
技术摘要:
本公开提供一种音频识别方法、装置、电子设备及存储介质,所述方法包括:获取音频信息并输入到音频识别模型,得到音频对及音频对的开始时间和结束时间及识别文本;将识别文本进行分词后,将分词在基准文件库中匹配搜索;根据音频对在多个基准文件中匹配搜索,筛选出音 全部
背景技术:
现有的音频识别方法通常是根据由设备采集到的音频信息,通过对音频信息中包 含的文字进行识别,得到音频文件对应的音频信息,但因音频信息的不完整导致对于音频 的识别成功率往往不高,并且即使通过现有技术识别出了文字,最终识别的准确率也不高。 对于短视频中的音频进行识别,需要在保证实时通用准确率的前提下同时提高准 确率,但目前在音频识别领域中还没有针对短视频的音频进行识别的模型或方法,并且在 视频平台上对实时音频的字幕需求则更高,现有对于音频的解析存在一定的延时,难以满 足进行实时识别及预测的需求。
技术实现要素:
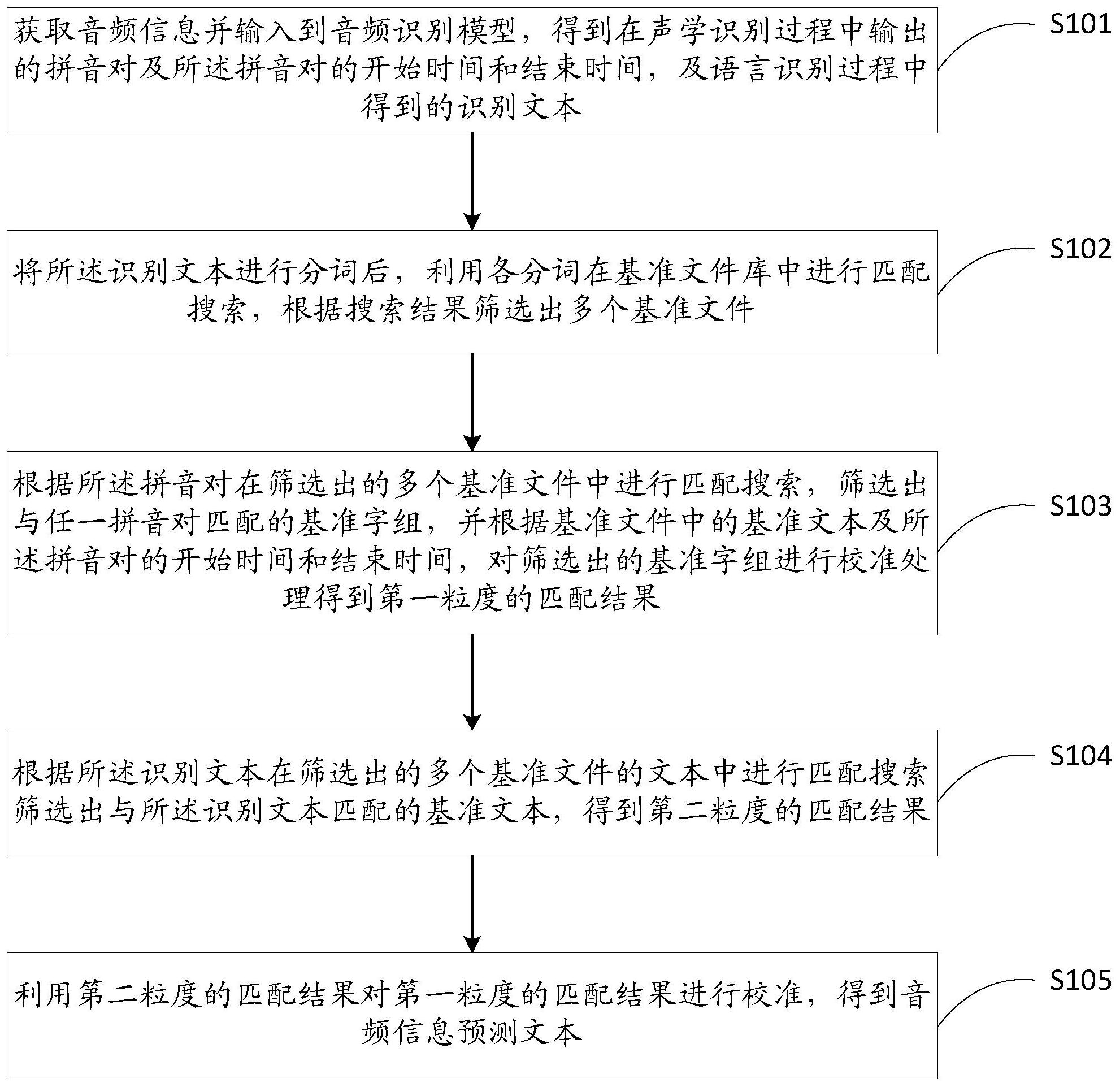
本公开提供的一种音频识别方法、装置、电子设备及存储介质,用于解决音频信息 的不完整导致对于音频的识别成功率往往不高,并且即使通过现有技术识别出了文字,最 终识别的准确率也不高的问题; 本公开第一方面提供一种音频识别方法,该方法包括: 获取音频信息并输入到音频识别模型,得到在声学识别过程中输出的音频对及所 述音频对的开始时间和结束时间,及语言识别过程中得到的识别文本; 将所述识别文本进行分词后,利用各分词在基准文件库中进行匹配搜索,根据搜 索结果筛选出多个基准文件; 根据所述音频对在筛选出的多个基准文件中进行匹配搜索,筛选出与任一音频对 匹配的基准字组,并根据基准文件中的基准文本及所述音频对的开始时间和结束时间,对 筛选出的基准字组进行校准处理得到第一粒度的匹配结果; 根据所述识别文本在筛选出的多个基准文件的文本中匹配搜索,筛选出与所述识 别文本匹配的基准文本,得到第二粒度的匹配结果; 利用第二粒度的匹配结果对第一粒度的匹配结果进行校准,得到音频信息预测文 本,其中所述第二粒度高于第一粒度。 可选地,利用各分词在基准文件库中匹配搜索,根据搜索结果筛选出多个基准文 件,包括: 对于各分词,查找基准文件库中出现该分词的基准文本; 根据所有分词的查找结果,利用基准文件中出现分词的个数和或次数对基准文件 的筛选。 对于筛选出的多个基准文件,根据分词在基准文本中的位置、顺序、是否连续来判 断与原基准文件的相似度,进一步筛选出相似度大于相似度阈值的多个基准文件。 4 CN 111552777 A 说 明 书 2/23 页 可选地,利用各分词在基准文件库中匹配搜索之前,还包括: 过滤基准文件库中与识别文本无关的非基准文本。 可选地,根据所述音频对在筛选出的多个基准文件中进行匹配搜索,筛选出与任 一音频对匹配的基准字组,并根据基准文件中的基准文本及所述音频对的开始时间和结束 时间,对筛选出的基准字组进行校准处理,包括: 将筛选出的各基准文件中的基准文本从前向后划分字组,筛选出与任一音频对匹 配的基准字组,所述字组的字数大于音频对个数; 根据所述音频对的开始时间和结束时间,标识与所述音频对匹配的基准字组的开 始时间和结束时间,并根据标识的基准字组的开始时间的先后顺序,对筛选出来的基准字 组进行排序; 将排序后的基准字组与划分的字组的顺序进行比较,确定出现乱序的基准字组并 删除。 