
技术摘要:
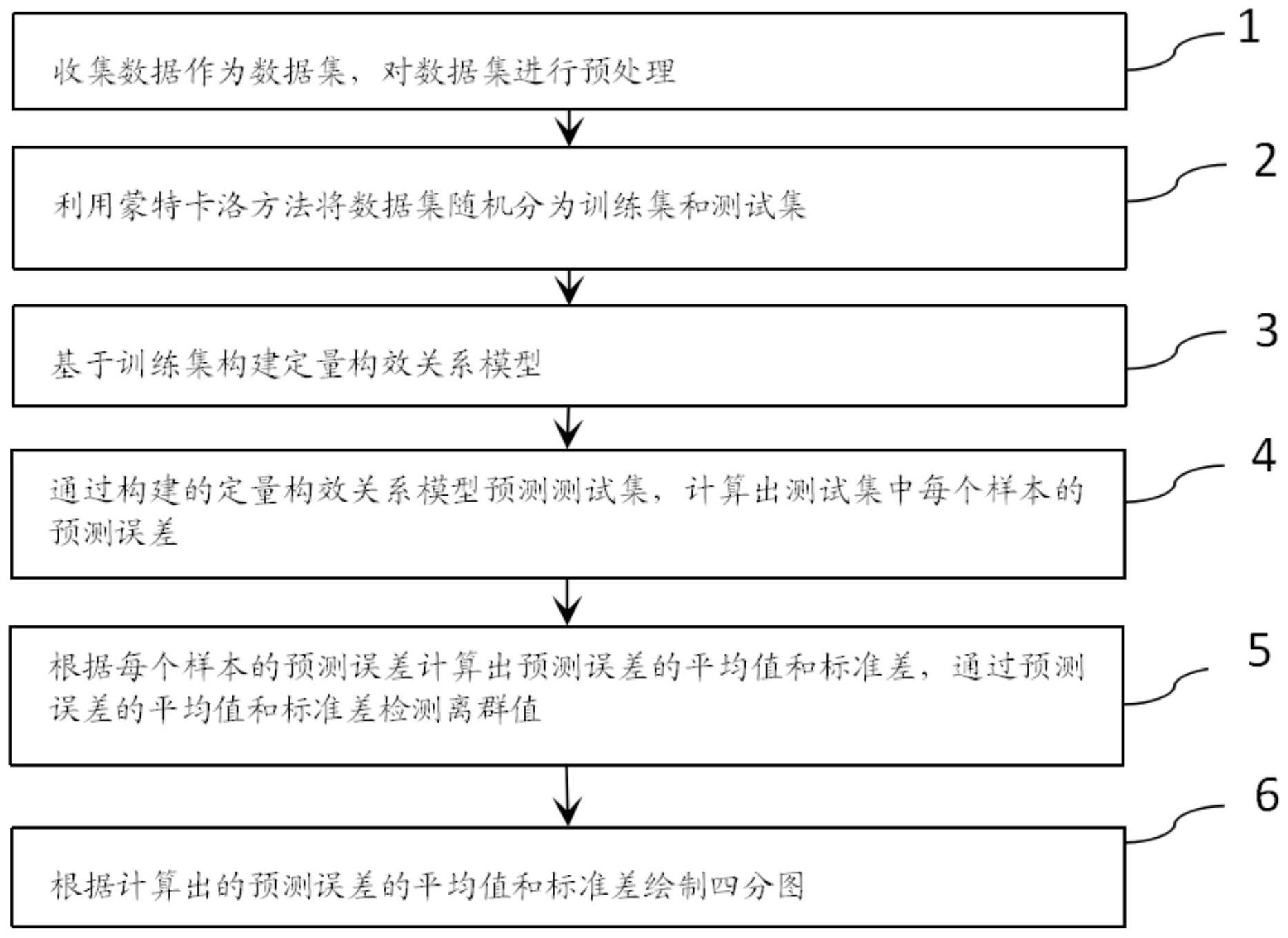
本发明提供了一种基于定量构效关系的离群值检测方法,包括:步骤1,收集数据作为数据集,对数据集进行预处理;步骤2,利用蒙特卡洛方法将数据集随机分为训练集和测试集;步骤3,基于训练集构建定量构效关系模型;步骤4,通过构建的定量构效关系模型预测测试集,计算出 全部
背景技术:
定量构效关系(QSAR/QSPR)是一个重要的方法已应用于许多物理化学和生物特性 的建模和预测成功,如沸点、熔点、溶解度、毒性、保留指数和许多药物的活性。这种关系的 基础是基于一个假设,即化合物相似的结构将表现出相似的属性。也就是说,当建立定量构 效关系模型时,与训练集化学结构相似的分子能被定量构效关系模型进行准确的预测。此 外,定量构效关系模型中的一个关键问题是模型的预测能力,良好的预测能力对于模型的 实际使用至关重要。例如,指导合成活性更高或毒性较小的化学物质,有助于缩短药物设计 周期,减少药物发现过程中的资源损耗。然而,化学界中有成千上万的化学分子跨越整个化 学空间。因此,化学物质的多样性无疑会给定量构效关系模型的建立带来一定的困难。这些 困难可能包括:(1)由某些训练集建立的模型将在很大程度上取决于训练集定义的结构。如 果数据集中存在一些特殊的样本它们偏离大部分的数据集,将会摧毁定量构效关系模型基 于相似性论文的拟合能力和预测能力。(2)对于大多数定量构效关系模型,例如多元线性回 归(MLR)模型,通常由拟合模型的相关系数(R2)和交叉验证决定系数(Q2)进行评估。一般来 说,对于一个好的模型,R2和Q2的值应该相互近似。但是,由于化学物质的多样性,R2有时与 Q2完全不同。因此,找出原因对于建立良好的模型非常重要。(3)由于任何定量构效关系模 型都是在特定的数据集上构建的,因此用来构建模型的数据对模型的预测精度和稳定性起 着至关重要的作用。在这其中,可以通过很好地定义化学药品的结构,然后使用结构相似的 其他化学药品数据集测试模型。因此,如何选择没有离群值的训练集和测试集来建立定量 构效关系模型是非常值得讨论和研究的。 定量构效关系模型中的离群值主要分为三种:X方向,Y方向,模型离群值。它们的 预测误差的分布特征如图2所示。图2中的a表示正常样本随机生成的数据集,具有较小的不 确定性,预测误差分布将在靠近原点处有一个又高又窄的峰值;图2中的b表示Y方向离群 值,对于Y方向离群值或模型离群值,无论模型如何变化,Y方向离群值和模型离群值的预测 误差分布都在远离原点处具有较大的期望值,且标准差适中;图2中的c表示模型离群值;图 2中的d表示X方向离群值,X方向离群值脱离了所有样本的主体,表现为将在原点周围有一 个较宽的峰。