
技术摘要:
本申请提供的基于词向量与卷积神经网络的DNA复制起始区域识别方法中,首先通过连续三分序列分词将DNA序列进行分词,得到各个三联核苷酸,然后将分词后的三联核苷酸负采样后通过Word2vec迭代训将三联核苷酸进行向量化得到词向量,所有的词向量合并后得到预训练特征向量 全部
背景技术:
DNA复制作为传递基因信息的首要步骤,有着很深刻的生物学研究意义。DNA复制 指的是DNA双链在细胞分裂之前以一个DNA链作为母链进行半保留复制,从而产生两个与原 DNA双链相同的子链的生物学过程。因此,研究DNA复制是研究生物学其他方面的基础,也是 研究生命进程的首要任务。众多生物学实验表明,DNA复制时从特殊的区域位置开始的,该 位置称为ORI(Origin of Replication,复制起始区域)。 基于目前生物技术的发展,利用生物学实验进行测量实验可以检测出某个生物 DNA的复制起始区域位置。如染色体免疫共沉淀技术(Chromatin Immunoprecipitation, ChIP)、染色质免疫共沉淀-芯片技术(ChIP-chip),以及表面离子共振技术(Surface Plasmon Resonance)。尽管这些方法都能精确地识别ORI,但是在后基因组时代,大量的基 因序列被检测出来,试验方法检测凸显出耗时和高成本的缺点。为此,如何脱离生物实验并 且使用计算机进行快速准确地识别出ORI是当前研究的热点。 为此,人们做出了很多努力来解决ORI识别问题。对于细菌,环状DNA中仅仅只有一 个ORI,有很多的算法可以进行识别。但是对于真核生物,为了提高DNA复制效率会同时从多 个位置进行复制,这也大大增加了识别的难度。近些年,人们提出了一些方法来解决酵母细 胞ORI识别的问题。例如,Chen等发现ORI区域的DNA可弯曲度和可裂解性比非ORI区域要低 很多,并基于此提出了一个计算模型来识别酿酒酵母细胞中的ORI。Li等从样本序列中生成 k-tuple伪核苷酸组成(Pseudo K0tuple Nucleotide Composition,PseKNC),将伪氨基酸 组成从蛋白质/肽链发展到了DNA/RNA领域。以伪核苷酸组成作为特征并且输入到支持向量 机中进行识别,成功开发了“iORI-PseKNC”预测器并且达到了83.72%的准确度。为了剔除 冗余特征以及特征维度,Dao等使用F-score和最小冗余-最大相关(minimum-Redundant and Maximum-Relevance,mRMR)进行特征选择并使用支持向量机进行识别,开发了一种名 为“iORI-PseKNC2.0”的预测器对酵母基因组进行识别。Xiao等人将二核苷酸位置特异性倾 向信息加入到伪核苷酸组成,提出了一种基于随机森林的预测器“iRO-gPseKNC”。Liu等考 虑了ORI中GC不对称性以及不定长序列,以3-窗口的形式进行特征提取结合随机森林算法 提出了“iRO-3wPseKNC”预测器,从而可以对四种酵母基因组进行更加全面的识别预测,实 现对不定长序列的ORI预测。基于iRO-3wPseKNC,计算序列中的GC偏移值并结合PseKNC,将 序列中的G和C作为特征进行提取,成功组建了“iRO-PsekGCC”预测器。 以上预测器各有优势,对于酵母细胞的ORI识别效果也逐步提升,对于推动ORI识 别具有很大的意义,但是这些方法的准确度等指标仍然不能够满足实际要求。此外,这些方 法都是基于机器学习的,无法深入挖掘到ORI序列与非ORI序列的特征。 4 CN 111599412 A 说 明 书 2/12 页
