
技术摘要:
本发明公开一种基于Kinect的多模态人机交互系统,实现步骤如下:构建能接受Kinect获取到的多模态数据的数据采集系统;进行声学模型与语言模型的单音素训练,得到声学识别模块;利用采集到彩色图数据建立用于训练机器学习的唇动数据集;使用基于残差神经网络的卷积神经网 全部
背景技术:
语音识别属于模式识别的一种,计算机通过给定的输入语音进行信息查找,有语 音转文本,身份识别等,和图像识别一样,在人机交互中有着广泛的应用。语音识别系统根 据说话的方式来分,可与分为孤立词识别系统和连续词识别系统。孤立词的语音数据单位 为单个词语,在采集数据时,是以一个词一个词的方式来录音的,词与词之间有着明显的停 顿。相对的连续词是对连续的词语进行识别。现有孤立词识别系统在识别结果上尚需要进 一步改进。
技术实现要素:
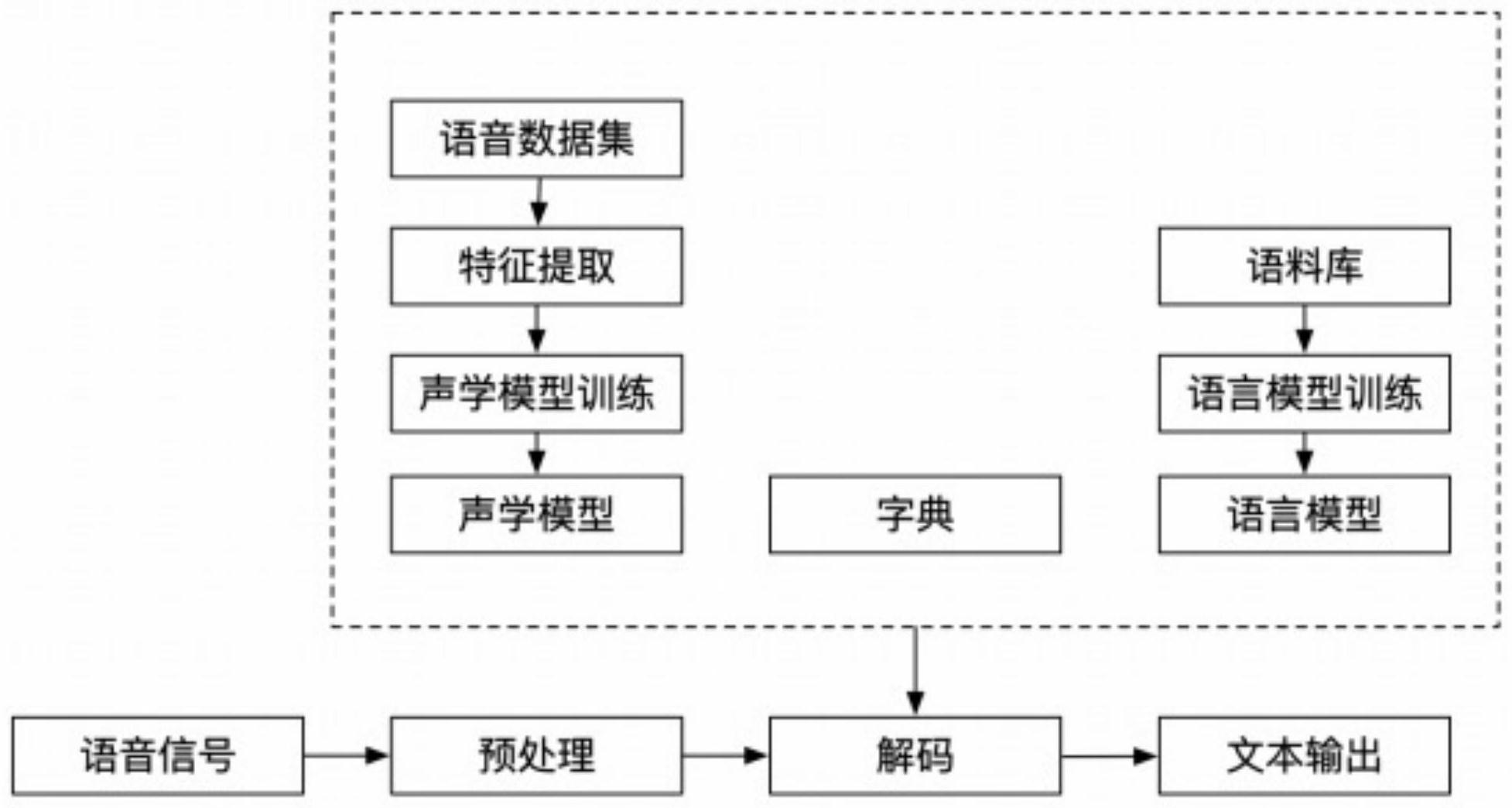
本发明的目的是针对现有技术中存在的技术缺陷,而提供一种基于Kinect的多模 态人机交互系统,对于用户说出的命令词,在纯净环境下(无噪声环境)能够通过语音识别 出命令词,在带噪环境下能够通过语音和唇读识别得到命令词的识别结果,特别是通过识 别唇部变化来提高语音识别的准确度,增强语音识别的鲁棒性。 为实现本发明的目的所采用的技术方案是: 一种基于Kinect的多模态人机交互系统,实现步骤如下: S1.构建能接受Kinect获取到的多模态数据的数据采集系统; S2.使用基于Kaldi的开源语音识别工具集编写训练脚本,对采集到的音频数据提 取特征向量,进行声学模型与语言模型的单音素训练,得到最终的声学识别模块; S3.利用采集到彩色图数据建立用于训练机器学习的唇动数据集; S4.使用基于残差神经网络的卷积神经网络的模型训练方法,利用唇动数据集训 练唇读识别模型,获得最终唇读识别模块; S5.将数据采集系统、语音识别模型和唇读识别模型整合在一起,构建一个多模态 的人机交互系统。 其中,唇动数据集的训练使用Python语言的Pytorch模块搭建LSTM网络进行;该网 络包括: 第一处理部,用于数据预处理,输入的张量为1x40x112x112,通过不断的卷积和池 化,将张量转化为64个特征图,所述特征图的时空三个维度长都相等; 第二处理部,采用ResNet34层模型,能将输入转为一维512的张量,将唇动的特征 进行进一步的筛选; 第三处理部,是一个双层双向长短期存储网络,最终再使用SoftMax层对于输入进 行分类,实现了对于唇动数据集的n分类。 其中,所述的将数据采集系统、语音识别模型和唇读识别模型整合在一起的步骤 3 CN 111554279 A 说 明 书 2/7 页 是: 通过WPF框架开发一个用户控制台,通过该用户控制台实现对数据采集系统、语音 识别模型和唇读识别模型的控制:识别处理时,系统对于用户读出的限定词进行音频和图 像的录制并存储到本地,进行数据转换,将图像和音频转为模型能够接收的数据类型,并将 数据分别输入到声学识别模块和唇读识别模块中得出识别结果,系统将语音识别的结果和 唇读识别的结果遍历限定词分别计算出最高的相似度作为置信度,选择置信度高的作为多 模态识别的最终结果。 本发明对于用户说出的命令词,在纯净环境下(无噪声环境)能够通过语音识别出 命令词,在带噪环境下能够通过语音和唇读识别得到命令词的识别结果,特别是通过识别 唇部变化来提高语音识别的准确度,增强语音识别的鲁棒性。 附图说明 图1为本发明的基于Kinect的多模态人机交互系统的结构原理图; 图2为本发明在三种环境条件下的识别率对比图。











