
技术摘要:
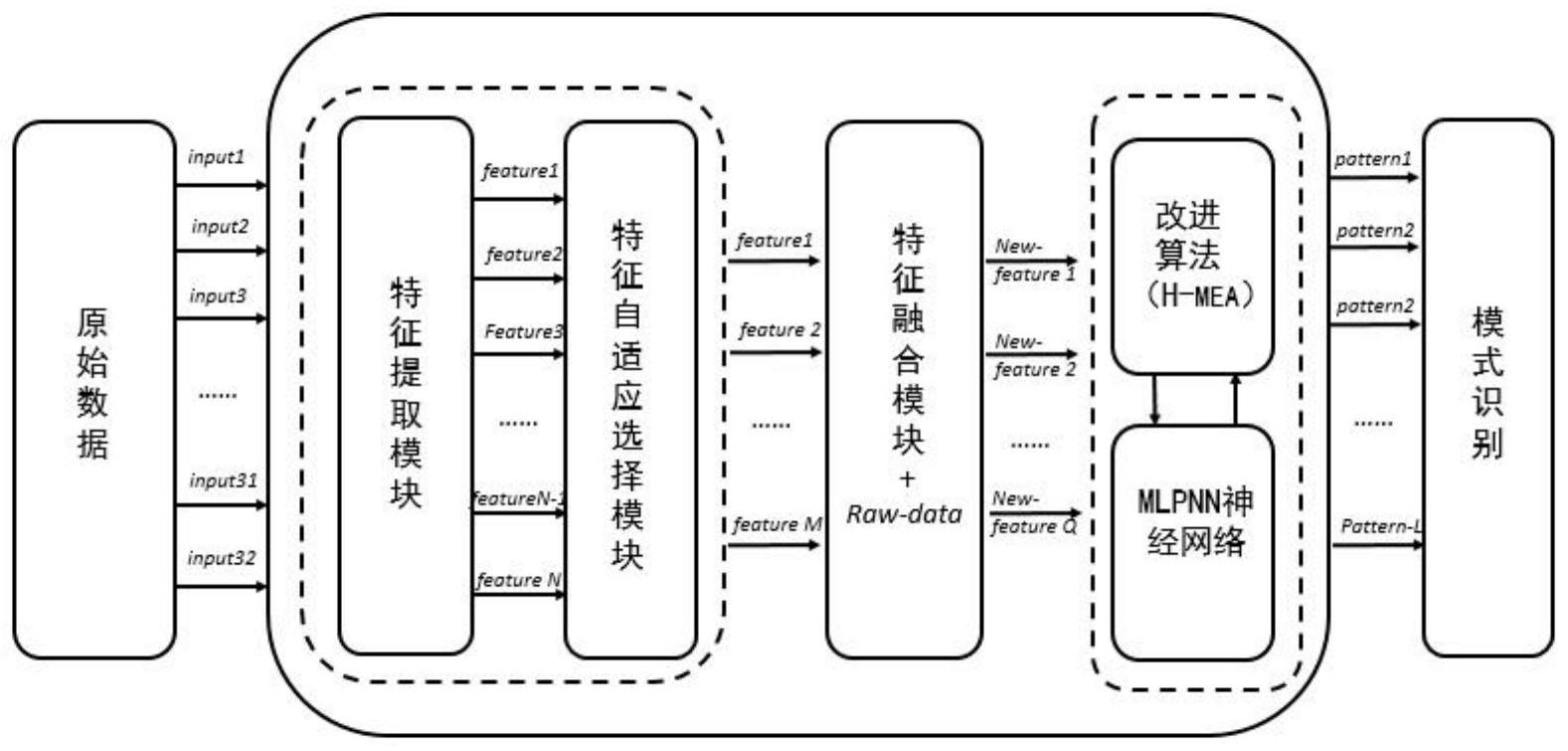
本发明公开了一种基于自适应特征选择及改进思维进化算法的质量趋势预测方法,该方法主要包括三个模块:特征自适应处理模块、数据融合模块、质量趋势预测模块。该方法的实现主要包括以下几个步骤:(1)设计相应参数生成建立该模型的数据;(2)应用误差影响程度算法建立特 全部
背景技术:
在航天、航空、船舶、汽车等领域应用广泛,由于在这些领域的产品大部分需要的 质量数据精度相对较高,在生产过程中产品会时常会受到人、机、料、法、环、测等多种因素 的影响,同时质量数据常常具有时变性、非线性、相关性和动态等特性常常会导致产品产生 较大的质量问题无法及时预测趋势提出修改措施,严重影响产品的使用性能和质量。 一直以来控制图作为质量控制及预测的辅助手段广泛用于生产过程中。控制图控 制质量数据的上下限捕捉产品质量的波动与异常,随着技术的发展与生产节奏的加快只通 过控制图的上下限来判断质量波动经常会出现较大的质量问题,无法适应现代加工数据采 集等现代化手段进行质量控制。目前有很多学者也开始研究控制图的模式以追求质量的精 准控制,但是大多数研究的模式较少、不对混合模式进行研究或是无法适应数据的动态变 化不能对数据进行自适应精准控制、识别、预测并且大多采用线下识别,智能化程度不够。 为实现产品智能化质量控制、提高产品质量提出一种基于自适应特征选择及改进 思维进化算法的质量趋势预测方法。本发明可实现智能化质量预测与控制,及时提出措施 进行修正并提高产品质量。
技术实现要素:
本发明的目的:针对质量数据的动态性、时变性等特性,基于控制图的多种模式提 出一种基于自适应特征选择及改进思维进化算法的质量趋势预测方法实现多种模式识别 并根据质量数据的时变性自适应选择特征预测动态生产过程中的线上产品质量趋势,同时 还应用改进思维进化算法优化MLPNN网络提高质量趋势的识别精度。解决现有质量趋势智 能化识别模式少、精度低、不能自适应变化、质量控制力度不够的问题,提高良品率达到智 能化生产及智能化趋势预测。 本发明提出来一种基于自适应特征选择及改进思维进化算法的质量趋势预测方 法解决上述问题,构建趋势预测模型以便能够预测异常状态。为实现上述目的,本发明采用 以下技术方案: 一种基于自适应特征选择及改进思维进化算法的质量趋势预测方法包括以下步 骤: 步骤1:生成模型建立所需数据。 生成9种模式的数据分别为正常模式(NOR)、周期模式(CYC)、系统模式(SYS)、分层 模式(STR)、上升趋势模式(IT)、下降趋势模式(DT)、向上阶跃模式(US)、向下阶跃模式 (DS)、混合模式(MIX)。 3 CN 111598435 A 说 明 书 2/9 页 步骤2:特征自适应处理模块建立。 在质量趋势预测的过程中,一般的常用方法直接应用数据进行趋势的预测精度不 高,该步骤的建立可将特征合理选择并进一步提高智能化程度。