
技术摘要:
本申请公开了用于生成语音的方法和装置,涉及云计算技术领域。具体实施方式包括:获取针对用户语音的话术,其中,该话术包括被标记的目标字符串;基于该目标字符串在该话术中的位置,将该话术切分为多个子话术,其中,该多个子话术包括该目标字符串对应的目标子话术, 全部
背景技术:
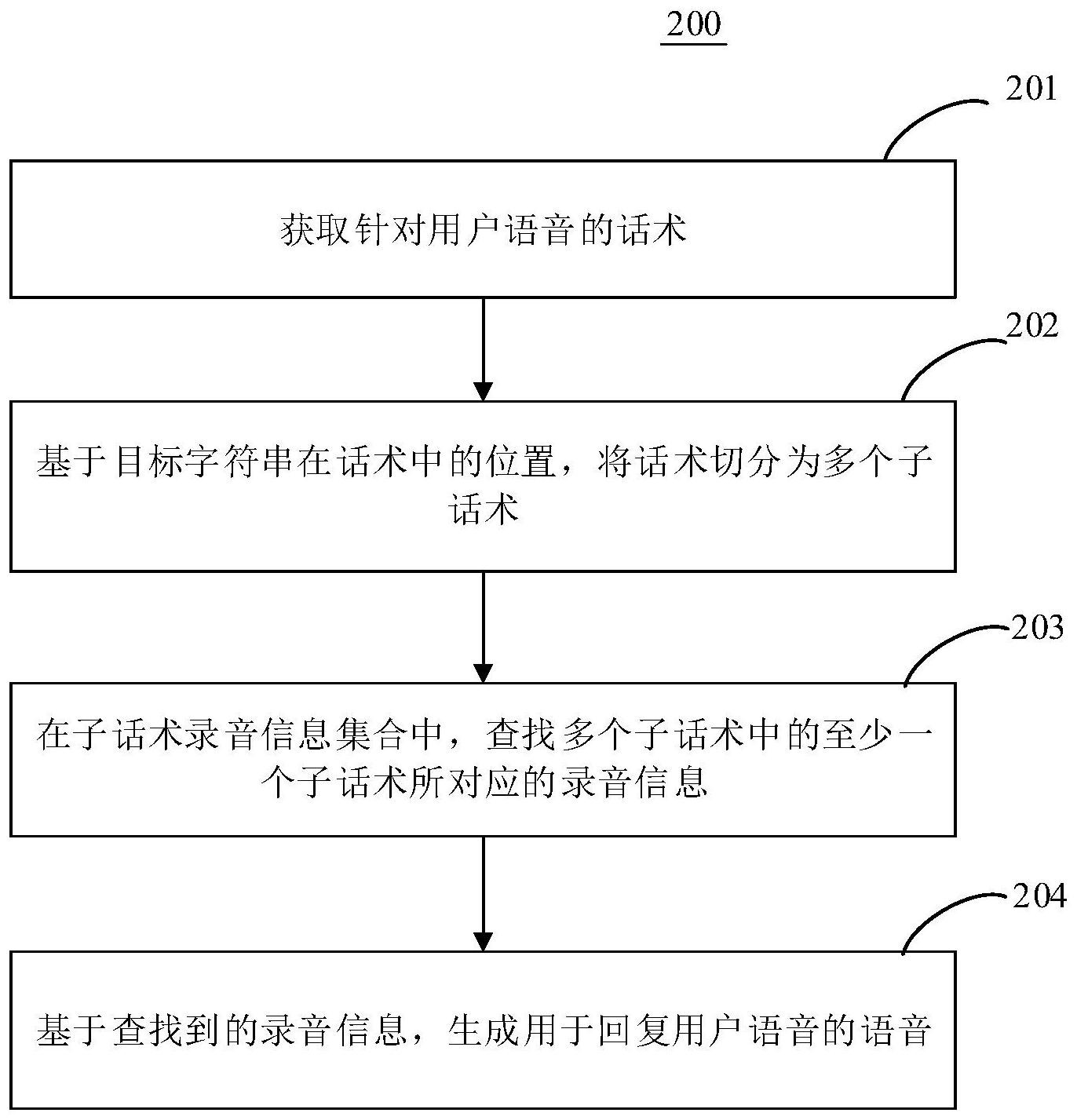
包括:获取 针对用户语音的话术,其中,该话术包括被标记 的目标字符串;基于该目标字符串在该话术中的 位置,将该话术切分为多个子话术,其中,该多个 子话术包括该目标字符串对应的目标子话术,以 及其它子话术;在子话术录音信息集合中,查找 该多个子话术中的至少一个子话术所对应的录 音信息;基于查找到的录音信息,生成用于回复 该用户语音的语音。本申请的方案通过切分,查 找子话术对应的录音信息,从而无需对整个话术 进行实时合成,提高了语音交互的效率。 CN 111599341 A CN 111599341 A 权 利 要 求 书 1/4 页 1.一种用于生成语音的方法,所述方法包括: 获取针对用户语音的话术,其中,所述话术包括被标记的目标字符串; 基于所述目标字符串在所述话术中的位置,将所述话术切分为多个子话术,其中,所述 多个子话术包括所述目标字符串对应的目标子话术,以及其它子话术; 在子话术录音信息集合中,查找所述多个子话术中的至少一个子话术所对应的录音信 息; 基于查找到的录音信息,生成用于回复所述用户语音的语音。 2.根据权利要求1所述的方法,其中,所述方法还包括: 对所述多个子话术中,所述至少一个子话术以外的子话术合成录音;以及 所述基于查找到的录音信息,生成用于回复所述用户语音的语音,包括: 将查找到的录音信息所对应的录音与合成的录音进行合并,生成用于回复所述用户语 音的语音。 3.根据权利要求2所述的方法,其中,所述在子话术录音信息集合中,查找所述多个子 话术中的至少一个子话术所对应的录音信息,包括: 在子话术录音信息集合中,查找所述多个子话术分别对应的录音信息;以及 所述对所述多个子话术中,所述至少一个子话术以外的子话术合成录音,包括: 响应于所述多个子话术中,存在没有对应的录音信息的子话术,合成该子话术对应的 录音。 4.根据权利要求2所述的方法,其中,所述目标子话术为固定子话术和变量子话术中的 一者,所述其它子话术为所述固定子话术和变量子话术中的另一者; 所述在子话术录音信息集合中,查找所述多个子话术中的至少一个子话术所对应的录 音信息,包括: 在子话术录音信息集合中,查找所述多个子话术中的固定子话术所对应的录音信息; 以及 所述对所述多个子话术中,所述至少一个子话术以外的子话术合成录音,包括: 合成所述多个子话术中的变量子话术的录音。 5.根据权利要求1-4之一所述的方法,其中,所述子话术录音信息集合中的录音信息包 括与录音相对应的信息摘要算法数值; 所述在子话术录音信息集合中,查找所述多个子话术中的至少一个子话术所对应的录 音信息,包括: 对于所述至少一个子话术中的每个子话术,确定该子话术对应的信息摘要算法数值; 在子话术录音信息集合中,查找与该子话术对应的信息摘要算法数值相同的信息摘要 算法数值;以及 所述基于查找到的录音信息,生成用于回复所述用户语音的语音,包括: 获取查找到的信息摘要算法数值所对应的录音,生成包括所获取的录音的、用于回复 所述用户语音的语音。 