
技术摘要:
本发明属于自然语言处理技术领域,具体提供一种基于损失优化的实体关系联合抽取方法,该方法针对实体和非实体的数目不平衡、实体标注存在噪声两个问题,对传统方法的损失计算部分进行优化;一方面,在损失函数中引入敏感因子,忽略训练中已经学习良好的成分,从而降低 全部
背景技术:
当前,由大数据驱动的智能化浪潮给金融业的发展带来了新的创新机遇,金融领 域每天都会产生大量不同形式的互联网文本数据;如何准确、高效地挖掘这些金融文本中 的重要信息,以提升金融服务效率是金融智能化面临的一个关键问题。在金融信息挖掘中, 实体关系抽取是核心任务,其目标是从文本数据中识别出金融实体,并判断出实体间存在 的语义关系。 根据抽取流程的不同,实体关系抽取方法可分为管道式方法和联合式方法两类。 管道式方法将实体关系抽取任务划分为实体识别和关系抽取两个独立的子任务,对于一段 输入文本,它先用实体识别模型识别文本中出现的有效实体,然后再用关系模型判断实体 间的语义关系;管道式方法简单,但是存在错误传播问题,即实体模型造成的错误会直接影 响下游的关系抽取的效果;另外,管道式建模方式也忽略了实体识别和关系抽取两个子任 务之间的依赖关系。相比之下,联合式抽取方法对实体识别和关系抽取进行统一建模,从而 克服了管道式方法的缺点。 然而由于一些客观因素的存在,现有联合式抽取方法在提高识别精度方面面临困 难;一方面,由于一个句子的实体数目通常远少于非实体数目,即实体和非实体的数目客观 上存在不平衡的现象,而传统方法将实体与非实体等同对待,往往导致训练的模型倾向于 “关注”不重要的非实体类样本,忽略重要的实体类样本,给实体的识别精度带来负面的影 响;另一方面,人工标注数据可能会引入噪声,比如部分实体被人工错误地标注为非实体, 标注噪声导致模型训练错误,识别精度下降。
技术实现要素:
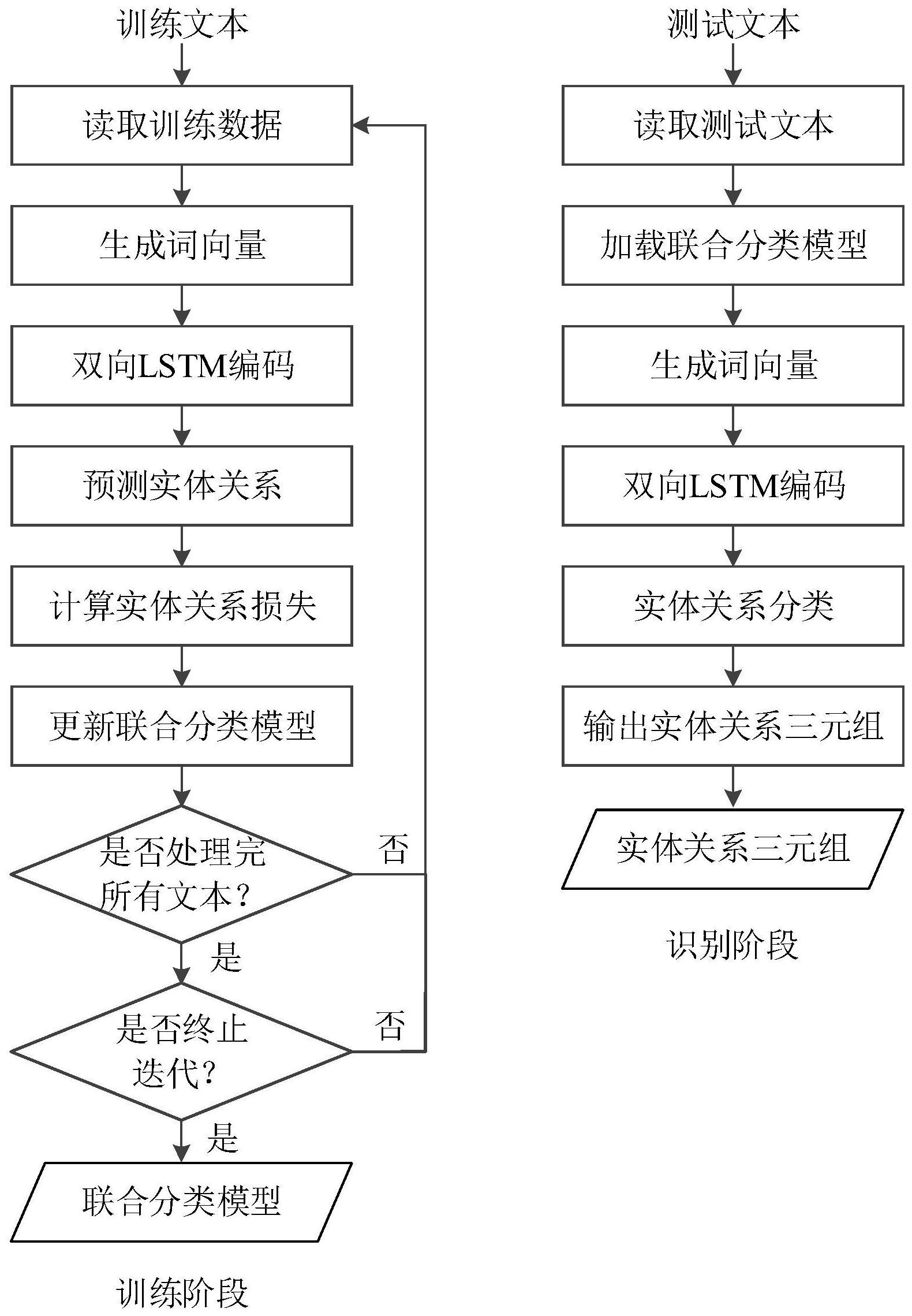
本发明的目的在于针对上述现有技术的不足,提供了一种基于损失优化的实体关 系联合抽取方法,采用新的损失函数计算方法,有效地提升了实体关系的识别精度。 为了达到上述目的,本发明采用的技术方案为: 一种基于损失优化的实体关系联合抽取方法,包括以下步骤: 步骤1、数据预处理; 步骤1.1、读取实体标签数据: 步骤1.1.1、对文本T,从标签文件中读取分词信息,将T分割成不同的词ti(1≤i≤ Nw),Nw为文本T中词的总个数,其中标点符号视为一个词; 步骤1.1.2、对文本T中的每一个词ti,从标签文件中读取实体类型信息,生成ti的 