该模块建立分为两步: 第一步:建立特征提取模型,根据研究表明提取的数据特征包括以下统计特征和 形状特征更有说服力;其中,质量数据的统计特征包括:MEAN、VS、STD、SKEW、KURT、A;质量数 据的形状特征包括:SL、NC1、NC2、APML、APLS、AASL、ACLPI、SRANGE、SB、PSMLSC、REAE、ABDPE。 下列特征为质量数据在观测窗口所提取的,各个符号的含义如下: MEAE:质量数据的均值; VS:质量数据的均方值; STD:质量数据的标准差; SKEW:质量数据的偏态系数; KURT:质量数据的峰态系数; A:质量数据的自相关系数; SL:质量数据拟合的最小二乘回归线斜率; NC1:质量数据所成曲线与平均值所成线的交叉点数; NC2:质量数据所成曲线与最小二乘回归线的交叉点数; APML:质量数据所成曲线与平均线之间的面积; APLS:质量数据所成曲线与最小二乘回归线之间的面积; AASL:质量数据所成曲线分为四个区域,各区域中点组合连线所形成曲线斜率的 平均值 ACLPI:APML与质量数据的标准差之比; SRANGE:质量数据所成曲线分为四个区域,各区域中点连线所成斜率的最大值与 最小值之差; SB:质量数据最小二乘回归线的斜率标识符; PSMLSC:质量数据与中心线交点、最小二乘回归线交点和的平均值; REAE:质量数据的MSE与分成四个区域数据MSE平均值的误差之比; ABDPE:将质量数据所成曲线分为两个区域时,整体质量数据所成曲线最小二乘回 归线斜率与两个区域最小二乘回归线斜率平均值之差的绝对值。 第二步:建立自适应特征选取模型,该模型建立引入误差影响计算的方法。若有新 的数据可根据数据特性应用该模块选择合适的特征。基于不同种类的质量数据,根据特征 重要的程度选取不同的特征。 建立该模型的方法如下: a)设质量数据特征有N个,将质量数据特征进行预处理; b)建立初始MLPNN神经网络,并应用处理好的质量数据特征进行训练; c)若有新数据输入,预处理新质量数据特征并将每种质量数据特征数值分别增加 10%、减少10%共生成2N组数据,将每组数据分别带入MLPNN中进行识别得到2N个误差值, 然后将每种质量数据特征对应的增加10%、减少10%所得误差取平均值得到N个误差值; d)将误差由大到小排序选取前85%的特征规定为影响该质量数据程度较高的特 征。 4 CN 111598435 A 说 明 书 3/9 页 e)完成自适应质量数据特征选择模型。 步骤3:数据特征融合模块。 为了能更加精准的进行趋势的预测,将原始数据与自适应选择的数据进行融合。 若将原始数据直接与选择的特征进行质量趋势的预测,输入数据太过庞大、大大增加了模 型的计算复杂性,在数据降维方法中分为线性数据降维、非线性数据降维,该模块采用KPCA 数据降维方法将原始数据与特征数据进行融合,建立该模块的方法步骤如下: a)将组合数据进行标准化、中心化; b)构造组合数据的核函数,将数据映射到高维度中并计算核矩阵; c)计算的特征值、选择特征向量; d)进行数据降维、融合; 步骤4:建立质量趋势预测模块。 