
技术摘要:
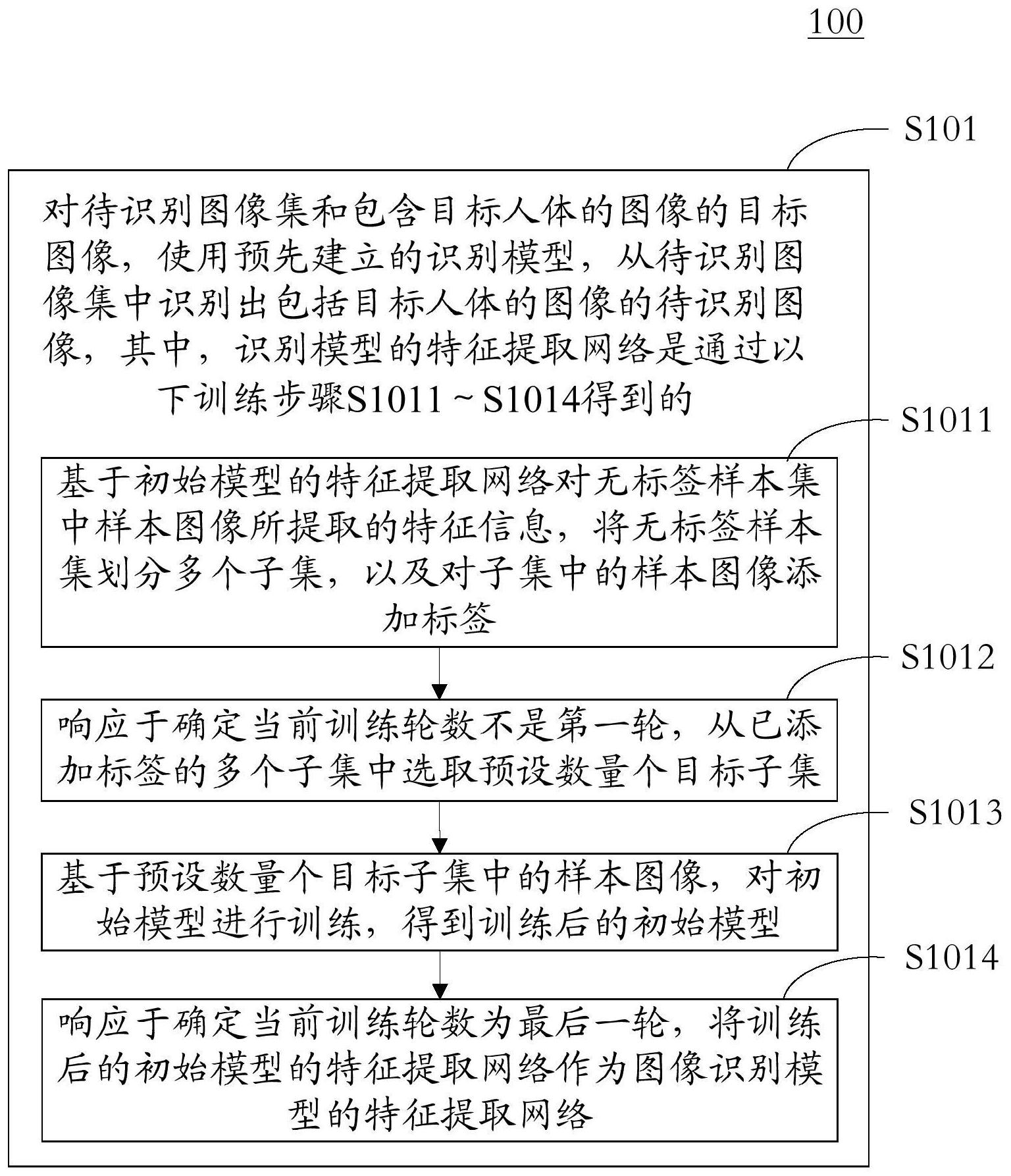
本申请公开了用于识别图像的方法和装置,涉及计算机视觉领域。具体实现方案为:使用识别模型,从待识别图像集中识别出包括目标人体的图像的待识别图像,识别模型的特征提取网络通过以下训练步骤得到:基于初始模型的特征提取网络对无标签样本集中样本图像所提取的特征 全部
背景技术:
行人重识别也称行人再识别,是利用计算机视觉技术判断图像或者视频序列中是 否存在特定行人的技术。目前,机器学习模型已经广泛应用于行人再识别领域,并且能够有 效地提高行人再识别的性能。机器学习模型的训练需要大量的有标签行人图像。在实际应 用中,难以获取到大规模的有标签行人图像,且人工添加标签的过程的成本非常高。为了解 决这个问题,无监督学习就成了使用行人再识别技术的有效前提。一种常见的方式,是通过 聚类算法给行人图像标上伪标签,再利用伪标签对机器学习模型进行有监督训练,从而提 升机器学习模型的识别能力。
技术实现要素:
提供了一种用于识别图像的方法和装置。 根据第一方面,本公开实施例提供了一种用于识别图像的方法,该方法包括:对待 识别图像集和包含目标人体的图像的目标图像,使用预先建立的识别模型,从上述待识别 图像集中识别出包括上述目标人体的图像的待识别图像,其中,上述识别模型的特征提取 网络是通过以下训练步骤得到的:基于初始模型的特征提取网络对无标签样本集中样本图 像所提取的特征信息,将无标签样本集划分多个子集,以及对子集中的样本图像添加标签; 响应于确定当前训练轮数不是第一轮,从已添加标签的多个子集中选取预设数量个目标子 集,其中,上述预设数量个目标子集间的特征距离小于上一轮训练时所使用目标子集间的 特征距离;基于上述预设数量个目标子集中的样本图像,对上述初始模型进行训练,得到训 练后的初始模型;响应于确定当前训练轮数为最后一轮,将上述训练后的初始模型的特征 提取网络作为上述图像识别模型的特征提取网络。 