
技术摘要:
本发明涉及一种基于Mask机制和层次注意力机制的推荐方法,包括:获取节点数据集U和项目数据集I;将U和I输入上下文描述层得到序列Su和Si,经过处理得到节点向量和项目向量和融合后得到第i个节点u在I中的嵌入向量将所有节点的嵌入向量组成向量集Z;计算与第i个节点u关系 全部
背景技术:
随着人们日常生活节奏的加快,以实用的方式快速获取有用的信息可以节省大量 的时间,推荐系统在信息过滤中起着至关重要的作用。数据稀疏性、冷启动和推理问题一直 是影响推荐质量的三大问题,协同过滤推是主流的传统推荐算法,但是由于数据的稀疏性, 严重影响了推荐质量。基于神经网络的协同过滤推荐方法(如CNN,RNN等)缓解了数据稀疏 性的问题。此外,基于社交网络的方法可以有效的为新用户,新物品和新商店提供推荐,在 冷启动问题上有很大的改善。 在社交网络中,大多数用户之间存在着显性或隐性的关系,这些关系影响着彼此 的行为,社交媒体的广泛存在极大地丰富了网络用户的社交活动,产生了丰富的社会关系, 融合这些社会关系提高了推荐系统的质量。近年来,研究者们提出了大量基于社交网络的 推荐系统,一些社交推荐系统将社交关系同质化。然而,由于用户在两个领域的行为和交互 方式不同,它可能会限制用户在各个领域的表示学习。在一些研究中学习了在两个域中分 离的用户表示,然后将信息从社交域转移到项目域以提供推荐。这些研究考虑了两个领域 的异构性,但由于两个领域固有的数据稀疏性问题,对表示形式的学习具有挑战性。更多的 推荐系统考虑了在线社交网络中的连接本质上是异构的问题,将社交网络分为用户域和项 目域两个部分,但是对于两个领域的特征学习并不丰富。 基于深度学习的最新进展,特别是图卷积网络(GCN)的发展,能够很容易的聚合社 交网络中的特征信息,基于图卷积神经网络的推荐系统在推荐质量上超过了以前的推荐算 法。然而图卷积为同阶邻节点分配相同的权重,且聚合特征时依赖于整个图,局限了图的灵 活性和泛化能力。在此基础上,提出了图注意力网络,图注意力网络用注意力机制对邻近节 点特征加权求和,邻居节点的特征权重与节点本身相关,各不相同。然而不论是图卷积神经 网络还是图注意力网络,社交网络中的节点都在同一个域中进行聚合,在网络规模较大时, 训练时间都较长。
技术实现要素:
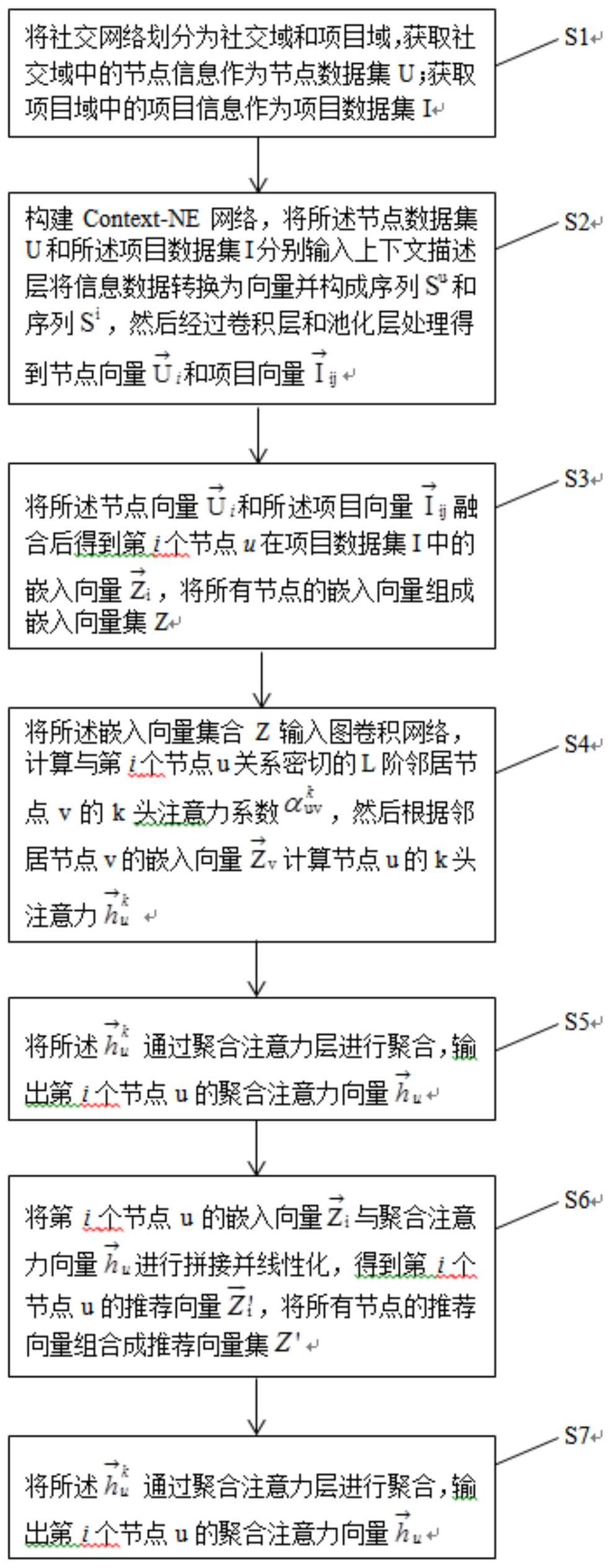
本发明为了解决现有技术的不足,提出了一种基于Mask机制和层次注意力机制的 推荐方法,结合社交网络信息和用户的行为信息,不仅提高了推荐准确度,还提高了网络的 灵活性,解决用户冷启动和冷启动问题,并且模型也更为简单,进行推荐时所耗时间也更 少。 本发明为解决技术问题采用如下技术方案: 一种基于Mask机制和层次注意力机制的推荐方法,包括以下步骤: 步骤S1.将社交网络划分为社交域和项目域,获取社交域中的节点信息作为节点 5 CN 111582443 A 说 明 书 2/14 页 数据集U;获取项目域中的项目信息作为项目数据集I; 步骤S2.