当前统计数据中有两种方法可以解决离群值:诊断方法和稳健估计方法。常用 的诊断方法,如平均值、标准差和帽子矩阵杠杆,依赖于检验统计量是否超过某个特定分布 (如正态分布)得出的某个临界值,这些方法在单独用于识别预测离群值和单个校准离群值 时具有良好的能力,但是,在建立的模型中,当多个离群值同时存在时,会导致诊断结果不 准确,多个离群值将会扭曲平均值和协方差矩阵的度量,以至于在使用帽子矩阵杠杆进行 分析时可能无法识别这些观察值,这种现象被称为掩蔽效应。此外,许多新颖的诊断方法, 如最小体积椭球体、椭球体多元修剪、最小协方差行列式、半均值重采样和最小半体积,已 4 CN 111613266 A 说 明 书 2/10 页 被用来检测离群值,虽然上述方法可以在一定程度上处理掩蔽效应,但它们只是强调了样 本方向上的离群值,它们还基于分类的思想,并试图找到数据的主体,然后将离群值视为与 大多数数据不同的另一种类型,因此被删除,在这个过程中,他们都没有考虑因变量,因此, 当仅用于检测离群值时,这些方法不足以发现回归分析中的所有离群值。 在稳健的回归模型中,主要目标是构建适合大多数数据的估计量,并检查该拟合 的误差以检测离群值,因此,许多稳健的回归方法,如M-estimators、最小中位数(LMS)、最 小平方差(LTS)、稳健主成分回归(RPCR)、稳健偏最小二乘(RPLS)和基于主敏感向量的稳健 主成分回归(RPPSV)等。这些鲁棒性估计方法在检测因变量方向上的离群值方面有很好的 性能,但在检测样本离群值方面却有些不足。
技术实现要素:
本发明提供了一种基于定量构效关系的离群值检测方法,其目的是为解决传统的 离群值检测方法不能同时识别和处理模型中的多种离群值的问题。 为了达到上述目的,本发明的实施例提供了一种基于定量构效关系的离群值检测 方法,包括: 步骤1,收集数据作为数据集,对数据集进行预处理; 步骤2,利用蒙特卡洛方法将数据集随机分为训练集和测试集; 步骤3,基于训练集构建定量构效关系模型; 步骤4,通过构建的定量构效关系模型预测测试集,计算出测试集中每个样本的预 测误差; 步骤5,根据每个样本的预测误差计算出预测误差的平均值和标准差,通过预测误 差的平均值和标准差检测离群值; 步骤6,根据计算出的预测误差的平均值和标准差绘制四分图。 其中,还包括: 重复执行所述步骤2、所述步骤3和所述步骤4。 其中,所述步骤1具体包括: 去除收集的数据的分子结构中的盐和复合物,对分子结构进行标准化,将属性值 和活性值转为相应的负对数的形式,计算所有分子描述符。 