可选地,根据所述音频对的开始时间和结束时间,标识与所述音频对匹配的基准 字组的开始时间和结束时间,包括: 确定基准字组仅与一个音频对匹配时,将所述音频对的开始时间标识为所述基准 字组的开始时间,将所述音频对的结束时间标识为所述基准字组的结束时间;或, 确定基准字组同时与至少两个音频对匹配时,将所述至少两个音频对的最早开始 时间,标识为所述基准字组的开始时间,将所述至少两个音频对的最晚结束时间,标识为所 述基准字组的结束时间。 可选地,确定出现乱序的基准字组并删除之后,还包括: 确定开始时间相同的基准字组为重复使用的基准字组,从当前的基准字组中删除 重复使用的基准字组,及从划分的字组中删除重复使用的基准字组,并在划分的字组中保 留删除的基准字组的位置; 对当前划分的字组从后向前检测,检测到保留的位置可以容纳之后的字组时,将 之后的字组向前移动覆盖所述保留的位置至与最近的字组相邻; 确定当前划分的字组仍存在未被覆盖的保留的位置时,将未被覆盖的保留的位置 对应删除的基准字组,按照开始时间回填到当前基准字组中。 可选地,确定出现乱序的基准字组并删除之后,包括: 通过比较当前基准字组与划分的字组,确定间隔的字组数超过预设个数的不连续 的基准字组; 确定所述不连续的基准字组之前和之后的连续基准字组,并将所述之后的连续基 准字组的第一个基准字组删除后向前移动覆盖n个基准字组位置,n为所述之后的连续基准 字组删除第一个基准字组后的基准字数的个数; 将删除的第一个基准字组,按照开始时间回填到当前基准字组中。 可选地,确定出现乱序的基准字组并删除之后,包括: 通过比较当前基准字组与划分的字组,确定间隔的字组数超过预设个数的不连续 的基准字组; 确定所述不连续的基准字组之前和之后的连续基准字组,并将所述之前的连续基 准字组的最后一个基准字组删除后向后移动覆盖n个基准字组位置,n为所述之前的连续基 5 CN 111552777 A 说 明 书 3/23 页 准字组删除最后一个基准字组后的基准字数的个数; 将删除的最后一个基准字组,按照开始时间回填到当前基准字组中。 可选地,确定出现乱序的基准字组并删除之后,包括如下至少一个步骤: 根据当前基准字组的开始时间,过滤开始时间间隔大于设定时间第一阈值的基准 字组; 根据当前基准字组的开始时间,过滤开始时间间隔小于设定时间第二阈值的基准 字组,所述第一时间阈值大于所述第二时间阈值。 可选地,确定出现乱序的基准字组并删除之后,包括如下至少一个步骤: 确定当前任一基准字组的开始时间和结束时间大于设定值时,且占据两个基准文 本的首尾连接处时,删除该基准字组中占据其中一个基准文本的文字。 可选地,确定出现乱序的基准字组并删除之后,包括: 利用当前基准字组中基准单字在基准文本中进行标注,根据在基准文本的整句文 本的标注结果,确定当前基准字组中冗余部分及与整句文本的匹配度小于设定阈值的部分 并进行过滤。 