
技术摘要:
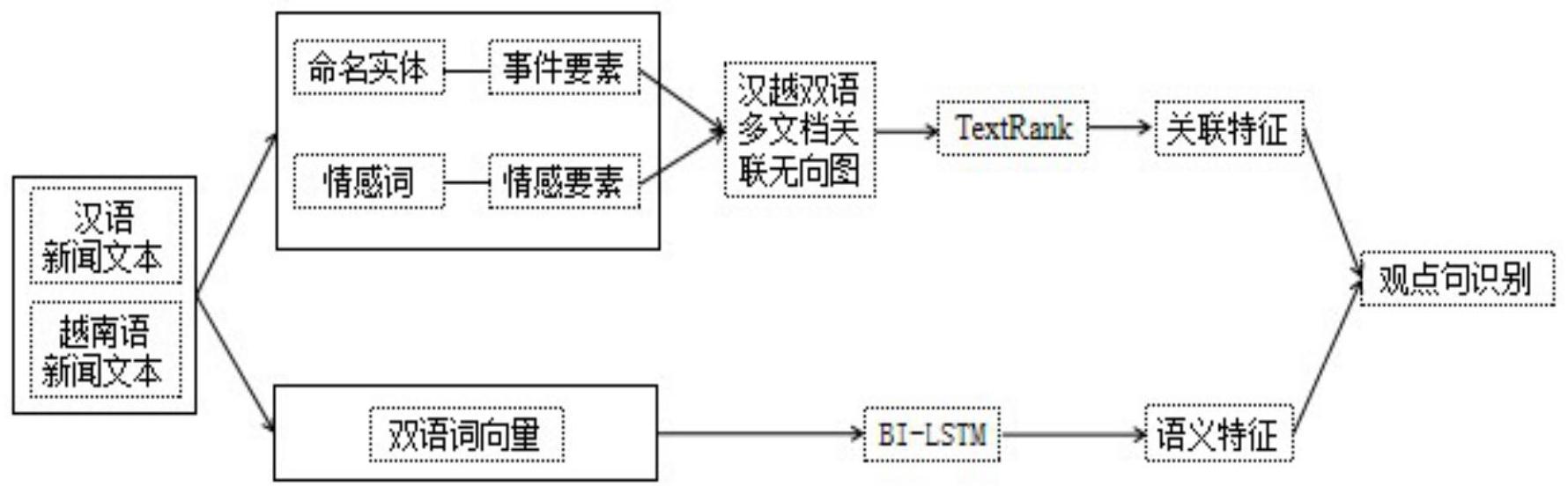
本发明涉及一种基于句子关联图的汉越双语多文档新闻观点句识别方法,属于自然语言技术领域。本发明针对汉越双语多文档新闻观点句识别任务,提出一种联合句子关联特征和语义特征的观点句识别模型;包括步骤:构建融合事件要素和情感要素的汉越双语多文档关联无向图;获 全部
背景技术:
开展汉越双语新闻观点句识别研究,及时掌握中越两国关于同一事件的观点,对 于促进中越两国之间的文化交流、经济发展至关重要。在观点句识别任务中,现有的方法主 要是根据观点句特征对文档中的观点句进行识别。比如通过观点句语义模型和非观点句语 义模型构建语义特征,然后通过融入词汇特征和词性特征对句子进行分类,最后将置信度 高的样本加入训练集迭代得到最终的分类器。或者是通过构建词典的方式来获得观点词和 非观点词的集合,然后对观点词的强弱程度进行计算,通过对每个句子中包含的观点词的 强弱程度的计算来对其是否为观点句进行甄别。还有学者提出了一种基于集成学习的中文 观点句抽取方法,该方法首先采用基于Fisher判别准则的特征选择方法,然后使用 Booststraping方法对朴素贝叶斯分类器、SVM分类器和最大熵分类器进行集成,从而对观 点句进行识别。 但是以上方法都是基于单文档,没有考虑多个文档多个句子之间的关联关系。因 此,本发明专利提出了一种联合句子关联关系和句子语义特征的基于句子关联图的汉越双 语多文档新闻观点句识别方法。
技术实现要素:
本发明提供了一种基于句子关联图的汉越双语多文档新闻观点句识别方法,以用 于解决了汉越新闻观点句识别的问题,且能有效提升汉越新闻观点句抽取的准确性。 本发明的技术方案是:一种基于句子关联图的汉越双语多文档新闻观点句识别方 法,包括: 首先计算不同句子间事件要素和情感要素的关联强度; 利用不同句子间事件要素和情感要素的关联强度构建汉越双语多文档关联无向 图; 获取汉越双语的句子关联特征; 利用双语词向量模型将汉语、越南语两种不同的语言映射到同一个语义空间下; 利用BI-LSTM网络对映射到同一个语义空间下的词向量编码,获取句子的语义编 码表示; 对得到的语义编码进行降维来获得汉越双语的句子语义特征; 利用句子关联特征、句子语义特征进行联合计算得到观点句识别特征,采用分类 器对观点句识别特征进行分类,并采用二分类的交熵损失函数对分类器进行优化,采用优 化好的分类器实现观点句识别。 进一步地,具体步骤如下: 5 CN 111581943 A 说 明 书 2/8 页 Step1、语料收集:收集中文新闻文本、越南语新闻文本作为训练语料和测试语料; 目前还没有公开的汉越双语新闻语料,因此可以利用爬虫工具从中文新闻网站和越南新闻 网站收集新闻文档。