实体类型编号li:若ti被标注为某实体、则令li为该实体的实体类别编号,否则、令li=Ne 1, Ne为实体类型的总数; 4 CN 111581387 A 说 明 书 2/10 页 步骤1.1.3、对文本T中的每一个词ti,将其实体类型编号li进行独热(one-hot)编 码,得到实体标签向量yi; 步骤1.2、读取关系标签数据: 步骤1.2.1、将文本T中的任意两个不同的词ti和tj(1≤i,j≤Nw ,i≠j)组成词对 (ti,tj),从标签文件中读取词对(ti,tj)的关系类型信息,生成词对(ti,tj)所对应的关系类 型编号mi,j:若词对(ti,tj)被标注为某关系、则令mi,j为该关系的关系类别编号,否则、令mi,j =Nr 1,Nr为关系类别总数; 步骤1.2.2、对每一个词对(ti,tj)(1≤i,j≤Nw,i≠j),将其关系类型编号mi,j进行 独热编码,得到关系标签向量zi,j; 步骤2、构建及训练联合分类模型; 步骤2.1、构建联合分类模型,包括:输入层、隐藏层及输出层; 所述输入层采用word2vec词嵌入结构、并设置其输出矢量的维数为dw;将文本T中 的每一个词ti(1≤i≤Nw)输入到输入层进行词嵌入,得到维数为dw的词向量wi; 所述隐藏层采用双向LSTM结构、并设置其输出矢量的维数为dc;其中,前向LSTM编 码:将每一个词ti所对应的词向量wi输入到隐藏层进行前向LSTM编码得到维数为dc的前向 编码向量 后向LSTM编码:将每一个词ti所对应的词向量wi输入到隐藏层进行后向LSTM编 码得到维数为dc的后向编码向量 将每一个词ti所对应的前向编码向量 和后向编码向 量 进行拼接,得到维数为2×dc双向编码向量hi: 所述输出层采用softmax与sigmoid分类器的联合结构;其中: 所述softmax分类器进行实体类型预测,将每一个双向编码向量hi(1≤i≤Nw)输入 到softmax分类器,得到维数为Ne 1的实体类型预测向量 该向量的第q个元素对应于将 词ti的实体类型预测为第q种实体类型的概率; 所述sigmoid分类器进行关系类型预测,将每一个词对(ti,tj)中ti和tj所对应的 双向编码向量hi和hj输入到sigmoid分类器,得到维数为Nr 1的关系类型预测向量 该向 量的第k个元素对应于将词对(ti,tj)的关系类型预测为第k种关系类型的概率; 步骤2.2、训练联合分类模型:设置训练集的文本总条数为Ntrain、训练总迭代次数 为Nt以及损失函数,采用反向传播算法对联合分类模型参数进行更新,训练结束得到联合 