可选地,根据在基准文本的整句文本的标注结果,确定当前基准字组中冗余部分 并进行过滤,包括: 确定基准文本中的整句文本被重复标注时,将重复标注整句文本的基准单字合并 处理;和/或 确定被标注的整句文本中,是否存在与多个连续被标注的整句文本之间的间隔超 过设定距离的整句文本时,若是,删除标注该整句文本的基准单字。 可选地,根据在基准文本的整句文本的标注结果,确定当前基准字组中与整句文 本的匹配度小于设定阈值的部分并进行过滤,包括: 确定被标注的整句文本中,被基准单字标注的文字长度与整句文本的长度占比低 于设定比例值时,删除标注该整句文本的基准单字。 可选地,根据所述识别文本在筛选出的多个基准文件的文本中匹配搜索,筛选出 与所述识别文本匹配的基准文本,得到第二粒度的匹配结果,包括: 确定所述识别文本中的整句识别文本,根据所述整句识别文本的多个音频对在多 个基准文件中匹配搜索,根据所述多个音频对与整句文本的匹配结果筛选出基准文本。 可选地,利用第二粒度的匹配结果对第一粒度的匹配结果进行校准,包括如下至 少一个步骤: 将利用第二粒度的匹配结果对第一粒度的匹配结果进行对比,对所述第一粒度的 匹配结果的整句文本中缺少的文字进行填补; 将利用第二粒度的匹配结果对第一粒度的匹配结果进行对比,确定所述第一粒度 的匹配结果中不连续的整句文本,并对缺少的整句文本进行填补。 可选地,利用第二粒度的匹配结果对第一粒度的匹配结果进行校准,得到音频信 息预测文本,包括: 利用当前第二粒度的匹配结果中的单字在第一粒度的匹配结果对应的基准文本 中进行标注; 根据在基准文本的整句文本的标注结果,确定当前第一粒度的匹配结果中冗余部 6 CN 111552777 A 说 明 书 4/23 页 分及与整句文本的匹配度小于设定阈值的部分并进行过滤。 可选地,根据在基准文本的整句文本的标注结果,确定当前基准字组中冗余部分 并进行过滤,包括: 确定基准文本中的整句文本被重复标注时,将重复标注整句文本的基准单字合并 处理;和/或 确定被标注的整句文本中,是否存在与多个连续被标注的整句文本之间的间隔超 过设定距离的整句文本时,若是,删除标注该整句文本的基准单字。 可选地,根据在基准文本的整句文本的标注结果,确定当前基准字组中与整句文 本的匹配度小于设定阈值的部分并进行过滤,包括: 确定被标注的整句文本中,被基准单字标注的文字长度与整句文本的长度占比低 于设定比例值时,删除标注该整句文本的基准单字。 可选地,利用第二粒度的匹配结果对第一粒度的匹配结果进行校准,得到音频信 息预测文本,包括: 利用第二粒度的匹配结果对第一粒度的匹配结果进行校准后,确定当前长度最大 的基准字组对应的基准文件; 确定获取音频信息的时间与当前时间的时间差值,根据当前长度最大的基准字组 在所述基准文件中确定当前对应时间; 根据当前对应时间加所述时间差值得到当前时间音频组词语文本的时间位置; 根据当前时间音频组词语文本的时间位置确定当前时间对应预测文本。 