基于自适应特征融合后的数据建立3层感知器MLPNN神经网络模型,使用改进的思 维进化算法对MLPNN神经网络权值、阈值进行优化。 一般的思维进化算法主要是通过迭代优化的学习方式,进化过程中所有的个体叫 做群体,一个群体分为若干个子群。子群包括优胜子群和临时子群。在思维进化时优胜子群 和临时子群在飞行进化过程中是以最优的粒子为中心随机产生的子群没有任何的限制,子 群内粒子之间包含的信息程度也无法判断,从而产生对进化没有意义的粒子。在这里引入 互信息理论来判定子群进化的优劣程度。当子群内产生的粒子与中心粒子包含的信息程度 大于85%则认为此粒子为无效粒子,同时若某粒子的得分大于中心粒子则保留,否则就重 新生成该粒子。 建立改进思维进化算法方法步骤如下: a)初始化种群产生,在空间内生成种群; b)在初始化种群中选择得分较高的粒子分别作为优胜子群中心、临时子群中心并 产生子群。 c)引入信息判断算子:分别计算各优胜子群、临时子群的粒子与本身子群的中心 粒子之间的互信息程度,若个体粒子与中心粒子的互信息程度大于85%则认为是相似粒 子,同时若个体粒子比中心粒子得分高则保留,否则释放; d)趋同操作算子:计算所有子群中的个体粒子得分,选出优胜者作为中心重新生 成子群。同时进行步骤c操作,若子群中个体粒子与中心粒子包含信息程度合适则继续下一 步操作,否则重新生成粒子并进行步骤c操作。 e)判断是否各子群是否成熟,若子群成熟继续下一步操作,否则继续步骤d操作。 f)异化操作算子:将所有的成熟优胜子群和临时子群进行信息的交流,得分较高 的临时子群将代替得分较低的临时子群。 g)判断若成熟临时子群中没有得分超过成熟优胜子群则跳出循环,否则重复进行 步骤c-步骤g操作。 同时上述操作中在步骤d中以新的中心粒子生成新的子群时引入熵变理论增加粒 子生成的混沌程度,增加熵变惯性系数。在搜索前期要求范围较大且与中心粒子的信息保 持一定关系,后期则要求收敛较快,而引入惯性系数可提高对优秀粒子的搜索能力。 通过分析生产过程中的异常情况,根据质量数据的特点制定自适应选择合适特征 5 CN 111598435 A 说 明 书 4/9 页 的方法,并将自适应选择的特征与原始数据融合降低维度的同时增加识别精度,引入信息 判断算子和熵增理论改进的思维进化算法提高算法的精度及搜索能力,本发明的有益效果 是:能够根据质量数据的特性自适应选择合适的特征保证识别的精度;数据融合方法的使 用可增强质量趋势预测的性能,保证识别器具有良好的训练效率;改进的算法能够保证分 类时具有良好的容错性、分类能力更强。 附图说明 下面结合附图和实施例对本发明进行进一步说明 图1是本方法的流程图; 图2是9种模式的图像;(a)正常模式;(b)混合模式;(c)周期模式;(e)系统模式; (f)分层模式;(g)上升趋势;(h)下降趋势;(i)上阶跃趋势;(j)下阶跃模式; 图3是9种模式对应特征的分布图; 图4是特征融合的示意图 图5是改进思维进化算法的流程图 图6是思维进化算法粒子简化的示意图