6.根据权利要求1所述的方法,其中,所述方法还包括: 获取包括指定子话术的子话术集合,其中,所述子话术集合中与所述多个子话术中存 在相同的子话术; 2 CN 111599341 A 权 利 要 求 书 2/4 页 合成所述子话术集合中的各个指定子话术的录音,并存储到存储空间; 获取所述各个指定子话术中每个指定子话术对应的信息摘要算法数值; 对于每个指定子话术,将该指定子话术对应的信息摘要算法数值,以及对该指定子话 术合成的录音在所述存储空间中的存储地址,在缓存空间中的所述子话术录音信息集合中 进行对应缓存。 7.根据权利要求2所述的方法,其中,所述方法还包括: 对于合成的录音,将该录音存储到存储空间; 确定该录音对应的子话术对应的信息摘要算法数值,作为待缓存的信息摘要算法数 值; 将所述待缓存的信息摘要算法数值以及该录音在所述存储空间中的存储地址,在缓存 空间中的所述子话术录音信息集合中进行对应缓存。 8.根据权利要求6或7所述的方法,其中,所述各个指定子话术和所述多个子话术中均 包括固定子话术和变量子话术; 在缓存空间中的所述子话术录音信息集合中,固定子话术所对应的信息摘要算法数值 以及存储地址,与变量子话术所对应的信息摘要算法数值以及存储地址,分别缓存于不同 的录音信息子集中;和/或,在缓存空间中的所述子话术录音信息集合中,固定子话术所对 应的信息摘要算法数值以及存储地址,与变量子话术所对应的信息摘要算法数值以及存储 地址,带有不同的标识。 9.根据权利要求6或7所述的方法,其中,所述话术的任一子话术对应的信息摘要算法 数值,基于以下两者确定:所述任一子话术,和所述任一子话术的语音合成配置信息。 10.根据权利要求2所述的方法,其中,所述方法还包括: 获取所述话术的语音合成配置信息;以及 所述对所述多个子话术中,所述至少一个子话术以外的子话术合成录音,包括: 按照所获取的语音合成配置信息,对所述多个子话术中,所述至少一个子话术以外的 子话术合成录音。 11.根据权利要求1所述的方法,其中,所述基于所述目标字符串在所述话术中的位置, 将所述话术切分为多个子话术,包括: 对于所述话术中至少一个所述目标字符串中目标字符串的边缘字符,以该边缘字符与 相邻的其它字符之间的位置作为切分位置,将所述话术切分为至少一个目标子话术与至少 一个其它子话术,其中,所述其它字符为目标字符串以外的字符。 12.一种用于生成语音的装置,所述装置包括: 获取单元,被配置成获取针对用户语音的话术,其中,所述话术包括被标记的目标字符 串; 切分单元,被配置成基于所述目标字符串在所述话术中的位置,将所述话术切分为多 个子话术,其中,所述多个子话术包括所述目标字符串对应的目标子话术,以及其它子话 术; 查找单元,被配置成在子话术录音信息集合中,查找所述多个子话术中的至少一个子 话术所对应的录音信息; 生成单元,被配置成基于查找到的录音信息,生成用于回复所述用户语音的语音。 