技术实现要素:
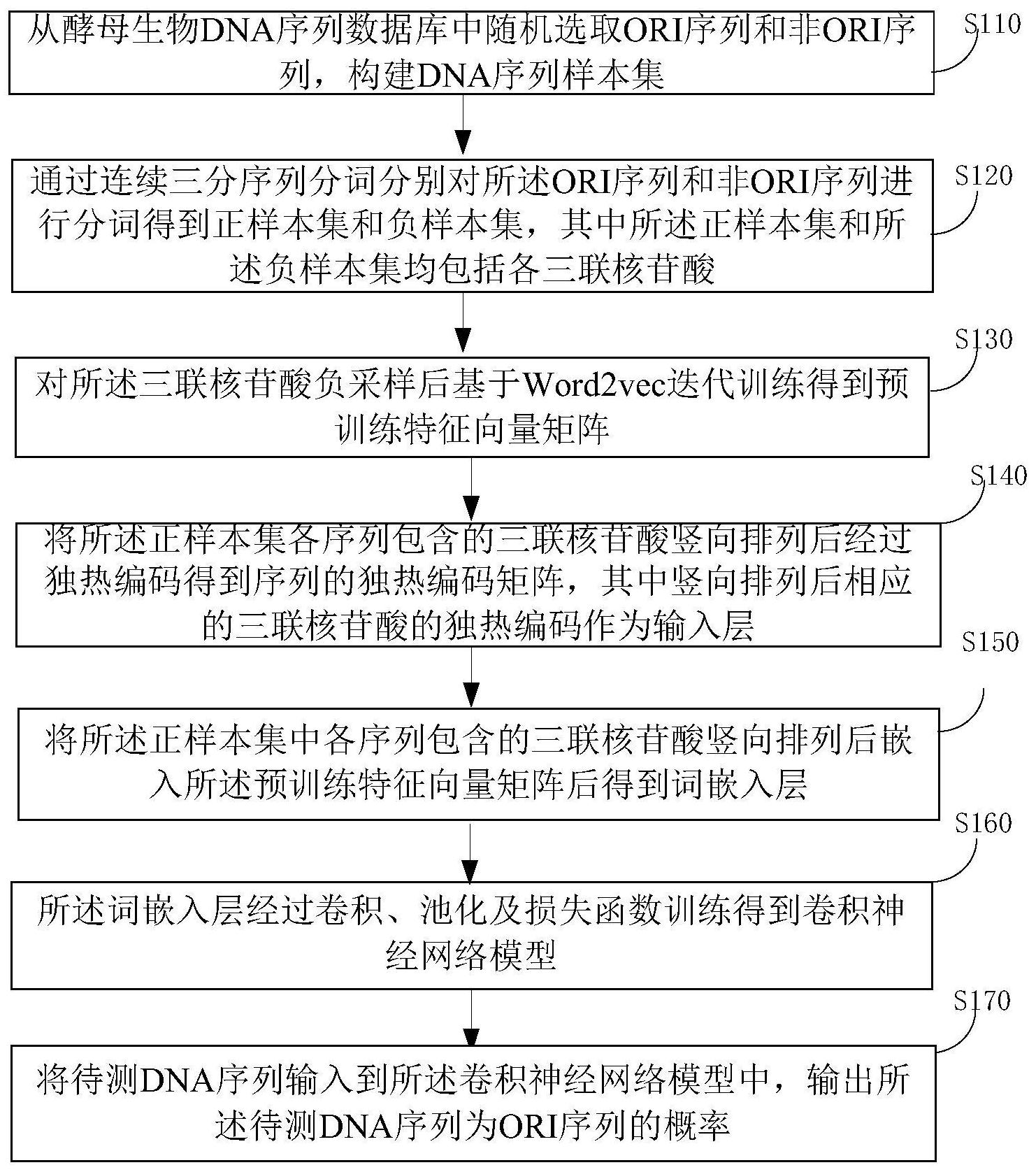
本申请提供了一种基于词向量与卷积神经网络的DNA复制起始区域识别方法,以 解决识别精度低的技术问题。 为了解决上述技术问题,本申请实施例公开了如下技术方案: 本申请提供了一种基于词向量与卷积神经网络的DNA复制起始区域识别方法,包 括: 从酵母生物DNA序列数据库中随机选取ORI序列和非ORI序列,构建DNA序列样本 集; 通过连续三分序列分词分别对所述ORI序列和非ORI序列进行分词得到正样本集 和负样本集,其中所述正样本集和所述负样本集均包括各三联核苷酸; 对所述三联核苷酸负采样后基于Word2vec迭代训练得到预训练特征向量矩阵; 将所述正样本集各序列包含的三联核苷酸竖向排列后经过独热编码得到序列的 独热编码矩阵,其中竖向排列后相应的三联核苷酸的独热编码作为输入层; 将所述正样本集中各序列包含的三联核苷酸竖向排列后嵌入所述预训练特征向 量矩阵后得到词嵌入层; 所述词嵌入层经过卷积、池化及损失函数训练得到卷积神经网络模型; 将待测DNA序列输入到所述卷积神经网络模型中,输出所述待测DNA序列为ORI序 列的概率。 可选的,所述通过连续三分序列分词分别对所述ORI序列和非ORI序列进行分词得 到正样本集和负样本集,还包括: 通过间隔三分序列分词分别对所述ORI序列和非ORI序列进行分词得到正样本集 和负样本集。 可选的,所述对所述三联核苷酸负采样,包括: 将各三联核苷酸的长度非等距划分至第一[0,1]区间,其中两个节点间的区间为 相应三联核苷酸的位置Li=(Ii-1,Ii) ,i=1,2,...,64; 以 为节点等距划分第二[0,1]区间; 将 投影到所述第一[0,1]区间上,建立 与 之间的映射关系; 从所述第二[0,1]区间内随机抽取任一目标三联核苷酸根据所述映射关系映射到 所述第一[0,1]区间内获得非目标三联核苷酸; 将所述目标三联核苷酸和所述非目标三联核苷酸合并后完成对三联核算干的负 采样。 可选的,所述将各三联核苷酸的长度非等距划分至第一[0,1]区间,包括: 根据 获取各三联核苷酸的长度,其中counter(·)代表某 个三联核苷酸出现的次数。 可选的,所述基于Word2vec迭代训练得到预训练特征向量矩阵,包括: 根据目标函数得到以上下文中的三联核苷酸最大化概率预测中心三联核苷酸时 5 CN 111599412 A 说 明 书 3/12 页 对应的所述中心三联核苷酸的词向量; 通过迭代将所述中心三联核苷酸表示为300维的特征向量; 对所有的三联核苷酸进行特征向量训练得到所述预训练特征向量矩阵。 可选的,所述根据目标函数得到以上下文中的三联核苷酸预测中心三联核苷酸的 最大化概率包括: 所述目标函数为 其中w表示中心三联核苷 酸向量, 代表上下文中的各个三联核苷酸向量, 代表在处理 时对中心三联核 苷酸进行负采样后的集合,u代表w与w的负采样集合 取并集后的集合中的三联核 苷酸向量集合, 表示以当前下文中的三联核苷酸去预测中心三联核苷酸的概率。 可选的,所述将所述正样本集各序列包含的三联核苷酸竖向排列后经过独热编码 得到序列的独热编码矩阵,包括: 所述独热编码矩阵的结构为 可选的,所述将所述正样本集中各序列包含的三联核苷酸竖向排列后嵌入所述预 训练特征向量矩阵后得到词嵌入层,包括: 将经过连续三分序列分词后的DNA序列竖向排列后得到自上而下的三联核苷酸组 合; 对各三联核苷酸一一从所述预训练特征向量中查询对应的特征向量; 将查询到的各所述特征向量合并得到不可训练词嵌入层。 