
技术摘要:
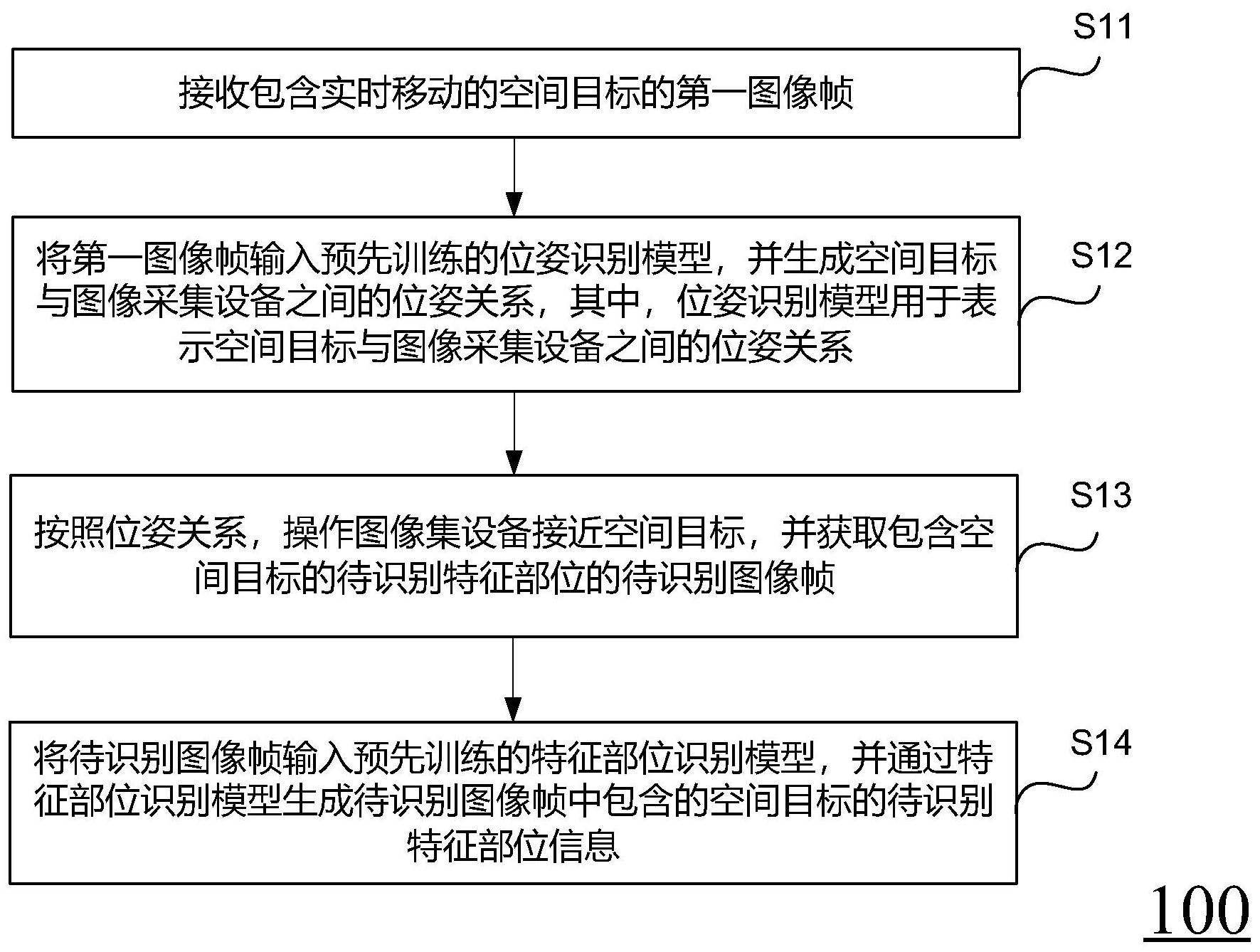
本申请公开了一种识别空间目标的方法、装置和存储介质,具体为接收包含实时移动的空间目标的第一图像帧,将第一图像帧输入预先训练的位姿识别模型,并生成空间目标与图像采集设备之间的位姿关系,按照位姿关系,操作图像采集设备接近空间目标,并获取包含空间目标的待 全部
背景技术:
随着空间技术的不断发展,空间机器人成为研究热点。空间机器人通常是指装有 机械臂的服务卫星。机械臂由于其自身具有的灵巧操作性,可以提高服务卫星完成各类复 杂空间任务的能力,例如消旋、抓捕、对接、精细操作等。空间机器人在各类任务中的规划与 控制因此成为研究的热点问题。空间机器人具有复杂的动力学特性,在自由漂浮时属于非 完整系统,其规划与控制问题相较于地面机器人更加复杂。 伴随着人工智能在近年来取得的进展,人工智能在空间机器人任务中的应用成为 新的研究热点。人工智能能够在一定程度上提高空间机器人的自主性,是空间机器人从人 在回路的规划与控制如遥操作过渡到无人参与的自主规划与控制的重要一环,为空间智能 的研究提供了理论基础。深度学习的出现进一步提高了强化学习的处理能力,即深度强化 学习,深度强化学习在强化学习的优化框架下,采用深度学习来提取与环境交互得到的经 验即样本的特征,大大提高了强化学习的表征能力,使得强化学习在机器人的规划与控制 问题中有了更好的应用前景。然而,强化学习在机器人规划与控制领域,面临着计算复杂度 高、样本利用率低、样本获取难度高、奖励函数稀疏或不易设计、模型估计存在误差、实时性 和准确率都较低等问题,且对可以适用的空间机器人有类型的要求,不具有普适性。
技术实现要素:
本申请实施例提供了一种识别空间目标的的方法,克服了传统感知方法在空间复 杂环境中识别空间目标存在的普适性差、实时性弱和准确率低的问题,提升了实时识别空 间目标的普适性、实时性和准确性。 该方法包括: 接收包含实时移动的空间目标的第一图像帧; 将所述第一图像帧输入预先训练的位姿识别模型,并生成所述空间目标与图像采 集设备之间的位姿关系,其中,所述位姿识别模型用于表示所述空间目标与图像采集设备 之间的位姿关系; 按照所述位姿关系,操作所述图像集设备接近所述空间目标,并获取包含所述空 间目标的待识别特征部位的待识别图像帧; 将所述待识别图像帧输入预先训练的特征部位识别模型,并通过所述特征部位识 别模型生成所述待识别图像帧中包含的所述空间目标的待识别特征部位信息。 可选地,所述方法进一步包括所述位姿识别模型的训练步骤: 获取包含实时移动的所述空间目标的第一样本图像帧,以及,将在采集所述第一 样本图像帧时所述空间目标与图像采集设备之间的位姿关系作为第一标签信息; 4 CN 111598951 A 说 明 书 2/10 页 将所述第一样本图像帧和所述第一标签信息输入待训练的所述位姿识别模型,并 基于训练时生成的第一损失函数对所述位姿识别模型进行优化,其中,所述位姿识别模型 为softmax层为仿射回归层的回归网络模型。 