3 CN 111599341 A 权 利 要 求 书 3/4 页 13.根据权利要求12所述的装置,其中,所述装置还包括: 合成单元,被配置成对所述多个子话术中,所述至少一个子话术以外的子话术合成录 音;以及 所述生成单元进一步被配置成按照如下方式执行所述基于查找到的录音信息,生成用 于回复所述用户语音的语音: 将查找到的录音信息所对应的录音与合成的录音进行合并,生成用于回复所述用户语 音的语音。 14.根据权利要求13所述的装置,其中,所述查找单元,进一步被配置成按照如下方式 执行所述在子话术录音信息集合中,查找所述多个子话术中的至少一个子话术所对应的录 音信息: 在子话术录音信息集合中,查找所述多个子话术分别对应的录音信息;以及 所述合成单元,进一步被配置成按照如下方式执行所述对所述多个子话术中,所述至 少一个子话术以外的子话术合成录音: 响应于所述多个子话术中,存在没有对应的录音信息的子话术,合成该子话术对应的 录音。 15.根据权利要求13所述的装置,其中,所述目标子话术为固定子话术和变量子话术中 的一者,所述其它子话术为所述固定子话术和变量子话术中的另一者; 所述查找单元,进一步被配置成按照如下方式执行所述在子话术录音信息集合中,查 找所述多个子话术中的至少一个子话术所对应的录音信息: 在子话术录音信息集合中,查找所述多个子话术中的固定子话术所对应的录音信息; 以及 所述合成单元,进一步被配置成按照如下方式执行所述对所述多个子话术中,所述至 少一个子话术以外的子话术合成录音: 合成所述多个子话术中的变量子话术的录音。 16.根据权利要求12-15之一所述的装置,其中,所述子话术录音信息集合中的录音信 息包括与录音相对应的信息摘要算法数值; 所述查找单元,进一步被配置成按照如下方式执行所述在子话术录音信息集合中,查 找所述多个子话术中的至少一个子话术所对应的录音信息: 对于所述至少一个子话术中的每个子话术,确定该子话术的信息摘要算法数值; 在子话术录音信息集合中,查找与该子话术的信息摘要算法数值相同的信息摘要算法 数值;以及 所述生成单元进一步被配置成按照如下方式执行所述基于查找到的录音信息,生成用 于回复所述用户语音的语音: 获取查找到的信息摘要算法数值所对应的录音,生成包括所获取的录音的、用于回复 所述用户语音的语音。 17.根据权利要求12所述的装置,其中,所述装置还包括: 集合获取单元,被配置成获取包括指定子话术的子话术集合,其中,所述子话术集合中 与所述多个子话术中存在相同的子话术; 第一存储单元,被配置成合成所述子话术集合中的各个指定子话术的录音,并存储到 4 CN 111599341 A 权 利 要 求 书 4/4 页 存储空间; 数值获取单元,被配置成获取所述各个指定子话术中每个指定子话术对应的信息摘要 算法数值; 第一缓存单元,被配置成对于每个指定子话术,将该指定子话术对应的信息摘要算法 数值,以及对该指定子话术合成的录音在所述存储空间中的存储地址,在缓存空间中的所 述子话术录音信息集合中进行对应缓存。 18.