
技术摘要:
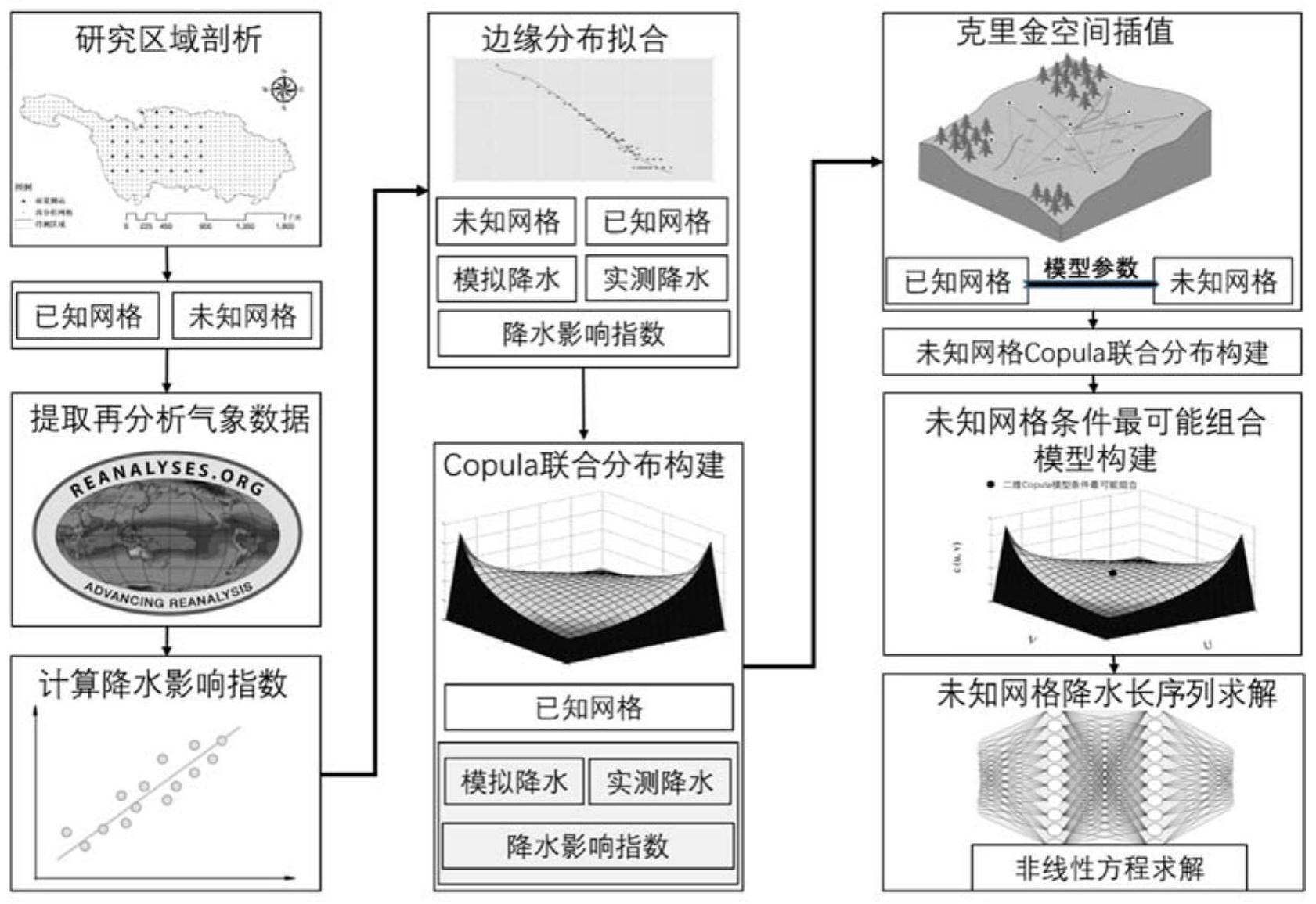
本发明公开了一种基于Copula函数的无资料地区降水数据推求方法及系统,属于降水预测领域,基于最新再分析气象资料,充分考虑各气象要素对降水的影响,结合有资料地区实测降水数据,采用主成分分析法获取降水影响指数,通过Copula函数构建降水影响指数、模拟降水与实测 全部
背景技术:
降水是陆地水资源的直接来源和水文循环的首要环节,降水数据是区域水资源和 水环境的首要基础资料之一,对流域水资源综合规划利用、防洪抗旱以及水环境和水生态 系统保护均具有重要意义。由于降水观测手段的局限性,偏远地区往往因缺乏降水基础信 息而严重制约了当地水资源开发利用与生态环境维护,如何推求无资料地区的降水数据是 当前研究的热点与难点。 概括而言,当前降水资料的获取主要包含三种途径:气象雷达、卫星遥感以及地面 雨量测站。气象雷达测量费用高昂,难以推广;卫星遥感技术存在时空分辨率低的问题,通 常无法满足实际需求;地面雨量测站作为唯一直接观测降水的方法,精度最高,是主流的降 水信息获取来源。但雨量测站分布密度有限且分布不均。针对无测站资料地区的降水研究, 有学者提出利用大气再分析资料(数值天气模式和资料同化方法重建气象资料)补充无资 料地区的降水信息。相较于气象雷达或卫星遥感数据,再分析资料具有空间覆盖全面、时间 尺度长、具有动力和物理意义且时空分辨率高的优势。新一代的再分析资料水平分辨率高 达31km,提供逐小时的基本天气要素资料。但受限于观测资料的时空不确定性、数值预报模 式误差以及同化方法造成的系统偏差,再分析资料仍旧无法直接应用于工程实际,需要进 行预处理。例如,何奇芳等“ERA-interim再分析数据集在长江上游的适用性[J].人民长江, 2018,49(12):30-33”评估了ERA-interim再分析数据在长江上游的适用性,发现尽管ERA降 水数据与流域内雨量测站数据的变化趋势一致,但两者的数值存在一定差异;通过校正处 理后的ERA数据可以较好的代表流域内实测站点降水信息。 但该研究仅考虑了单一再分析资料在流域上的适用性。不同的再分析数据产品采 用的基础数据不同,基础模式动力框架与物理过程描述以及同化均存在差异,在描述降水 过程上各具特点。为了获取更加准确真实的降水信息,需要融合较好捕获降水时空分布的 再分析数据,综合考虑不同产品的误差及优势。目前常见的数据融合方法包括简单的算术 平均、去除最大偏差以及贝叶斯模型加权平均等。然而算数平均法认为各产品描述降水的 能力相同,与实际情况不符;去除最大偏差法将最大偏差的产品去除后,对剩余数据平均, 一定程度上考虑了各再分析数据的性能,但之后的平均过程仍然会导致出现算数平均方法 的问题。贝叶斯模型加权平均假设各序列服从正态分布,若序列具有非正态特征,则需要通 过正态转换处理,这一定程度上局限了模型的精度与准确性。现有研究未能充分利用各再 分析气象信息,无法解决无资料地区的降水信息描述的难题。
技术实现要素:
针对现有技术的以上缺陷或改进需求,本发明提出了一种基于Copula函数的无资 5 CN 111611541 A 说 明 书 2/10 页 料地区降水数据推求方法及系统,由此解决现有研究未能充分利用各再分析气象信息,无 法解决无资料地区的降水信息描述的技术问题。 为实现上述目的,按照本发明的一个方面,提供了一种基于Copula函数的无资料 地区降水数据推求方法,包括: (1)将待测区域划分为已知网格和未知网格,并收集所述待测区域的再分析资料 中气象要素长序列以及雨量测站降水长序列,其中,所述已知网格中包含地面雨量测站; (2)通过相关性分析法筛选所述再分析资料中与所述已知网格中通过所述地面雨 量测站获取的实测降水序列相关性满足预设相关性系数要求的气象要素,通过主成分分析 法对筛选出的气象要素进行降维处理,获取降水影响指数; (3)分别拟合所述已知网格的实测降水序列、所述已知网格再分析资料中的模拟 降水以及所述降水影响指数的边缘分布函数,并估计各所述边缘分布函数的参数; (4)根据各所述边缘分布,基于高维Copula函数构造所述已知网格再分析资料中 模拟降水、实测降水及所述降水影响指数的联合分布模型,并估计所述联合分布模型的参 数; (5)通过克里金空间插值方法将已知网格中各所述边缘分布函数的参数以及所述 联合分布模型的参数插值到所述未知网格,针对所述未知网格再次构建联合分布模型; (6)基于条件概率密度最大原则,构建所述未知网格再分析资料中模拟降水与所 述未知网格的实测降水信息的条件最可能组合,将所述未知网格再分析资料中的气象要素 输入再次构建的联合分布模型,推导所述未知网格的实测降水信息。 优选地,步骤(1)包括: (1.1)确定待测区域,获取所述待测区域内雨量测站降水资料长序列,并根据雨量 测站位置与分布密度确定网格大小,以将所述待测区域划分为已知网格和未知网格; (1.2)收集所述待测区域内多套再分析资料,其中,所述再分析资料中的气象要素 除降水外,还包含与降水紧密相关的气温、相对湿度、日照时长及风速变量。 优选地,步骤(2)包括: (2.1)分别将各所述已知网格再分析资料中除降水以外的其他气象要素与通过地 面雨量测站获取的实测降水进行相关性分析,综合各已知网格情况筛选相关性系数满足预 设相关性系数要求的气象要素; (2.2)针对所述待测区域中的所有网格,基于主成分分析法将筛选的气象要素进 行降维处理,得到因子荷载绝对值最大的气象要素指数,作为降水影响指数。 优选地,步骤(3)包括: 令PM表示所述已知网格的实测降水序列,PF表示所述降水影响指数,Si(i=1 , 2,…n)表示所述已知网格对应的不同再分析资料中的模拟降水,n表示所述已知网格对应 的再分析资料的数量,采用伽马分布函数分别构建已知网格实测降水的边缘分布FPM(pm)、 降水影响指数的边缘分布FPF(pf)及不同再分析资料中的模拟降水的边缘分布FSi(si),并采 用线性矩法估计各边缘分布函数的参数,其中,FPM(pm)的密度函数为fPM(pm),FPF(pf)的密 度函数为fPF(pf),FSi(si)的密度函数为fSi(si)。 