
技术摘要:
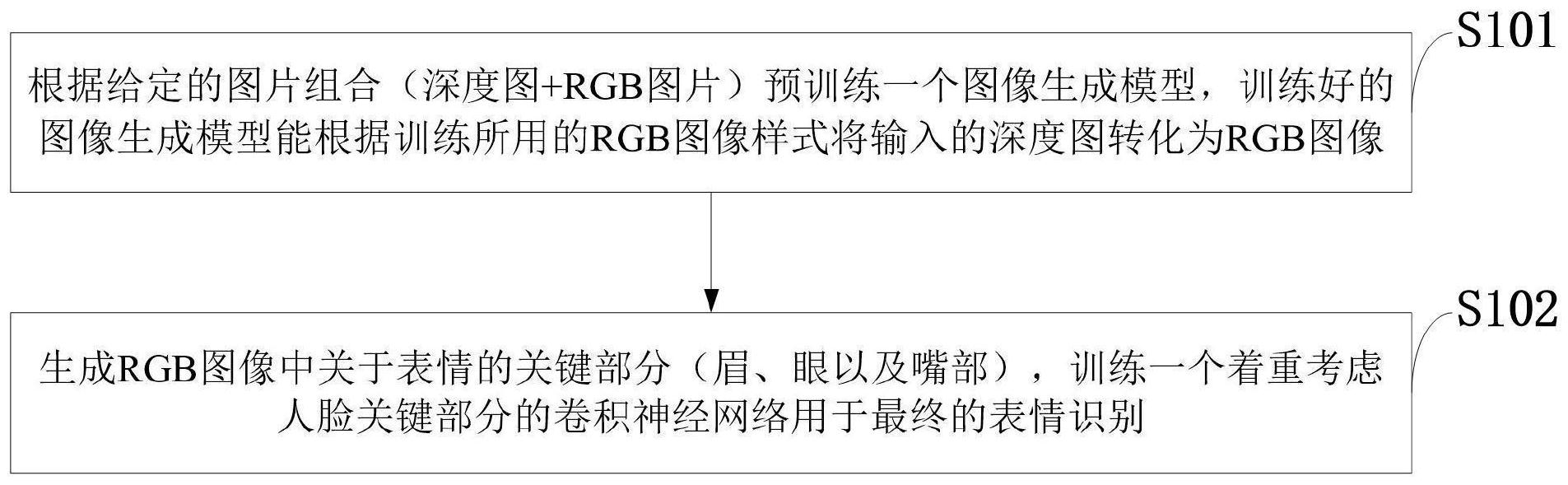
本发明属于计算机视觉技术领域,公开了一种人脸表情识别方法、系统、存储介质、计算机程序、终端,根据给定的深度图和RGB图片组合预训练一个图像生成模型,训练好的图像生成模型能根据训练所用的RGB图像样式将输入的深度图转化为RGB图像;生成RGB图像中表情的眉、眼以 全部
背景技术:
目前,二维RGB彩色图像的表情识别研究取得了巨大进展。通过将实验室采集的 RGB表情图像放入卷积神经网络、深度挖掘并提取图中表情的特征、训练网络学会表情的分 类是目前的主流研究方向。但值得一提的是,用这样的方法进行表情分类仍有许多不足之 处。二维RGB表情图片是一种彩色图片,用这样的图片进行表情分类容易受到光线、角度以 及肤色等与表情无关的因素影响,神经网络对于相同表情相同特征的提取很可能因为这些 因素的不同而不同,但这些因素实际上与一个人的表情是无关的;这类方法引入了许多与 表情无关的信息,在很大程度上影响了表情识别的准确率与效率,尤其是面对不同环境下 采集的图片时,问题则更为严重。 随着高分辨率三维图像设备的发展,用扫描得到的三维人脸数据进行表情分类是 一个新的解决思路。其中深度图是描述三维数据的一种常用载体,通过扫描出的三维坐标 映射得到灰度图。深度图排除了拍照角度、光线、肤色等与表情无关的因素,只反映三维信 息。用这类数据训练网络将使网络更专注于与表情有关的几何信息。但在表情识别领域,在 光照等其他因素可控的条件下,基于二维RGB彩色图像的表情识别准确率高于基于深度图 的表情识别办法,因为彩色图片中包含着许多与表情有关的纹理信息,是不可忽略的信息。 综上所述,在当下,基于二维RGB彩色图像的表情识别方法很难做到针对不同场景 下的通用表情识别方法,其原因如前所述,在面对不同环境下采集的图片时,识别的准确率 受到了严重的影响。而在使用扫描得到的三维人脸数据时,由于纹理信息的缺失,其表情的 识别率仍有待提高;这是我们希望设计方案解决的。 通过上述分析,现有技术存在的问题及缺陷为:如何设计方案,既保留深度图在跨 场景下的不受影响的几何信息优势,又能结合RGB图像的表情纹理信息,并实现较高的表情 识别准确率。 解决以上问题及缺陷的难度为: 1.如何在只有深度图像输入的情况下,生成单一场景下的RGB图像。 2.针对生成的RGB图像,如何尽可能地提高表情识别的准确率。 解决以上问题及缺陷的意义为:为提高跨场景下的表情识别准确度提供了一种解 决方案;只要求输入单张深度图像,即可自动生成相应的RGB表情图像并识别,不再像现有 技术,为了保证一个高的识别率,对场景采集要求极高,扩大表情识别方案的适用范围,提 高方案的可推广性。
技术实现要素:
针对现有技术存在的问题,本发明提供了一种人脸表情识别方法、系统、存储介 4 CN 111582067 A 说 明 书 2/6 页 质、计算机程序、终端。 本发明是这样实现的,一种人脸表情识别方法,所述人脸表情识别方法包括: 第一步,根据给定的深度图和RGB图片组合预训练一个图像生成模型,训练好的图 像生成模型能根据训练所用的RGB图像样式将输入的深度图转化为RGB图像。将不同场景下 采集的图片转化为统一的预训练场景,从而减少场景对表情识别带来的干扰信息;由于相 机直接采集的二维RGB表情图像,在不同场景下表现极为不同。而深度图是来源于三维人脸 数据,三维人脸数据并不受场景影响,因此深度图是稳定并且统一的形式。再通过预训练的 生成模型,根据深度图生成RGB图,实现不同场景数据统一成训练场景数据。具体步骤如下: 首先,选择pix2pix网络作为所述人脸表情识别方法的预训练图像生成模型, pix2pix网络被用于训练根据输入的深度图生成对应的RGB图像。 其次,用公开数据库Bosphorus中的图片作为预训练模型的数据来源;训练后的模 型即能根据深度图生成与Bosphorus数据库场景一致的RGB图。 第二步,生成RGB图像中表情的眉、眼以及嘴部,训练着重考虑眉、眼以及嘴部的卷 积神经网络,卷积神经网络实现表情识别。旨在加强人脸中与表情密切相关的位置的信息, 在训练时更多地关注这些位置,有助于进一步提高表情的识别准确率。具体步骤如下: 首先,所述人脸表情识别方法通过眉、眼以及嘴部的坐标确定在图中的位置,剪切 出来,经过加强,再放入神经网络训练。 其次,所述神经网络通过步长为2、卷积核大小为7、通道数为64的卷积层、BN层、 relu层、池化层、两个残差块加强学习关键部分的特征信息,得到描述眉、眼以及嘴部的的4 个特征图。 进一步,将所述图像生成模型生成的RGB图,整个放入残差学习网络ResNet-18训 练,学习整张脸关于表情的特征信息;在通过ResNet-18的第一层后,图像的通道数刚好是 64,矩阵大小是64×64,特征图为A;将得到的关于各关键部分的特征图Bi对应地叠加A上, 实现在网络训练时加强眉、眼以及嘴部信息的学习。 本发明的另一目的在于提供一种接收用户输入程序存储介质,所存储的计算机程 序使电子设备执行权利要求任意一项所述包括下列步骤: 第一步,根据给定的深度图和RGB图片组合预训练一个图像生成模型,训练好的图 像生成模型能根据训练所用的RGB图像样式将输入的深度图转化为RGB图像; 第二步,生成RGB图像中表情的眉、眼以及嘴部,训练着重考虑眉、眼以及嘴部的卷 积神经网络,卷积神经网络实现表情识别。 本发明的另一目的在于提供一种存储在计算机可读介质上的计算机程序产品,包 括计算机可读程序,供于电子装置上执行时,提供用户输入接口以实施所述的人脸表情识 别方法。 