本公开第二方面提供一种音频识别装置,该装置包括如下模块: 音频信息获取模块,用于获取音频信息并输入到音频识别模型,得到在声学识别 过程中输出的音频对及所述音频对的开始时间和结束时间,及语言识别过程中得到的识别 文本; 基准文件筛选模块,用于将所述识别文本进行分词后,利用各分词在基准文件库 中匹配搜索,根据搜索结果筛选出多个基准文件; 第一粒度匹配模块,用于根据所述音频对在筛选出的多个基准文件中匹配搜索, 筛选出与任一音频对匹配的基准字组,并根据基准文件中的基准文本及所述音频对的开始 时间和结束时间,对筛选出的基准字组进行校准处理得到第一粒度的匹配结果; 第二粒度匹配模块,用于根据所述识别文本在筛选出的多个基准文件的文本中匹 配搜索,筛选出与所述识别文本匹配的基准文本,得到第二粒度的匹配结果; 匹配校准模块,用于利用第二粒度的匹配结果对第一粒度的匹配结果进行校准, 得到音频信息预测文本,其中所述第二粒度高于第一粒度。 基准文件筛选模块,利用各分词在基准文件库中匹配搜索,根据搜索结果筛选出 多个基准文件,包括: 对于各分词,查找基准文件库中出现该分词的基准文本; 根据所有分词的查找结果,利用基准文件中出现分词的个数和或次数对基准文件 进行筛选。 基准文件筛选模块,根据基准文件中出现分词的个数和/或各分词出现的次数进 行基准文件的筛选之后,还包括: 7 CN 111552777 A 说 明 书 5/23 页 根据分词在基准文本中的位置、顺序、是否连续来判断与原基准文件的相似度,进 一步筛选出相似度大于相似度阈值的多个基准文件。 无关文本筛选模块,利用各分词在基准文件库中匹配搜索之前,还包括: 过滤基准文件库中与识别文本无关的非基准文本。 第二粒度匹配模块,根据所述音频对在筛选出的多个基准文件中匹配搜索,筛选 出与任一音频对匹配的基准字组,并根据基准文件中的基准文本及所述音频对的开始时间 和结束时间,对筛选出的基准字组进行校准处理,包括: 将筛选出的各基准文件中的基准文本从前向后划分字组,筛选出与任一音频对匹 配的基准字组,所述字组的字数大于音频对个数; 根据所述音频对的开始时间和结束时间,标识与所述音频对匹配的基准字组的开 始时间和结束时间,并根据标识的基准字组的开始时间的先后顺序,对筛选出来的基准字 组进行排序; 将排序后的基准字组与划分的字组的顺序进行比较,确定出现乱序的基准字组并 删除。 第一粒度匹配模块,根据所述音频对的开始时间和结束时间,标识与所述音频对 匹配的基准字组的开始时间和结束时间,还包括: 确定基准字组仅与一个音频对匹配时,将所述音频对的开始时间标识为所述基准 字组的开始时间,将所述音频对的结束时间标识为所述基准字组的结束时间;或, 确定基准字组同时与至少两个音频对匹配时,将所述至少两个音频对的最早开始 时间,标识为所述基准字组的开始时间,将所述至少两个音频对的最晚结束时间,标识为所 述基准字组的结束时间。 第二粒度匹配模块,确定出现乱序的基准字组并删除之后,还包括: 确定开始时间相同的基准字组为重复使用的基准字组,从当前的基准字组中删除 重复使用的基准字组,及从划分的字组中删除重复使用的基准字组,并在划分的字组中保 留删除的基准字组的位置; 对当前划分的字组从后向前检测,检测到保留的位置可以容纳之后的字组时,将 之后的字组向前移动覆盖所述保留的位置至与最近的字组相邻; 确定当前划分的字组仍存在未被覆盖的保留的位置时,将未被覆盖的保留的位置 对应删除的基准字组,按照开始时间回填到当前基准字组中。 