
技术摘要:
一种基于语义结构的口令分词系统及方法,包括:预处理模块、NLP语义提取模块和non‑NLP语义标注模块,其中:预处理模块接收待分词口令,提取口令中无法在之后的步骤中被识别的特殊语义因子并将其余部分按照字符类型进行预分词,将字母部分输出至NLP语义提取模块,将非 全部
背景技术:
由于文本密码具有很好的安全性和可用性,文本密码目前仍然广泛应用在计算机 系统的用户认证和在线服务中。由于大多数用户使用的口令是由用户自己定义的,为了方 便记忆,用户往往选择若干含有特定语义或规律的字符串作为口令,因此对于口令语义结 构的研究对于提高用户密码安全性具有重要意义。 与自然语言不同的是,口令没有固定的语法结构,用户在设定口令时可以根据网 站的规则对各种语义因子进行任意组合,因此针对自然语言的分词方法并不适用于口令分 词。 过去大多数口令语义结构的研究都是针对英文用户口令,由于英文用户和中文用 户设定的口令存在一定的差异,针对英文用户口令提出的分词方法往往在中文泄露库上表 现不佳。近年来若干研究者开始对中文用户口令进行研究,研究表明在分词系统中添加额 外的语义信息是有效的,但是添加什么信息、如何添加信息仍然是一种主观判断,没有一种 系统化的方法。
技术实现要素:
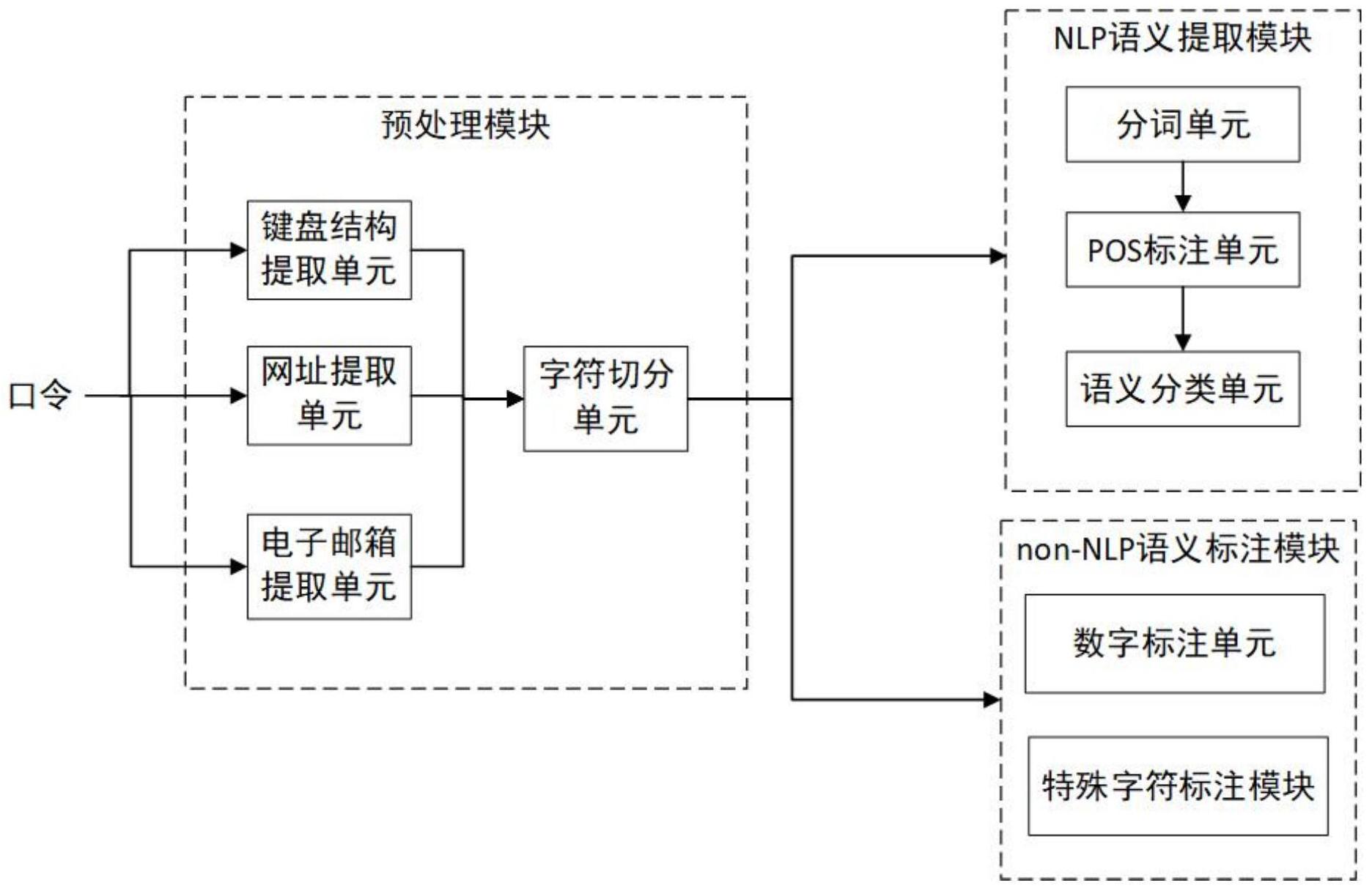
本发明针对现有技术存在的上述不足,提出一种基于语义结构的口令分词系统及 方法,根据语料库对口令按照其中蕴含的语义信息进行分词,识别口令的语义结构,对中文 用户和英文用户设定的口令都能进行准确的分词。 本发明是通过以下技术方案实现的: 本发明涉及一种基于语义结构的口令分词系统,包括:预处理模块、自然语言处理 (NLP)语义提取模块和非自然语言处理(non-NLP)语义标注模块,其中:预处理模块接收待 分词口令,提取口令中无法在之后的步骤中被识别的特殊语义因子并将其余部分按照字符 类型进行预分词,将字母部分输出至NLP语义提取模块,将非字母部分输出至non-NLP语义 标注模块;NLP语义提取模块利用NLP工具从对口令的字母部分进行分词,得到多种语义因 子;non-NLP语义标注模块对口令中无法用NLP工具进行分词的部分进行语义标注。 