本发明的另一目的在于提供一种实施所述的人脸表情识别方法的人脸表情识别 系统,所述人脸表情识别系统包括: 图像生成模型与训练模块,用于根据给定的深度图和RGB图片预训练一个图像生 成模型; RGB图像转化模块,用于将训练好的图像生成模型能根据训练所用的RGB图像样式 将输入的深度图转化为RGB图像; 5 CN 111582067 A 说 明 书 3/6 页 表情关键部分关注模块,用于重点关注所生成RGB图像中关于表情的关键部分; 表情识别模块,用于训练一个着重考虑人脸关键部分的卷积神经网络用于表情识 别。 本发明的另一目的在于提供一种终端,所述终端搭载所述的人脸表情识别系统。 结合上述的所有技术方案,本发明所具备的优点及积极效果为:图5(b)展示了 ResNet-18网络中加上了关键部分的图像,与加之前的图5(a)相比,眼、眉、嘴部都得到了更 多的强调(特征信息得到加强)。与对Bosphorus数据库进行的其他表情识别研究对比来看, 本发明也实现了更高的识别准确率。本发明统一了用于表情识别训练的RGB图像形式,能对 跨情景采集的人脸图片(跨数据库)进行表情识别,取得较好的效果,如图6所示。如图6所 示,(a)是预训练图像生成模型在Bosporus数据库中实现的效果,第一列是输入的深度图, 第二列为模型生成的RGB图,第三列为数据库中真实的RGB图,可以看出图像生成模型的效 果比较好,尽管和真实图片存在些许不同,但最重要的表情信息都得以很好地保留;(b)是 图像生成模型在BU-3DFE数据库上实现的效果,第二列是模型生成的RGB图,第三列是数据 库中真实的RGB图,可以看出,这一数据库虽然也是针对人脸作表情的采集,但采集环境有 所不同,体现在RGB图上的差异很大,但通过图像生成模型,生成了和Bosphorus数据库类似 的RGB图,就像是在同样的环境中采集的一样,不仅关于表情的重要信息得到保留,用于表 情识别的RGB图形式也得到了统一;表情识别的准确率也更高,表2的数据很好地验证了其 效果。其他针对BU-3DFE数据库的表情识别研究基于多个通道进行,如表2所示,在仅用深度 图一个通道进行识别时,本发明取得的效果是更好的;甚至相比于其他研究中表现最好的 一个通道,本发明也是准确率更高的。 附图说明 图1是本发明实施例提供的人脸表情识别方法流程图。 图2是本发明实施例提供的人脸表情识别系统的结构示意图; 图中:1、图像生成模型与训练模块;2、RGB图像转化模块;3、表情关键部分关注模 块;4、表情识别模块。 图3是本发明实施例提供的人脸表情识别方法实现流程图。 图4是本发明实施例提供的学习整张脸关于表情的特征信息示意图。 图5是本发明实施例提供的关键部分的图像对比示意图; 图中:(a)加之前的关键部分的图像;(b)展示了ResNet-18网络中加上了关键部分 的图像。 图6是本发明实施例提供的统一了用于表情识别训练的RGB图像形式,能对跨情景 采集的人脸图片(跨数据库)进行表情识别示意图; 图中:(a)是预训练图像生成模型在Bosporus数据库中实现的效果;(b)图像生成 模型在BU-3DFE数据库上实现的效果。











