
技术摘要:
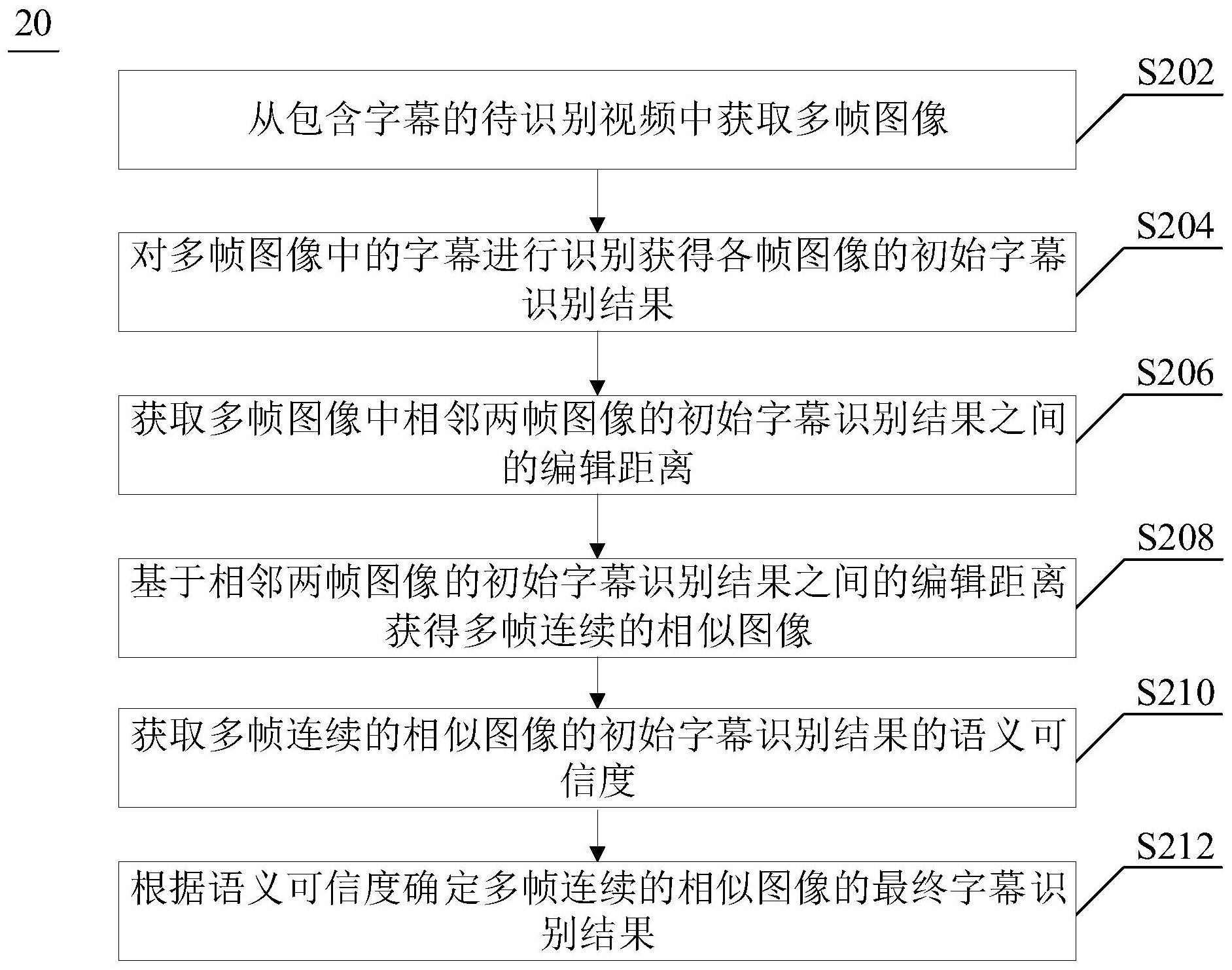
本公开提供一种视频字幕识别方法、装置、设备及存储介质,涉及计算机视觉技术领域。该方法包括:从包含字幕的待识别视频中获取多帧图像;对所述多帧图像中的字幕进行识别获得各帧图像的初始字幕识别结果;获取所述多帧图像中相邻两帧图像的初始字幕识别结果之间的编辑 全部
背景技术:
随着计算机技术及互联网的发展,用户可接触到的视频的语言种类也日趋丰富。 用户处理各种语言的视频时,可通过视频字幕提取技术从视频中提取、识别字幕,用于各种 用途,例如视频分类。 对视频字幕进行识别时通常采用光学字符识别(O pti ca l C ha ra c te r Recognition,OCR)技术。OCR解决方案一般包含两个步骤:1)文本区域检测:找到包含文字 的区域;2)文本识别:识别区域中的文字。相关技术中采用OCR识别模型进行字幕文本识别 时,由于视频背景图像较为复杂,可能发生某些字符识别错误的情况,字幕识别结果的准确 率较低。相关技术中在进行文本区域检测时采用CTPN或EAST基于深度学习的算法,在相对 简单的场景下,检测效果较好,但耗时较长,检测效率较低。相关技术中OCR识别模型在针对 具体的应用场景进行识别时具有局限性,例如在对视频字幕进行识别时,视频字幕的背景 复杂,采用相关技术中的OCR识别模型进行字幕识别的准确性较差;又例如没有针对小语种 视频字幕的OCR识别方法,无法识别出小语种视频的字幕。 如上所述,如何提供能够准确识别视频中字幕的方法成为亟待解决的问题。 在所述
技术实现要素:
部分公开的上述信息仅用于加强对本公开的背景的理解,因此它 可以包括不构成对本领域普通技术人员已知的现有技术的信息。