其中,所述步骤3具体包括: 定量构效关系模型中样本的性质可以通过定量构效关系模型产生的误差来反映, 如下所示: propertyi=f(ei)(1) 其中,propertyi表示预测样本i的属性,ei表示定量构效关系模型生成的第i个预 测样本误差。 其中,所述步骤4具体包括: 在N个蒙特卡洛交互实验中选择观察值i的次数Ni为: 其中,Ni表示选择观察值i的次数,N表示进行蒙特卡洛交互实验的次数,n表示被m 5 CN 111613266 A 说 明 书 3/10 页 个离群值污染的总观察值,k表示预留观察值的个数。 其中,所述步骤4还包括: 异常观察值的概率p,如下所示: 其中,p表示异常观察值的概率,n表示被m个离群值污染的总观察值,m表示离群值 污染的个数,k表示预留观察值的个数。 其中,所述步骤5具体包括: 计算第j个样本的预测误差的平均值m(j)和标准差s(j),如下所示: 其中,m(j)表示第j个样本的预测误差的平均值,s(j)表示第j个样本的预测误差 的标准差,k表示在测试集中找到第j个样本的总次数,error(i)表示第i个循环中第j个样 本的预测误差。 其中,所述步骤6具体包括: 绘制以预测误差的平均值为X轴,以预测误差的标准差为Y轴的四分图,两条标准 线将样本划分为四个区域,其中,X轴的标准线设置为数据集主体平均值的2-2.5倍,Y轴的 标准线根据数据的实际误差进行设置。 本发明的上述方案有如下的有益效果: 本发明的上述实施例所述的基于定量构效关系的离群值检测方法,可同时识别和 处理X方向离群值、Y方向离群值和建模过程的离群值,并考虑了样本中离群值和因变量方 向的共存对定量构效关系模型质量的影响,计算方法过程和执行过程简单,降低了计算的 复杂度,可以对离群值和样本值进行可视化,具有良好的性能,多个离群值共存时可以克服 掩蔽效应带来的影响。 附图说明 图1为本发明的流程图; 图2为本发明的多元正态预测误差分布示意图; 图3为本发明的1060个模拟样本的平均值和标准差的分布示意图; 图4为本发明的离群值和正常样本分布四分图; 图5为本发明应用于模拟数据中误差标准差与误差均值的比较结果四分图(1); 图6为本发明应用于模拟数据中误差标准差与误差均值的比较结果示意图(2); 图7为本发明应用于工厂烟囱损失数据中误差标准差与误差均值对工厂烟囱损失 数据的影响四分图; 图8为本发明应用于沸点数据中在PLS模型中进行500个蒙特卡洛交互实验的 RMSECV值与主成分的数量示意图; 图9为本发明应用于溶解度数据中88种药物的误差标准差与误差均值的结果四分 6 CN 111613266 A 说 明 书 4/10 页 图; 图10为本发明应用于溶解度数据中采用留一法交叉验证的RMSECV值与PLS模型中 主成分的数量示意图。