可选地,所述方法进一步包括所述特征部位识别模型的训练步骤: 获取包含所述空间目标的已识别部位的第二样本图像帧,以及,将所述第二样本 图像帧中包含的所述已识别部位对应的二制掩膜图像、所述已识别部位对应的类别信息和 所述已识别部位所在检测框的坐标信息作为第二标签信息; 将所述第二样本图像帧和所述第二标签信息输入待训练的所述特征部位识别模 型,并基于训练时生成的第二损失函数对所述特征部位识别模型进行优化。 可选地,对在虚拟环境内模拟生成的空间目标模型进行图像帧的采集,并对所述 空间目标模型上的所述已识别部位进行着色,分别生成不同角度下的所述已识别部位对应 的着色模型投射的第一二维图像帧和所述已识别部位未进行着色前的原有模型投射的第 二二维图像帧; 基于所述第一二维图像帧,生成所述已识别部位对应的二制掩膜图像、所述已识 别部位对应的类别信息和所述已识别部位所在检测框的坐标信息; 将所述已识别部位对应的二制掩膜图像、所述已识别部位对应的类别信息和所述 已识别部位所在检测框的坐标信息作为所述第二标签信息,以及将第二二维图像帧作为所 述第二样本图像帧。 可选地,基于所述特征部位识别模型中softmax层包括的分类层、回归层和二制掩 膜图像提取层,并基于所述分类层生成的分类损失函数、所述回归层生成的回归损失函数 和二制掩膜图像提取层生成的掩膜损失函数生成所述第二损失函数; 根据所述第二损失函数对所述特征部位识别模型进行优化。 可选地,通过所述特征部位识别模型中的卷积神经网络提取所述待识别图像帧中 的图像特征,生成所述待识别图像帧对应的图像特征图; 通过所述特征部位识别模型中的区域生成网络在所述图像特征图中提取待识别 特征部位所在检测框的坐标信息; 通过所述特征部位识别模型中的全连接层网络对所述待识别特征部位所在检测 框的坐标信息进行修正,以及确定所述待识别特征部位对应的所述类别信息; 通过所述特征部位识别模型中的全卷积层网络对所述待识别特征部位确定所述 待识别特征部位对应的所述二制掩膜图像; 将所述待识别特征部位所在检测框的坐标信息、所述待识别特征部位对应的所述 类别信息和所述待识别特征部位对应的所述二制掩膜图像确定为所述待识别特征部位信 息。 在本发明的另一个实施例中,提供了一种识别空间目标的装置,该装置包括: 接收模块,用于接收包含实时移动的空间目标的第一图像帧; 第一生成模块,用于将所述第一图像帧输入预先训练的位姿识别模型,并生成所 述空间目标与图像采集设备之间的位姿关系,其中,所述位姿识别模型用于表示所述空间 目标与图像采集设备之间的位姿关系; 获取模块,用于按照所述位姿关系,操作所述图像集设备接近所述空间目标,并获 5 CN 111598951 A 说 明 书 3/10 页 取包含所述空间目标的待识别特征部位的待识别图像帧; 第二生成模块,用于将所述待识别图像帧输入预先训练的特征部位识别模型,并 通过所述特征部位识别模型生成所述待识别图像帧中包含的所述空间目标的待识别特征 部位信息。 