第一粒度匹配模块,确定出现乱序的基准字组并删除之后,包括: 通过比较当前基准字组与划分的字组,确定间隔的字组数超过预设个数的不连续 的基准字组; 确定所述不连续的基准字组之前和之后的连续基准字组,并将所述之后的连续基 准字组的第一个基准字组删除后向前移动覆盖n个基准字组位置,n为所述之后的连续基准 字组删除第一个基准字组后的基准字数的个数; 将删除的第一个基准字组,按照开始时间回填到当前基准字组中。 第一粒度匹配模块,确定出现乱序的基准字组并删除之后,包括: 通过比较当前基准字组与划分的字组,确定间隔的字组数超过预设个数的不连续 的基准字组; 8 CN 111552777 A 说 明 书 6/23 页 确定所述不连续的基准字组之前和之后的连续基准字组,并将所述之前的连续基 准字组的最后一个基准字组删除后向后移动覆盖n个基准字组位置,n为所述之前的连续基 准字组删除最后一个基准字组后的基准字数的个数; 将删除的最后一个基准字组,按照开始时间回填到当前基准字组中。 第一粒度匹配模块,确定出现乱序的基准字组并删除之后,包括如下至少一个步 骤: 根据当前基准字组的开始时间,过滤开始时间间隔大于设定时间第一阈值基准字 组; 根据当前基准字组的开始时间,过滤开始时间间隔小于设定时间第二阈值基准字 组,所述第一时间阈值大于所述第二时间阈值。 第一粒度匹配模块,确定出现乱序的基准字组并删除之后,包括如下至少一个步 骤: 确定当前任一基准字组的开始时间和结束时间大于设定值时,且占据两个基准文 本的首尾连接处时,删除该基准字组中占据其中一个基准文本的文字。 第一粒度匹配模块,确定出现乱序的基准字组并删除之后,包括: 利用当前基准字组中基准单字在基准文本中进行标注,根据在基准文本的整句文 本的标注结果,确定当前基准字组中冗余部分及与整句文本的匹配度小于设定阈值的部分 并进行过滤。 第一粒度匹配模块,根据在基准文本的整句文本的标注结果,确定当前基准字组 中冗余部分并进行过滤,包括: 确定基准文本中的整句文本被重复标注时,将重复标注整句文本的基准单字合并 处理;和/或 确定被标注的整句文本中,是否存在与多个连续被标注的整句文本之间的间隔超 过设定距离的整句文本时,若是,删除标注该整句文本的基准单字。 第一粒度匹配模块,根据在基准文本的整句文本的标注结果,确定当前基准字组 中与整句文本的匹配度小于设定阈值的部分并进行过滤,包括: 确定被标注的整句文本中,被基准单字标注的文字长度与整句文本的长度占比低 于设定比例值时,删除标注该整句文本的基准单字。 第一粒度匹配模块,根据所述识别文本在筛选出的多个基准文件的文本中匹配搜 索,筛选出与所述识别文本匹配的基准文本,得到第一粒度的匹配结果,包括: 确定所述识别文本中的整句识别文本,根据所述整句识别文本的多个音频对在多 个基准文件中匹配搜索,根据所述多个音频对与整句文本的匹配结果筛选出基准文本。 第二粒度匹配模块,利用第二粒度的匹配结果对第一粒度的匹配结果进行校准, 包括如下至少一个步骤: 将利用第二粒度的匹配结果对第一粒度的匹配结果进行对比,对所述第一粒度的 匹配结果的整句文本中缺少的文字进行填补; 将利用第二粒度的匹配结果对第一粒度的匹配结果进行对比,确定所述第二粒度 的匹配结果中不连续的整句文本,并对缺少的整句文本进行填补。 