所述的特殊语义因子包括:键盘结构、网址、电子邮箱。 所述的无法用NLP工具进行分词的部分包括:数字、特殊字符。 所述的预处理模块包括:键盘结构提取单元、电子邮箱提取单元、网址提取单元和 字符切分单元,其中:键盘结构提取单元提取口令中与键盘按键分布规律有关的部分,即提 取口令中的键盘结构,电子邮箱提取单元提取口令中含有的电子邮箱地址,网址提取单元 提取口令中含有的网址,字符切分单元将口令按照字符类型不同进行分词。 所述的NLP语义提取模块包括:分词单元、词性标注(POS)单元和语义分类单元,其 4 CN 111553155 A 说 明 书 2/4 页 中:分词单元利用自然语言工具包(NLTK)对从预处理模块输入的字母部分进行分词,将结 果输出至POS单元;POS单元利用NLTK的POS模块对输入的各因子进行标注,将需要进一步分 类的语义因子输出至语义分类单元;语义分类单元利用字符串匹配的方法对命名实体因子 进一步分类,标注为地名、月份、男性名字、女性名字、中文姓名缩写类别,将未识别因子在 拼音列表中进行匹配,将匹配到的因子标注为拼音,未匹配到的因子当符合“长度超过3位 的辅音字母”这一规则就标注为缩写,否则仍然标注为未识别因子。 所述的需要进一步分类的语义因子包括:命名实体、未识别片段。 所述的non-NLP语义标注模块包括:数字标注模块和特殊字符标注模块,其中:数 字标注模块将含特定语义的数字片段进行相应的标注,对未知语义的数字片段按其长度进 行标注;特殊字符标注单元对特殊字符片段按其长度进行标注。 所述的特定语义包括:日期,年份、手机号。 技术效果 本发明解决了对不同语种、不同泄露库的口令进行分词的问题; 与现有技术相比,本发明通过在对口令进行正式分词之前,预先从键盘结构、电子 邮箱、网址等包含多种字符类型的语义因子中提取口令,避免了按字符类型分词之后造成 的语义丢失,提高了分词的准确率,可以有效地提取出口令中蕴含的键盘结构,提高了分词 的准确性;本发明在分词系统中添加地名、中文姓名缩写、拼音、缩写、手机号、键盘结构、网 址、电子邮箱等多种语义因子,提高了分词的准确率,同时实现了本发明对中文网站口令的 分词。 附图说明 图1为本发明系统结构示意图。