根据权利要求13所述的装置,其中,所述装置还包括: 第二存储单元,被配置成对于合成的录音,将该录音存储到存储空间; 数值确定单元,被配置成确定该录音对应的子话术的信息摘要算法数值,作为待缓存 的信息摘要算法数值; 第二缓存单元,被配置成将所述待缓存的信息摘要算法数值以及该录音在所述存储空 间中的存储地址,在缓存空间中的所述子话术录音信息集合中进行对应缓存。 19.根据权利要求17或18所述的装置,其中,所述各个指定子话术和所述多个子话术中 均包括固定子话术和变量子话术; 在缓存空间中的所述子话术录音信息集合中,固定子话术所对应的信息摘要算法数值 以及存储地址,与变量子话术所对应的信息摘要算法数值以及存储地址,分别缓存于不同 的录音信息子集中;和/或,在缓存空间中的子话术录音信息集合中,固定子话术所对应的 信息摘要算法数值以及存储地址,与变量子话术所对应的信息摘要算法数值以及存储地 址,带有不同的标识。 20.根据权利要求17或18所述的装置,其中,所述话术的任一子话术对应的信息摘要算 法数值,基于以下两者确定:所述任一子话术,和所述任一子话术的语音合成配置信息。 21.根据权利要求13所述的装置,其中,所述装置还包括: 配置获取单元,被配置成获取所述话术的语音合成配置信息;以及 合成单元,进一步被配置成按照如下方式执行所述对所述多个子话术中,所述至少一 个子话术以外的子话术合成录音: 按照所获取的语音合成配置信息,对所述多个子话术中,所述至少一个子话术以外的 子话术合成录音。 22.根据权利要求12所述的装置,其中,所述切分单元,进一步被配置成按照如下方式 执行所述基于所述目标字符串在所述话术中的位置,将所述话术切分为多个子话术: 对于所述话术中至少一个所述目标字符串中目标字符串的边缘字符,以该边缘字符与 相邻的其它字符之间的位置作为切分位置,将所述话术切分为至少一个目标子话术与至少 一个其它子话术,其中,所述其它字符为目标字符串以外的字符。 23.一种电子设备,包括: 一个或多个处理器; 存储装置,用于存储一个或多个程序, 当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实 现如权利要求1-11中任一所述的方法。 24.一种计算机可读存储介质,其上存储有计算机程序,其中,该程序被处理器执行时 实现如权利要求1-11中任一所述的方法。 5 CN 111599341 A 说 明 书 1/12 页 用于生成语音的方法和装置 技术领域 本申请实施例涉及计算机技术领域,具体涉及语音技术领域,尤其涉及用于生成 语音的方法和装置。
技术实现要素:
语音合成(Text To Speech,TTS)技术的应用越来越广泛,具体地,语音合成可以 应用于人机交互的场景中。比如,电子设备可以和用户进行通话。在通话过程中,电子设备 可以获取用户的语音,将语音转成文字,并对文字进行自然语音处理,之后基于处理结果, 生成回复语音。 在相关技术中,语音合成技术随着交互语言越来越复杂也即文本字符数的增长, 语音合成引擎的耗时也随之增长,可能导致用户说完话,机器设备需要一段时间才能做出 反馈。