匹配校准模块,利用第二粒度的匹配结果对第一粒度的匹配结果进行校准,得到 9 CN 111552777 A 说 明 书 7/23 页 音频信息预测文本,包括: 利用当前第二粒度的匹配结果中的单字在第一粒度的匹配结果对应的基准文本 中进行标注,根据在基准文本的整句文本的标注结果,确定当前第一粒度的匹配结果中冗 余部分及与整句文本的匹配度小于设定阈值的部分并进行过滤。 匹配校准模块,根据在基准文本的整句文本的标注结果,确定当前基准字组中冗 余部分并进行过滤,包括: 确定基准文本中的整句文本被重复标注时,将重复标注整句文本的基准单字合并 处理;和/或 确定被标注的整句文本中,是否存在与多个连续被标注的整句文本之间的间隔超 过设定距离的整句文本时,若是,删除标注该整句文本的基准单字。 匹配校准模块,根据在基准文本的整句文本的标注结果,确定当前基准字组中与 整句文本的匹配度小于设定阈值的部分并进行过滤,包括: 确定被标注的整句文本中,被基准单字标注的文字长度与整句文本的长度占比低 于设定比例值时,删除标注该整句文本的基准单字。 当前时间预测文本确定模块,利用第二粒度的匹配结果对第一粒度的匹配结果进 行校准,得到音频信息预测文本,包括: 利用第二粒度的匹配结果对第一粒度的匹配结果进行校准后,确定当前长度最大 的基准字组对应的基准文件; 确定获取音频信息的时间与当前时间的时间差值,根据当前长度最大的基准字组 在所述基准文件中确定当前对应时间; 根据当前对应时间加所述时间差值得到当前时间音频组词语文本的时间位置; 根据当前时间音频组词语文本的时间位置确定当前时间对应预测文本。 本公开第三方面用于一种音频识别电子设备,所述电子设备包括:存储器和处理 器; 其中,所述存储器用于存储计算机程序; 所述处理器用于执行所述存储器中的程序,实现本公开第一方面提供的任一项方 法。 可选地,所述装置利用各分词在基准文件库中匹配搜索,根据搜索结果筛选出多 个基准文件,包括: 对于各分词,查找基准文件库中出现该分词的基准文本; 根据所有分词的查找结果,利用基准文件中出现分词的个数和或次数对基准文件 进行筛选。 对于筛选出的多个基准文件,根据分词在基准文本中的位置、顺序、是否连续来判 断与原基准文件的相似度,进一步筛选出相似度大于相似度阈值的多个基准文件。 可选地,所述装置利用各分词在基准文件库中匹配搜索之前,还包括: 过滤基准文件库中与识别文本无关的非基准文本。 可选地,所述装置根据所述音频对在筛选出的多个基准文件中进行匹配搜索,筛 选出与任一音频对匹配的基准字组,并根据基准文件中的基准文本及所述音频对的开始时 间和结束时间,对筛选出的基准字组进行校准处理,包括: 10 CN 111552777 A 说 明 书 8/23 页 将筛选出的各基准文件中的基准文本从前向后划分字组,筛选出与任一音频对匹 配的基准字组,所述字组的字数大于音频对个数; 根据所述音频对的开始时间和结束时间,标识与所述音频对匹配的基准字组的开 始时间和结束时间,并根据标识的基准字组的开始时间的先后顺序,对筛选出来的基准字 组进行排序; 将排序后的基准字组与划分的字组的顺序进行比较,确定出现乱序的基准字组并 删除。 