利用以上步骤可以实现约束条件下在实时学习的控制器设计,可以保证航天器在 临近操作任务中运动轨迹安全的前提下根据在线数据实时提升航天器的控制性能。 本发明还提供一种基于在线学习的航天器临近操作自主控制系统,包括评判网 络、回报网络、学习器、控制器以及航天器相对位姿动力学模型,使用基于在线学习的航天 器临近操作自主控制方法,航天器由控制器执行控制任务,并由评判网络和回报网络采集 数据对控制性能进行评估,同时学习器通过评估结果进行网络权重的实时学习,将控制参 数更新到控制器中,实现在线性能提升。 本发明是一种基于在线学习的航天器临近操作自主控制方法,与现有技术相比的 优点在于: (1)基于对偶四元数的汇报函数设计,实现了航天器临近操作过程中位置和姿态 的运动规避,保证了任务的安全执行。 (2)与基于人工势能函数的方法相比,本方案使用基于在线学习控制的方法不仅 能够实现约束区域的规避,还能有效地提升了控制性能,提升了控制系统的经济性以及任 务执行力。 (3)与基于求解优化问题的方法相比,本方法的实现是在线实时的,通过实时采集 数据并更新控制器的权重参数,实现控制器的在线学习,极大的降低了对运算硬件平台的 需求,具有很强的可实现性。 附图说明 图1为基于在线学习的航天器临近操作自主控制系统原理框图; 图2为本发明的一种基于在线学习的航天器临近操作自主控制方法流程框图;











