
技术摘要:
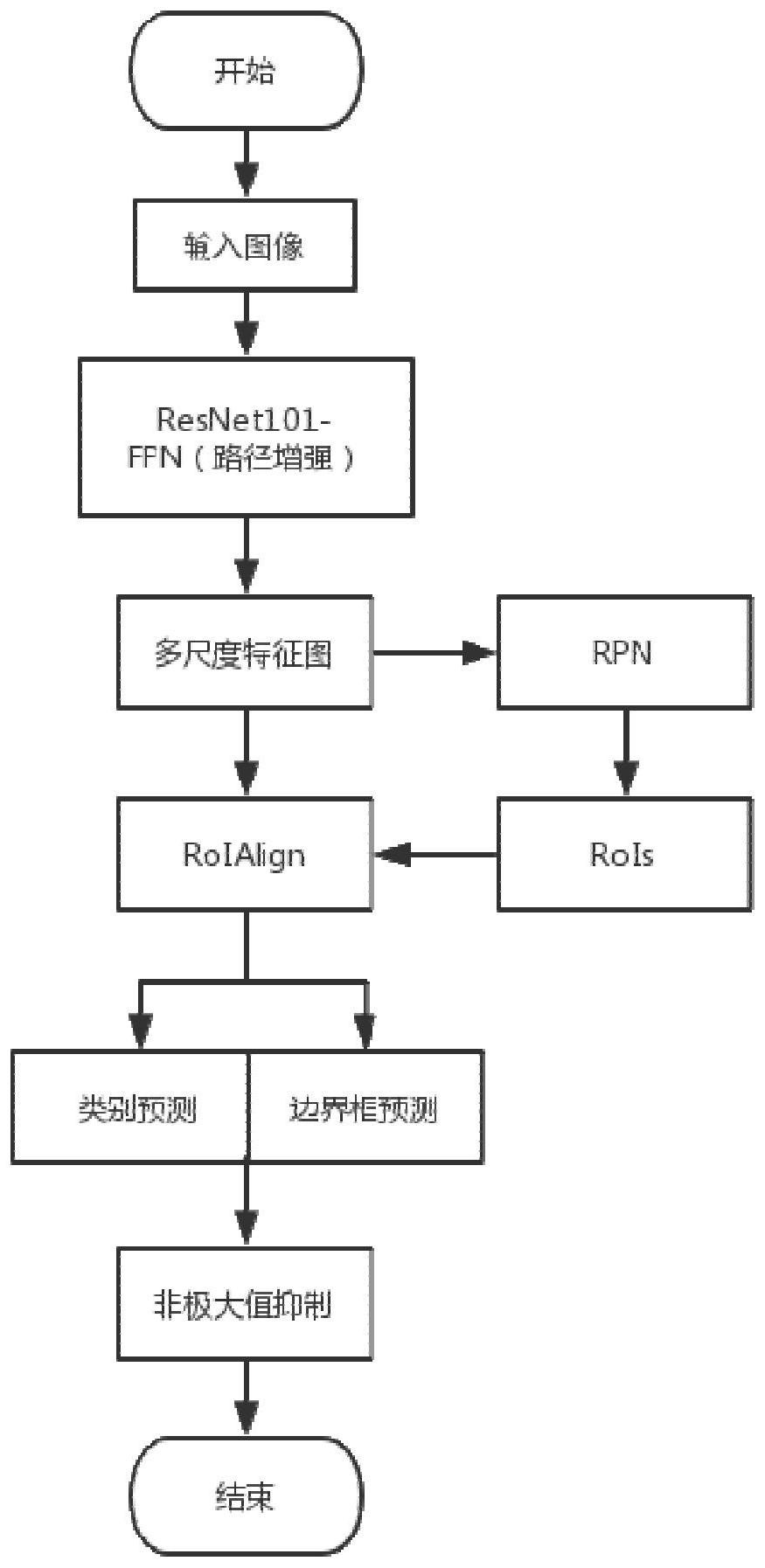
本发明公开了一种基于改进Faster R‑CNN的车内遗失物体检测方法,输入图片首先经过路径增强的ResNet101‑FPN提取多尺度特征图,RPN网络生成锚框并判断其前后景以及预测偏移量,锚框结合偏移量并通过非极大值抑制筛选出RoIs,RoIs与对应的特征图一起输入RoIAlign,RoIAl 全部
背景技术:
计算机视觉包含几类基础任务:图像分类,目标检测,语义分割,实例分割,目标跟 踪等。基于深度学习的计算机视觉模型往往可以取得更高精度的预测结果,其主要包括以 SSD,YOLO为代表的一阶段检测模型,和以R-CNN系列为代表的二阶段检测模型。一阶段的检 测模型是直接对锚框进行预测的,而二阶段的检测模型首先通过RPN生成候选区域,然后对 候选区域进行预测。 车内遗失物体检测是计算机视觉领域在智能驾驶方向上的一个应用,其核心是使 用车载摄像头来代替人眼采集乘客下车瞬间的车内照片,将采集到的图像输入到视觉算法 中进行分析,最终判断车内是否存在遗失物体以便于司机通知乘客领取。这里提到的视觉 算法有很多种,例如,传统的图像处理方法以及近些年的深度学习方法等。在深度学习出现 以前,传统的图像处理和机器学习方法并不能很好地完成一个简单的图像分类任务,而深 度学习的出现使得计算机有了达到人类水平的可能,原始的FPN经过一次特征融合使得较 浅层的特征图有了明确的语义信息和位置信息,适用于检测小物体,但是较深层的特征图 仍然缺少明确的位置信息,这使得对大物体的边界框预测不准确。 Girshick R,Donahue J等人提出的R-CNN模型首先通过选择性搜索生成2000个 RoI,然后将全部的RoI通过主干网络提取特征,最后通过SVM分类器和回归模型进行分类和 边界框预测,但是R-CNN的速度很慢,训练和预测过程都需要将上千个RoI全部通过主干网 络获取特征,这个步骤将花费大量的时间,在实际应用中无法做到实时性检测,并且主干网 络,分类器和回归模型均单独训练,主干网络的参数不会因训练SVM和回归模型而更新,这 导致模型检测精度不够高。Girshick R提出的Fast R-CNN将RoI共享主干网络卷积计算,只 需要将原图进行一次前向传播获取特征图,RoI在特征图对应位置上提取特征即可,引入 RoI Pooling将RoI统一到相同尺寸使得分类和回归部分可以同主干网络一起训练,但是前 期的选择性搜索仍然占用了大部分计算时间。
技术实现要素:
本发明要解决的技术问题是:现有基于Faster R-CNN的车内遗失物体检测对大物 体边界框预测效果欠佳的问题。 