构建Context-NE网络,将所述节点数据集U和所述项目数据集I分别输入 上下文描述层将信息数据转换为向量并构成序列Su和序列Si,然后经过卷积层和池化层处 理得到节点向量 和项目向量 步骤S3.将所述节点向量 和所述项目向量 融合后得到第i个节点u在项目数 据集I中的嵌入向量 将所有节点的嵌入向量组合成向量集Z; 步骤S4.将所述向量集合Z输入图卷积网络,计算与第i个节点u关系密切的L阶邻 居节点v的k头注意力系数 然后根据邻居节点v的嵌入向量 计算节点u的k头注意力 步骤S5.将所述 通过聚合注意力层进行聚合,输出第i个节点u的聚合注意力向 量 步骤S6.将第i个节点u的嵌入向量 与聚合注意力向量 进行拼接并线性化,得 到第i个节点u的推荐向量 将所有节点的推荐向量组合成推荐向量集Z'; 步骤S7.根据所述嵌入向量集Z和/或所述推荐向量集Z'获得目标节点的项目推荐 列表。 进一步的,在训练所述Context-NE网络和图卷积网络时引入Mask机制,具体包括 如下内容: 根据网络大小随机mask网络中不同比例的节点和\或项目,对被mask节点和\或项 目采取以下三种方式中的一种进行处理: 随机采样与被mask节点和\或项目关系密切的邻居节点和\或项目的特征作为被 mask节点和\或项目的特征; 随机采样非邻居节点和\或项目的特征表示被mask节点和\或项目的特征; 对被mask节点和\或项目的特征不做处理。 进一步的,将新加入网络的节点和/或项目作为被mask节点和/或项目。 进一步的,步骤S2所述经过卷积层和池化层处理得到节点向量 和项目向量 的具体步骤如下: 步骤S21.将所述序列Su和所述序列Si输入拥有M个卷积核的卷积网络进行局部特 征提取,分别得到向量 和向量 其表达式分别为: 其中,Km表示第m个卷积核,bm表示偏置参数; 步骤S22.将所述向量 和所述向量 经过池化层处理后,得到节点向量 和项 6 CN 111582443 A 说 明 书 3/14 页 目向量 其中,i表示节点数据集U中第i个节点,ij表示项目数据集I中与第i个节点相关 的项目j。 进一步的,所述步骤S3.将所述节点向量 和所述项目向量 融合后得到第i个 节点在项目数据集I中的嵌入向量 的具体方法为: 其中, 表示节点数据集U中第i个节点的节点向量, 表示项目数据集I中与第i 个节点相关的项目j的项目向量,Wij为权重参数,bij为偏置参数; rij表示第i个节点对项目j的偏好程度,其表达式为: 其中,checkj表示第i个节点与项目j的交互次数,checki表示第i个节点与所有项 目的总交互次数。 进一步的,步骤S4中所述计算与第i个节点u关系密切的L阶邻居节点v的第k头注 意力系数 的具体方法为: 其中,N(u)表示与第i个节点u关系密切的所有邻居节点的集合; 表示与第i个 节点u关系密切的L阶邻居节点v对节点u的影响程度,其表达式为: 其中,γ表示输入梯度为0.2的LeakyReLu非线性函数;β是神经网络层的权重参 数;bk为k头注意力的偏置参数;Wk为节点u与邻居节点v共有的权重参数。 