手动选择三个中越共同关心的话题事件,共计200 篇文档,2832个句 子。每个话题事件按照90%,5%,5%随机划分训练集、验证集和测试集。 Step2、计算不同句子间事件要素的关联强度: 事件要素包含事件发生的时间、地点、人物和组织机构等信息。可以利用不同新闻 句中事件要素的共现次数来表示不同句子间事件要素的关联强度。抽取汉越双语新闻句子 中的命名实体作为事件要素,根据汉越双语词典对抽取的要素进行对齐,计算句子间事件 要素的共现度。 进一步地,首先抽取汉越双语新闻句子中的命名实体作为事件要素,得到的汉语 新闻要素的集合记为 越南语新闻要素集合记为 为了衡量抽取要素的关联强度,首先利用汉越双语词典对抽取的要素进行对齐,得到对齐 的汉越新闻要素集合 最后通过计算不同句子的事件要 素共现次数来确定其关联强度,其共现次数可以通过判断两个句子是否包含相同的要素, 即对任意语言的两个句子si、sj的要素集合是否存在交集。如果si和sj的集合有交集,则两 者之间具有要素关联关系,其中,若si和sj是同一语种的句子,则直接做交集运算即可判断, 若属于不同语种的句子,则需使用对齐集合Acv中的要素重新表示句子si和sj之后,再做交 集运算进行判断; 判断任意语言的两个句子si、sj的要素集合是否存在交集,即对事件要素关联强度 进行归一化操作计算的具体公式为: 其中C(si∩sj)表示新闻句si和sj的共现要素数,C(si)则表示句子si的要素个数。 Step3、计算不同句子间情感要素的关联强度: 情感要素关联是指汉越双语新闻句子中包含的情感词的关联关系,通过计算不同 句子间情感词的相似性来衡量其关联关系。为了实现情感要素关联,首先抽取不同语言新 闻句中所包含的情感词,其中,汉语新闻句情感词抽取利用知网情感词典以及台湾大学 NTUSD情感词典,提取出每个句子中的情感词集 针对越南语情感词典 资源缺乏的问题,采用汉越双语词典翻译汉语情感词典,来构建越南语情感词典,在采用的 汉越双语情感词典中,中文情感词典规模可以为5126,越南文情感词典规模可以为3248。抽 取后得到每个越南语句子中包含的情感词集合 通过计算任意两个句子si 和sj所包含情感词的相似性作为句子的情感关联强度。其中情感词相似性通过汉越双语词 向量的余弦相似度得到,具体公式为: 其中cos为余弦相似度函数, 和 为情感要素的双语词向量。 最终两个句子的情感关联强度通过计算两个句子的所有情感词相似度的最大值 得到。具体公式为: 6 CN 111581943 A 说 明 书 3/8 页 Step4、构建汉越双语多文档关联无向图; 根据句子间的关联关系,构建汉越双语多文档句子关联图G=