优选地,步骤(4)包括: 针对所述已知网格,基于各变量的边缘分布函数,采用Archimedean Copula函数 6 CN 111611541 A 说 明 书 3/10 页 族中的Gumbel-Hougaard Copula作为联合分布函数,构造所述已知网格再分析资料中模拟 降水、实测降水及所述降水影响指数的联合分布模型,并估算所述联合分布模型的参数。 优选地,所述联合分布模型为: 其中,C (θ)为n 2维的Copula函数,θ为Copula函数的参数。 优选地,步骤(5)包括: (5.1)利用拉格朗日乘数法进行求解克里金空间插值法中的插值权重系数λi,其 中,克里金空间插值表示为 未知点的位置 为x0,已知参数点的位置为xi,m是已知网格的个数,γ(h)为插值拟合的变异函数,γ(xi- xj)为xi和xj之间的变异函数值,该式可以通过拉格朗日乘数法进行求解,μ表示拟合残差; (5.2)根据所述已知网格中各所述边缘分布函数的参数、所述联合分布模型的参 数以及求取的权重系数λi,由 计算所述未知网格的模型参数,其中,Z* (x0)是未知点x0的基于克里金法插值的参数估计结果,Z(xi)是已知位置xi的参数值,包括 已知网格边缘分布函数以及联合分布函数的参数; (5.3)根据在未知点插值的参数,在所述未知网格上逐一构建未知网格的实测降 水、未知网格再分析资料中模拟降水及降水影响指数的Copula联合概率分布模型。 优选地,步骤(6)包括: (6 .1)针对所述未知网格,借助Copula函数将再构建的联合分布函数F(pm ,pf , s1,...,sn)表示为:F(pm,pf,s1,...,sn)=C(u,v1,v2,...vn 1),其中,u为未知网格实测降水 的边缘分布函数u=FPM(pm),v1为降水影响指数PF的边缘分布函数v1=FPF(pf),v2,...vn 1 为未知网格各再分析模拟降水的边缘分布函数 C(u ,v1 , v2,...,vn 1)表示Copula模型; (6.2)基于Copula联合分布函数条件概率密度最大原则,构建未知网格模拟降水、 降水影响指数以及未知网格实测降水信息的条件最可能组合,其中,联合分布函数的条件 概率分布函数 为: 条件概率分布函数 的密度函数 为 : 7 CN 111611541 A 说 明 书 4/10 页 其中, 为Copula函数的密度 函数,c(pf,s2,...sn)表示除去待测实测降水以外,其余已知变量的密度函数; 当 取最大值时对应的组合(pm,pf ,s1,...sn)即条件最可能组 合; (6 .3)由 获得条件最可能组合的非线 性方程,其中, cn=c(u,v1 ,v2,...,vn),cn 1=c(u,v1 ,v2,...,vn 1),c、c (u,v1,v2,...,vn)、c(u,v1,v2,...,vn 1)均为Copula函数的密度函数,fPM(pm)为密度函数, fP'M(pm)为密度函数fPM(pm)的导数; (6.4)采用牛顿迭代法求解所述非线性方程的近似解,获得实际降水和各预报变 量值的条件最可能组合(pm,pf,s2,…,sn); (6.5)重复步骤(6.1)~步骤(6.4),逐点逐时段分别计算未知网格降水长序列。 