可选地,所述装置根据所述音频对的开始时间和结束时间,标识与所述音频对匹 配的基准字组的开始时间和结束时间,包括: 确定基准字组仅与一个音频对匹配时,将所述音频对的开始时间标识为所述基准 字组的开始时间,将所述音频对的结束时间标识为所述基准字组的结束时间;或, 确定基准字组同时与至少两个音频对匹配时,将所述至少两个音频对的最早开始 时间,标识为所述基准字组的开始时间,将所述至少两个音频对的最晚结束时间,标识为所 述基准字组的结束时间。 可选地,所述装置确定出现乱序的基准字组并删除之后,包括: 确定开始时间相同的基准字组为重复使用的基准字组,从当前的基准字组中删除 重复使用的基准字组,及从划分的字组中删除重复使用的基准字组,并在划分的字组中保 留删除的基准字组的位置; 对当前划分的字组从后向前检测,检测到保留的位置可以容纳之后的字组时,将 之后的字组向前移动覆盖所述保留的位置至与最近的字组相邻; 确定当前划分的字组仍存在未被覆盖的保留的位置时,将未被覆盖的保留的位置 对应删除的基准字组,按照开始时间回填到当前基准字组中。 可选地,确定出现乱序的基准字组并删除之后,包括: 通过比较当前基准字组与划分的字组,确定间隔的字组数超过预设个数的不连续 的基准字组; 确定所述不连续的基准字组之前和之后的连续基准字组,并将所述之后的连续基 准字组的第一个基准字组删除后向前移动覆盖n个基准字组位置,n为所述之后的连续基准 字组删除第一个基准字组后的基准字数的个数; 将删除的第一个基准字组,按照开始时间回填到当前基准字组中。 可选地,确定出现乱序的基准字组并删除之后,包括: 通过比较当前基准字组与划分的字组,确定间隔的字组数超过预设个数的不连续 的基准字组; 确定所述不连续的基准字组之前和之后的连续基准字组,并将所述之前的连续基 准字组的最后一个基准字组删除后向后移动覆盖n个基准字组位置,n为所述之前的连续基 准字组删除最后一个基准字组后的基准字数的个数; 将删除的最后一个基准字组,按照开始时间回填到当前基准字组中。 可选地,所述装置确定出现乱序的基准字组并删除之后,包括如下至少一个步骤: 根据当前基准字组的开始时间,过滤开始时间间隔大于设定时间第一阈值的基准 字组; 11 CN 111552777 A 说 明 书 9/23 页 根据当前基准字组的开始时间,过滤开始时间间隔小于设定时间第二阈值的基准 字组,所述第一时间阈值大于所述第二时间阈值。 可选地,所述装置确定出现乱序的基准字组并删除之后,包括如下至少一个步骤: 确定当前任一基准字组的开始时间和结束时间大于设定值时,且占据两个基准文 本的首尾连接处时,删除该基准字组中占据其中一个基准文本的文字。 可选地,所述装置确定出现乱序的基准字组并删除之后,包括: 利用当前基准字组中基准单字在基准文本中进行标注,根据在基准文本的整句文 本的标注结果,确定当前基准字组中冗余部分及与整句文本的匹配度小于设定阈值的部分 并进行过滤。 可选地,所述装置根据在基准文本的整句文本的标注结果,确定当前基准字组中 冗余部分并进行过滤,包括: 确定基准文本中的整句文本被重复标注时,将重复标注整句文本的基准单字合并 处理;和/或 确定被标注的整句文本中,是否存在与多个连续被标注的整句文本之间的间隔超 过设定距离的整句文本时,若是,删除标注该整句文本的基准单字。 