分类模型; 所述损失函数为: 其中, 为实体损失: δi为词ti的敏感因子: 5 CN 111581387 A 说 明 书 3/10 页 为实体标签向量yi的第li(1≤li≤Ne 1)个元素、表示ti属于第li种实体类型的 概率, 为实体类型预测向量 的第li个元素、表示ti被预测为第li种实体类型的概率,λ 为预设敏感阈值,sgn(·)为符号函数: βi为词ti(1≤i≤Nw)的衰减因子: NO表示文本T中非实体类型的词的个数; 为关系损失: 步骤3、实体关系联合抽取; 步骤3.1、采用中文分词工具对待处理文本T'进行分词处理,将T'分割成不同的词 t'i '(1≤i'≤N'w)、N'w为T'中词的总个数,并形成词对(t'i ',t 'j ')(1≤i',j'≤N'w ,i '≠ j'),输入至训练得到的联合分类模型,得到每一个词t'i'的实体类型预测向量 以及词对 (t'i ',t'j')的关系类型预测向量 其中,实体类型预测向量 中最大值对应的位置编 号作为词t'i '的实体类型预测编号 关系类型预测向量 中最大值所对应的位置编号 作为词对(t'i',t'j')的关系类型预测编号 步骤3.2、输出实体关系三元组:对每个词对(t'i',t'j')(1≤i',j'≤N'w,i'≠j') 进行判断:若该词对对应的实体类型预测编号 和 均不等于Ne 1,且其关系类型预测编号 不等于Nr 1,则形成实体关系三元组(t'i ',Ri ',j',t'j')并输出,其中,Ri ',j'为关系类型 预测编号 所对应的关系名称。 进一步的,所述敏感阈值λ的取值范围:0.7≤λ≤0.9。 本发明的有益效果在于: 本发明提供一种基于损失优化的实体关系联合抽取方法,该方法针对实体和非实 体的数目不平衡、实体标注存在噪声两个问题,对传统方法的损失计算部分进行优化;一方 面,在损失函数中引入敏感因子,忽略训练中已经学习良好的成分,从而降低非实体损失在 总体损失中的比例,让模型更加“关注”实体类的损失,以缓解实体和非实体数目不平衡问 题,提高了实体识别的精度;另一方面,在损失函数中引入衰减因子,按非实体数目所占实 6 CN 111581387 A 说 明 书 4/10 页 体和非实体总数目的比例对损失函数中的非实体成分损失进行衰减,从而降低了由于标注 噪声带来的损失计算误差,进一步提高了实体关系总体识别精度。 附图说明: 图1为本发明基于损失优化的实体关系联合抽取方法的流程示意图,包含训练和 识别两个阶段。