根据第二方面,本公开实施例提供了一种用于识别图像的装置,该装置包括:识别 单元,被配置成对待识别图像集和包含目标人体的图像的目标图像,使用预先建立的识别 模型,从上述待识别图像集中识别出包括上述目标人体的图像的待识别图像,其中,上述识 别模型的特征提取网络是通过训练单元训练得到的,上述训练单元包括:划分单元,被配置 成基于初始模型的特征提取网络对无标签样本集中样本图像所提取的特征信息,将无标签 样本集划分多个子集,以及对子集中的样本图像添加标签;第一选取单元,被配置成响应于 确定当前训练轮数不是第一轮,从已添加标签的多个子集中选取预设数量个目标子集,其 中,上述预设数量个目标子集间的特征距离小于上一轮训练时所使用目标子集间的特征距 离;训练子单元,被配置成基于上述预设数量个目标子集中的样本图像,对上述初始模型进 行训练,得到训练后的初始模型;第一确定单元,被配置成响应于确定当前训练轮数为最后 一轮,将上述训练后的初始模型的特征提取网络作为上述图像识别模型的特征提取网络。 根据第三方面,本公开实施例提供了一种电子设备,其特征在于,包括:至少一个 4 CN 111582185 A 说 明 书 2/10 页 处理器;以及与上述至少一个处理器通信连接的存储器;其中,上述存储器存储有可被上述 至少一个处理器执行的指令,上述指令被上述至少一个处理器执行,以使上述至少一个处 理器能够执行如第一方面中任一项上述的方法。 根据第四方面,本公开实施例提供了一种存储有计算机指令的非瞬时计算机可读 存储介质,其特征在于,上述计算机指令用于使上述计算机执行如第一方面中任一项上述 的方法。 根据本申请的技术在训练识别模型的特征提取网络时,根据训练轮数的增加逐渐 增加所选取目标子集间的区分难度,这样可以使初始模型对样本图像的区分能力随着训练 轮数的增多逐步增强,最后将训练完成后的初始模型的特征提取网络作为识别模型的特征 提取网络,从而使识别模型的特征提取网络所提取的特征信息更加准确,进而提升了识别 模型的识别准确度。 应当理解,本部分所描述的内容并非旨在标识本公开的实施例的关键或重要特 征,也不用于限制本公开的范围。本公开的其它特征将通过以下的说明书而变得容易理解。 附图说明 附图用于更好地理解本方案,不构成对本申请的限定。其中: 图1是根据本申请的用于识别图像的方法的一个实施例的流程图; 图2是根据本申请的用于识别图像的方法的一个应用场景的示意图; 图3是根据本申请的用于识别图像的方法的又一个实施例的流程图; 图4是根据本申请的用于识别图像的装置的一个实施例的结果示意图; 图5是用来实现本申请实施例的用于识别图像的方法的电子设备的框图。