按照本发明的另一个方面,提供了一种基于Copula函数的无资料地区降水数据推 求系统,包括: 网格划分与数据采样模块,用于将待测区域划分为已知网格和未知网格,并收集 所述待测区域的再分析资料中气象要素长序列以及雨量测站降水长序列,其中,所述已知 网格中包含地面雨量测站; 降水影响指数获取模块,用于通过相关性分析法筛选所述再分析资料中与所述已 知网格中通过所述地面雨量测站获取的实测降水序列相关性满足预设相关性系数要求的 气象要素,通过主成分分析法对筛选出的气象要素进行降维处理,获取降水影响指数; 第一参数估计模块,用于分别拟合所述已知网格的实测降水序列、所述已知网格 再分析资料中的模拟降水以及所述降水影响指数的边缘分布函数,并估计各所述边缘分布 函数的参数; 第二参数估计模块,用于根据各所述边缘分布,基于高维Copula函数构造所述已 知网格再分析资料中模拟降水、实测降水及所述降水影响指数的联合分布模型,并估计所 述联合分布模型的参数; 联合模型构建模块,用于通过克里金空间插值方法将已知网格中各所述边缘分布 函数的参数以及所述联合分布模型的参数插值到所述未知网格,针对所述未知网格再次构 建联合分布模型; 推求模块,用于基于条件概率密度最大原则,构建所述未知网格再分析资料中模 拟降水与所述未知网格的实测降水信息的条件最可能组合,将所述未知网格再分析资料中 的气象要素输入再次构建的联合分布模型,推导所述未知网格的实测降水信息。 按照本发明的另一方面,提供了一种计算机可读存储介质,其上存储有程序指令, 8 CN 111611541 A 说 明 书 5/10 页 所述程序指令被处理器执行时实现如上述任一所述的基于Copula函数的无资料地区降水 数据推求方法。 总体而言,通过本发明所构思的以上技术方案与现有技术相比,能够取得下列有 益效果: 1、科学合理、贴近工程实际: 本发明利用Copula函数建立再分析资料中降水影响因素、模拟降水与实测降水的 联合分布模型,推导得到条件最可能组合情景下的降水影响指数、模拟降水和实测降水,具 有较强的统计基础,能够客观反映实测降水的特征。 2、可为无资料地区降水信息提供重要且可操作性强的参考依据: 充分考虑再分析数据的优势,以及气象要素对降水的综合影响,利用已知网格的 降水资料,通过克里金插值方法将Copula联合分布模型参数外延至无资料地区(未知网 格),再利用无资料地区的再分析数据推求实测降水长序列,为无资料地区的降水信息获取 提供参考依据。 附图说明 图1是本发明实施例提供的一种区域划分示意图; 图2是本发明实施例提供的一种方法流程示意图; 图3是本发明实施例提供的一种二维Copula条件最可能组合示意图; 图4是本发明实施例提供的一种系统结构示意图。











