
技术摘要:
本发明属于机器学习技术领域,本发明所涉及的域自适应人脸识别方法是人工智能的一个分支,公开了一种多子空间的域自适应人脸识别方法。提出通过多个子空间学习得到更多的判别信息,取得较好的分类模型,解决了源域样本和目标域样本数据分布不同,传统的机器学习方法在 全部
背景技术:
人脸识别研究方向中,传统机器学习方法在假设训练数据和测试数据满足同分布 的前提下,能够较好地分类预测问题,通过对带有标注的源域样本数据训练得到分类模型, 用与源域样本分布一致的测试样本数据进行测试。但在真实场景中,训练数据和测试数据 往往不满足同一分布,因此,使用源域样本数据训练的分类模型应用到与之分布不同的目 标域样本数据中,性能会严重退化。 域自适应方法能够通过将带有监督信息源域数据信息转移到另一个不同但相关 的目标域上,从而提升分类模型的性能。子空间学习是域自适应的一种方法,通过最小化源 域和目标域之间的差异得到一个公共子空间,在子空间中将目标域数据近似表示成源域数 据从而进行有监督的训练。然而,单个子空间存在固定最优解,当代价函数最小时,目标域 表示的源域的最优结果是固定的,其不能提供更多的判别信息,限制了人脸识别分类任务 的一个较好的识别性能。 在本专利中,提出一个多子空间域自适应的框架模型,对数据进行多个子空间学 习,提取更多的判别信息,得到较好的分类模型。 3
技术实现要素:
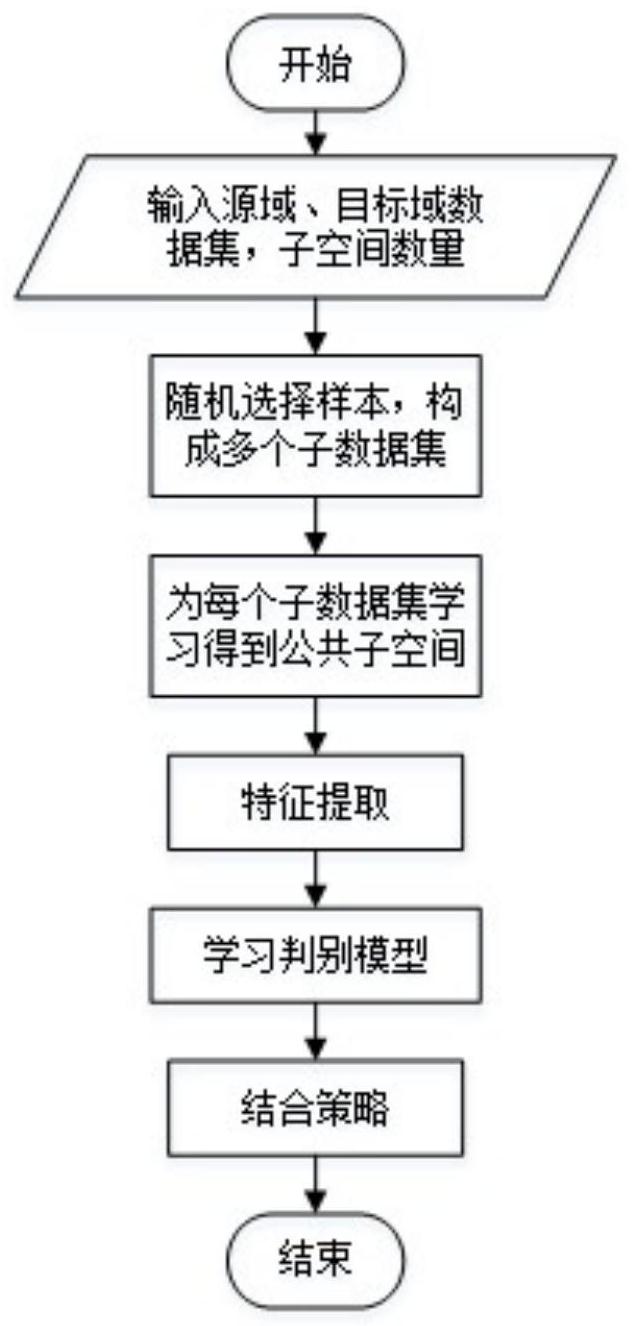
已有的单子空间域自适应人脸识别方法主要缺点为:在训练样本投影到同一个子 空间中,样本的特征信息是固定的,另外,在公共子空间中,源于样本和目标域样本在相互 线性表示的训练中,会求出一个固定的最优解,这些都导致样本多样性的缺失。 方案1: 在本发明中,提出一个多子空间域自适应的人脸识别框架,通过随机选择样本的 方法,使得同一个样本可能与不同的样本组合构成训练子数据集,在投影到不同的公共子 空间中,保留不同的判别特征,通过对更多的判别信息进行学习得到多个判别模型,对多个 判别模型给出的待测试样本的输出结果结合,得到最终的识别结果,这样的多子空间域自 适应人脸识别方法具有更好的识别性能。 人脸识别问题可以定义为: 为图片库,其标签为 xp是待识别 的样本数据,识别函数Label(xp)∈L。图片库与待识别样本与目标域数据分布一致,xp通过 与图片库中每一个样本数据进行相似度比对,得到xp的标签。 具体流程为:1.从训练数据集中随机选择样本作为每个子系统的训练样本;2.为 每个子系统学习一个公共子空间,要求在公共子空间中域之间特征能够很好地交融在一起 并且域本身的结构也能够较好地保留,然后分别用目标域数据进行线性组合来表示源域样 本;3.为每个子系统中新的源域数据学习一个判别模型;4.通过多数票和总和规则的策略 4 CN 111611909 A 说 明 书 2/6 页 将所有子系统结合起来得到最终的分类结果。在此基础上,将本方法应用于多个源域的学 习中,对人脸进行识别分类。 本专利中所提出的多子空间域自适应人脸识别方法分为两部分:训练部分和测试 部分。 1.训练过程: (1)在源域样本数据和Xs目标域样本数据Xt中随机选择n个样本,构造M个子数据 集,样本选择有两种策略,一种为样本类别数为定值,每个样本的数量改变;另一种为每一 类样本的数量为定值,样本类别数改变。 (2)每个子数据集进行降维处理。 (3)为每个子数据集学习得到公共子空间,在子空间中,通过稀疏表示和最大化方 差的方法使源域样本数据和目标域样本数据能够相互进行线性表示,输出用目标域数据线 性表示的源域数据,称为目标化的源域数据Xs→t,本专利可以应用于单源域和多源域自适应 人脸识别方法中。 