为了解决上述问题,本发明的技术方案是提供了一种基于改进Faster R-CNN的车 内遗失物体检测方法,包括以下步骤: 步骤1、构建一种改进的Faster R-CNN目标检测模型,所述目标检测模型包括在原 始FPN结构中加入一条自底向上的路径增强分支并结合ResNet基础网络形成的路径增强的 ResNet-FPN主干网络、RPN网络、RoIAlign和Head结构; 3 CN 111553414 A 说 明 书 2/4 页 步骤1-1、通过上述ResNet-FPN主干网络提取输入图片的多尺度特征图; 步骤1-2、将步骤1-1中的多尺度特征图输入RPN网络,RPN网络基于多尺度特征图 生成锚框并判断其前后景和边界框偏移量,并通过非极大值抑制生成RoIs; 步骤1-3、将步骤1-2生成的RoIs与对应的特征图一起输入RoIAlign,RoIAlign将 RPN网络生成的RoIs映射到对应的多尺度特征图上,池化得到统一大小的RoIs作为Head结 构的输入; 步骤1-4、Head结构对步骤1-3中的RoIs逐个进行分类并预测边界框偏移量; 步骤2、采集不同种类的易遗失物体图像作为样本图像制作遗失物体数据集,对样 本图像进行标注类别和边界框,并将数据集划分为训练集、验证集和测试集; 步骤3、将步骤1中的目标检测模型在训练集上进行训练并使用验证集验证; 步骤4、将测试集图像输入训练好的目标检测模型进行测试,对输出边界框进行非 极大值抑制,去除重复的边界框得到最终测试结果。 优选地,所述路径增强的ResNet-FPN主干网络包括原始FPN结构和自底向上的路 径增强分支,设FPN结构输出为[P2,P3,…,Pn],ResNet-FPN主干网络输出为[N2,N3,…,Nn, Nn 1],N2即P2,N2首先进行步幅为2的3x3卷积进行2倍下采样,然后与P3作逐元素求和并进 行步幅为1的3x3卷积得到N3,同理得到N4,N5,…,Nn,Nn进行最大池化得到Nn 1。 优选地,所述Head结构包括分类和边界框回归两个分支。 优选地,所述步骤2中按照8:1:1的比例将数据集划分为训练集、验证集和测试集。 优选地,所述步骤3中模型训练包括以下步骤: 步骤3-1、对步骤1中改进的Faster R-CNN模型进行初始化参数设置,利用ResNet 在ImageNet上预训练的参数作迁移学习,设置迭代次数为40000次,SGD为优化器,前30k迭 代,学习率0.001,后10k迭代,学习率0.0001,训练的batchsize为2,进行网络训练; 步骤3-2、设置输入数据类别数num_class为样本图像的类别总数加一个背景类。 优选地,所述步骤1中的基础网络采用ResNet101。 优选地,所述步骤1-3中RoIAlign所采用的池化窗口大小为7x7。 优选地,所述步骤2中样本图像的数量为至少1000张。 与现有技术相比,本发明的有益效果是: 本发明在主干网络FPN结构中引入了自底向上的路径增强分支,使得主干网络输 出的深层特征图能同时具备较明确语义信息和位置信息,同时应用RoIAlign防止两次量化 导致的池化前后RoI不匹配问题,本发明检测方法能够适应各种尺寸的物体,同时对于大物 体的边界框也能够进行准确的预测,使得对大物体的检测更加准确。 附图说明 图1为本发明模型执行检测的流程图; 图2为本发明模型的整体网络框架图; 图3为本发明模型的主干网络结构图; 图4为本发明模型在车内遗失物体图像上的测试效果图。 4 CN 111553414 A 说 明 书 3/4 页