可选地,所述第一训练模块包括: 获取单元,用于获取包含实时移动的所述,空间目标的第一样本图像帧,以及,将 在采集所述第一样本图像帧时所述空间目标与图像采集设备之间的位姿关系作为第一标 签信息; 优化单元,用于将所述第一样本图像帧和所述第一标签信息输入待训练的所述位 姿识别模型,并基于训练时生成的第一损失函数对所述位姿识别模型进行优化,其中,所述 位姿识别模型为softmax层为仿射回归层的回归网络模型。 在本发明的另一个实施例中,提供了一种非瞬时计算机可读存储介质,所述非瞬 时计算机可读存储介质存储指令,所述指令在由处理器执行时使得所述处理器执行上述一 种识别空间目标的方法中的各个步骤。 在本发明的另一个实施例中,提供了一种终端设备,包括处理器,所述处理器用于 执行上述一种识别空间目标的方法中的各个步骤。 基于上述实施例,首先接收包含实时移动的空间目标的第一图像帧,其次,将第一 图像帧输入预先训练的位姿识别模型,并生成空间目标与图像采集设备之间的位姿关系, 其中,位姿识别模型用于表示空间目标与图像采集设备之间的位姿关系,进一步地,按照位 姿关系,操作图像集设备接近空间目标,并获取包含空间目标的待识别特征部位的待识别 图像帧,最后,将待识别图像帧输入预先训练的特征部位识别模型,并通过特征部位识别模 型生成待识别图像帧中包含的空间目标的待识别特征部位信息。本申请实施例通过位姿识 别模型和特征部位识别模型运用在空间目标的位姿识别和特征部位检测中,相比于传统感 知方法,针对不同的目标和场景有更好的普适性,其准确性和实时性也满足空间目标感知 要求。 附图说明 为了更清楚地说明本申请实施例的技术方案,下面将对实施例中所需要使用的附 图作简单地介绍,应当理解,以下附图仅示出了本申请的某些实施例,因此不应被看作是对 范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这 些附图获得其他相关的附图。 图1示出了本申请实施例100所提供的一种识别空间目标的方法的流程示意图; 图2示出了本申请实施例200提供的一种识别空间目标的方法的具体流程的示意 图; 图3示出了本申请实施例300提供的位姿识别模型的训练步骤的示意图; 图4a示出了本申请实施例提供的空间目标模型的示意图; 图4b示出了本申请实施例提供的各个视角下所对应的空间目标的图像帧的示意 图; 图4c示出了为本申请实施例提供的第二样本图像帧和第二标签信息的示意图; 6 CN 111598951 A 说 明 书 4/10 页 图4d示出了为本申请实施例提供的特征部位识别模型的模型示意图 图5示出了本申请实施例500还提供一种识别空间目标的装置的示意图; 图6示出了本申请实施例600所提供的一种终端设备的示意图。