进一步的,步骤S4中所述根据邻居节点v的嵌入向量 计算节点u的k头注意力输 出 的具体方法为: 其中,W是权重参数。 进一步的,步骤S5中所述将所述 通过聚合注意力层进行聚合,输出第i个节点u 的聚合注意力向量 的具体方法为: 其中,Wh是聚合注意力层的权重参数; αh表示聚合注意力层的注意力系数,其表达式为: 7 CN 111582443 A 说 明 书 4/14 页 其中, 表示第i个节点u在进行聚合时第k头注意力输出 对节点u的影响程度, 其表达式为: 其中,bh为聚合注意力层的偏置参数; 进一步的,步骤S6中所述将第i个节点u的嵌入向量 与聚合注意力向量 进行拼 接并线性化,得到第i个节点u的推荐向量 的具体方法为: 其中,W是权重参数,b为偏置参数。 进一步的,当与第i个节点u关系密切的邻居节点数量过多时,采用以下方式处理 邻居节点集合N(u): 若邻居节点的总数大于预设值T,则计算第i个节点u与所有邻居节点的相似性,根 据所述相似性对所有邻居节点进行排序,选择相似度排序前T的邻居节点组成节点u的邻居 节点集合N(u);否则将所有邻居节点组成集合N(u)。 本发明与现有的技术相比,其有益的特点是: 1、将社交网络分为了社交域和项目域,考虑了社交网络的异构性,用学习到的节 点嵌入做推荐能更接近节点的偏好。 2、利用Context-NE网络和图卷积网络充分融合了社交域和项目域的特征信息,能 够充分提取两者交叉域中的节点特征,解决了由于异构网络中节点和项目的交互行为不 同,得到的节点和项目的表达不丰富的问题。 3、利用层次注意力机制聚合了与节点关系密切的邻居节点的特征信息,可以为节 点推荐更接近节点偏好的项目。 4、在网络训练中加入Mask机制,可以增加网络的泛化能力;可将新加入网络的节 点和\或项目作为Mask节点,缓解冷启动问题,并提高网络的灵活性。 附图说明 图1是一个实施例中一种基于Mask机制和层次注意力机制的推荐方法的流程图; 图2是一个实施例中社交域和项目域的结构示意图; 图3是一个实施例在Cora数据集上的不同mask比例的结果对比图; 图4是一个实施例在Citesseer数据集上的不同mask比例的结果对比图; 图5是一个实施例在Pumped数据集上的不同mask比例的结果对比图; 图6是一个实施例在不同邻居数量和聚合深度的HR性能对比图; 图7是一个实施例在不同邻居数量和聚合深度的NDCG性能对比图; 图8是一个实施例在输出维度为64时减少各项机制的HR和NDCG性能对比图; 8 CN 111582443 A 说 明 书 5/14 页 图9是一个实施例在N值为10时减少各项机制的HR和NDCG性能对比图。 图10是一个实施例中Context-NE网络的结构示意图; 图11是一个实施例中图卷积网络的结构示意图。