可选地,所述装置根据在基准文本的整句文本的标注结果,确定当前基准字组中 与整句文本的匹配度小于设定阈值的部分并进行过滤,包括: 确定被标注的整句文本中,被基准单字标注的文字长度与整句文本的长度占比低 于设定比例值时,删除标注该整句文本的基准单字。 可选地,所述装置根据所述识别文本在筛选出的多个基准文件的文本中匹配搜 索,筛选出与所述识别文本匹配的基准文本,得到第一粒度的匹配结果,包括: 确定所述识别文本中的整句识别文本,根据所述整句识别文本的多个音频对在多 个基准文件中进行匹配搜索,根据所述多个音频对与整句文本的匹配结果筛选出基准文 本。 可选地,所述装置利用第二粒度的匹配结果对第一粒度的匹配结果进行校准,包 括如下至少一个步骤: 将利用第二粒度的匹配结果对第一粒度的匹配结果进行对比,对所述第一粒度的 匹配结果的整句文本中缺少的文字进行填补; 将利用第二粒度的匹配结果对第一粒度的匹配结果进行对比,确定所述第一粒度 的匹配结果中不连续的整句文本,并对缺少的整句文本进行填补。 可选地,所述装置利用第二粒度的匹配结果对第一粒度的匹配结果进行校准,得 到音频信息预测文本,包括: 利用当前第二粒度的匹配结果中的单字在第一粒度的匹配结果对应的基准文本 中进行标注,根据在基准文本的整句文本的标注结果,确定当前第一粒度的匹配结果中冗 余部分及与整句文本的匹配度小于设定阈值的部分并进行过滤。 可选地,所述装置根据在基准文本的整句文本的标注结果,确定当前基准字组中 冗余部分并进行过滤,包括: 确定基准文本中的整句文本被重复标注时,将重复标注整句文本的基准单字合并 处理;和/或 12 CN 111552777 A 说 明 书 10/23 页 确定被标注的整句文本中,是否存在与多个连续被标注的整句文本之间的间隔超 过设定距离的整句文本时,若是,删除标注该整句文本的基准单字。 可选地,所述装置根据在基准文本的整句文本的标注结果,确定当前基准字组中 与整句文本的匹配度小于设定阈值的部分并进行过滤,包括: 确定被标注的整句文本中,被基准单字标注的文字长度与整句文本的长度占比低 于设定比例值时,删除标注该整句文本的基准单字。 可选地,所述装置利用第二粒度的匹配结果对第一粒度的匹配结果进行校准,得 到音频信息预测文本,包括: 利用第二粒度的匹配结果对第一粒度的匹配结果进行校准后,确定当前长度最大 的基准字组对应的基准文件; 确定获取音频信息的时间与当前时间的时间差值,根据当前长度最大的基准字组 在所述基准文件中确定当前对应时间; 根据当前对应时间加所述时间差值得到当前时间音频组词语文本的时间位置; 根据当前时间音频组词语文本的时间位置确定当前时间对应预测文本。 本公开第四方面用于一种计算机存储介质,其上存储有计算机程序,该程序被处 理器执行时实现如本公开第一方面提供的任一项方法。 利用本公开提供的一种音频识别方法、装置、电子设备及存储介质,能利用识别文 本、音频对以及歌曲库为基础,对原有的文字识别结果进行修正,大大提高了歌曲识别的准 确性。 附图说明 图1为一种音频识别方法的步骤示意图; 图2为一种音频识别方法的完整步骤示意图; 图3为一种音频识别装置的模块示意图; 图4为一种音频识别电子设备的具体示意图。