可选的,所述将所述正样本集中各序列包含的三联核苷酸竖向排列后嵌入所述预 训练特征向量矩阵后得到词嵌入层,还包括: 将经过连续三分序列分词后的DNA序列竖向排列后得到自上而下的三联核苷酸组 合; 对所述三联核苷酸组合中的各三联核苷酸对应的独热编码矩阵中值为1的位置所 链接的权值被使用,得到所述三联核苷酸对应的预训练特征向量; 完成全部三联核苷酸的特征向量预训练后得到可训练词嵌入层。 可选的,所述将所述正样本集中各序列包含的三联核苷酸竖向排列后嵌入所述预 训练特征向量矩阵后得到词嵌入层,还包括: 所述词嵌入层包括两层,一层为可训练嵌入层,另一层为不可训练嵌入层。 与现有技术相比,本申请的有益效果为: 由上述技术方案可见,本申请提供的基于词向量与卷积神经网络的DNA复制起始 区域识别方法中,首先通过三分序列分词将DNA序列进行分词,得到各个三联核苷酸,然后 将分词后的三联核苷酸负采样后通过Word2vec迭代训将三联核苷酸进行向量化得到词向 量,所有的词向量合并后得到预训练特征向量矩阵,预训练特征向量矩阵中包括各个三联 6 CN 111599412 A 说 明 书 4/12 页 核苷酸的预训练特征向量,将分词后的各三联核苷酸竖向排列后嵌入各个三联核苷酸的预 训练特征向量得到词嵌入层,词嵌入层将三联核苷酸序列特征向量化,然后经过卷积、池化 训练得到卷积神经网络,通过加入词嵌入层的卷积神经网络进行ORI特征的深度挖掘和分 类识别,最终识别出ORI。 本申请中将DNA序列看作“语句”,其中ORI序列视为正确的语句,非ORI序列视为不 正确语句,并对DNA序列进行分词处理,保持生物学意义的同时凸显出各个核苷酸之间的位 置关系,然后利用Word2vec架构对“正确的语句”中的各个“词”进行向量化得到词向量以作 为“词”的特征向量,从而构建出后续词嵌入层所需要的预训练特征向量矩阵,最后使用卷 积神经网络架构深度挖掘了ORI序列与非ORI序列的特征及之间的差异特征并执行识别任 务;因此本申请的识别准确度会大大提高。 应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不 能限制本申请。 附图说明 为了更清楚地说明本申请的技术方案,下面将对实施例中所需要使用的附图作简 单地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动的前提下,还 可以根据这些附图获得其他的附图。 图1为本申请实施例提供的基于词向量与卷积神经网络的DNA复制起始区域识别 方法的流程示意图; 图2为本申请实施例提供的间隔三分序列分词的应用示意图; 图3为本申请实施例提供的负采样的应用示意图; 图4为本申请实施例提供的基于词向量与卷积神经网络的DNA复制起始区域识别 方法采用的网络框架示意图; 图5为本申请实施例提供的不可训练词嵌入操作过程示意图; 图6为本申请实施例提供的可训练词嵌入操作过程示意图; 图7为本申请实施例提供的双通道词嵌入操作过程示意图; 图8为本申请实施例提供的基于连续三片序列分词方法在三种词嵌入操作模式下 的实验结果示意图; 图9为本申请实施例提供的基于间隔三片序列分词方法在三种词嵌入操作模式下 的实验结果示意图。