单源域中,公共子空间中的样本分别表示为 和 稀疏重建和最大方差表示后的目标函数为 其中Vs、Vt为稀疏矩阵。由于上式中并非所有变量都为凸变量,对稀疏矩阵Vs、Vt和 投影矩阵Ws、Wt进行迭代求解,直到投影矩阵和系数矩阵收敛或者达到最大迭代次数。所求 得的目标化的源域数据为Xs→t: 在单源域的基础上,扩展为多源域自适应学习方法,源域数量为s,目标域用s 1表 示,总目标函数为: 其中 (4)用判别特征提取方法对目标化源域数据Xs→t进行训练,得到M个判别模型。 2.测试过程: (1)将图片库的样本数据Xg投影到各个判别模型中,得到判别特征;将待识别样本 xp投影到各个判别模型中,得到待识别样本的判别特征。 (2)在每个子系统中,计算每一个图片库样本数据 与待识别样本xp的相似度。 (3)每个子系统输出本系统与待识别样本相似度最大的图片库样本编号和所有的 图片库样本与待识别样本的相似度值,本专利采用余弦相似度进行计算。 5 CN 111611909 A 说 明 书 3/6 页 (4)通过结合策略对子系统的输出结果进行统计,得到待识别样本最终的标签。 本发明的有益效果为:在一般的分类任务中,分类器的学习需要大量的样本,但随 着样本的增多会导致数据维度的增加,从而使计算复杂度呈指数级增加。因此,本框架通过 多个子数据集学习,结合在一起,能够得到较好的泛化性能。同时,不同样本的随机组合可 以形成不同的特征空间,同一样本在不同的特征空间中保留不同的识别信息,从而获取到 更多的识别信息。 方案2: 在方案1基础上,本方法在结合策略上提出多数投票和总和规则两种策略对比其 性能。 Dg为每个子系统中待识别样本和图片库中每个样本数据的相似度矩阵,dki为待识别 样本 在第k个子特征空间中与图片库中第i个数据样本的距离,i=1,2,…,ng ,k=1, 2,…,M, Dg表达式为 对上式进行均值化和标准归一化: 其中μ、σ分别为dki的均值和方差。距离计算采用余弦相似度方法: 最后,xp的标签为 置信度通过 sigmoid函数来计算,并归一化: 其中rki为第k个子系统输出的后验概率值,作为每个类别的一个分值。结合所有子 系统的输出值得到xp的最终标签。 多数投票:根据每个系统中所输出的与待识别样本相似度最大的图片库样本编号 进行统计,相同标签最多的作为最终xp类别标签,可用下式表示: 其中Labelk(xp)为第k个子系统中Xp的识别结果。 总和策略:对每个子系统输出的相似度值加和,最大分值所对应的标签为xp的最 终标签,可用下式表示: 6 CN 111611909 A 说 明 书 4/6 页 其中rki为第k个子系统输出的图片库中第i个样本与xp的相似度的值。 多数投票法较总和规则策略识别性能更好,随M值得增大,识别性能有所提升。 本专利进一步对子空间数量M变化对性能的影响做相关研究,随着子空间的数量M 的值不断增大,本专利的人脸识别正确率不断上升,当M的值大于20以后,趋向平稳,由于 M 值得增大,会增加模型的训练时间,因此,M=20时代价最小且准确率最高。 有益效果为:类内散布矩阵和类间散布矩阵分别是描述类内变化和类间变化特性 最重要的2个参数。性能越好,类内散布矩阵的特征值越小而类间散布矩阵的特征值越大, 但是随着特征值的增大,相应特征向量的估计方差也随之增大,这同样会对识别性能产生 负面影响,而学习更多的子空间,能够将一组弱学习器结合起来,可以提高类间的差异判定 和识别能力,从而提升识别准确率,随着子空间数量的增多,识别准确率随之提升,到达一 定的值趋于平缓。 4.附图内容 图1为本发明的流程图; 图2为多子空间域自适应框架图; 图3为子空间M值变化时的性能变化。 5.











