
技术摘要:
本申请公开了一种医学术语的标准化方法、装置、计算机设备和存储介质,所述方法包括:获取医学文本数据,并对医学文本数据进行数据清洗,得到初始文本;采用分词引擎对的初始文本进行分词处理,得到初始文本对应的分词单元;通过医学知识的深度学习实体识别的方式,识 全部
背景技术:
医学术语是医学领域里的专业用语,用来指称医学领域里的各种事物、现象、特 性、关系和过程等(如疾病、药物、手术操作、检查检验等)。这些术语是临床信息系统表达医 学信息的必要成分。 医学文本数据在没有经过数据的标准化处理时,医学文本数据含有诸多不标准的 数据,如不标准的医学别名,同义词等等,做不到统一的标准,这样医学术语数据对很难被 后续的医学应用,造成数据的浪费。数据的标准化处理即:将不标准的数据如别名、同义词 等统一对应到一份标准名称,便于数据的后续应用。 现有的医学术语标准化,通常将医学文本数据上传计算机中,通过搜索出医学特 征词,再对应出每个医学特征词的医学术语标准表述,但是这种医学术语标准化方式,容易 出现遗落搜索医学特征词的同义词、近义词等词汇,造成医学术语标准化的准确率波动较 大,进而导致医学术语标准化的数据的可用性降低。如何提高医学术语标准化的准确率成 为了一个亟需处理的问题。
技术实现要素:
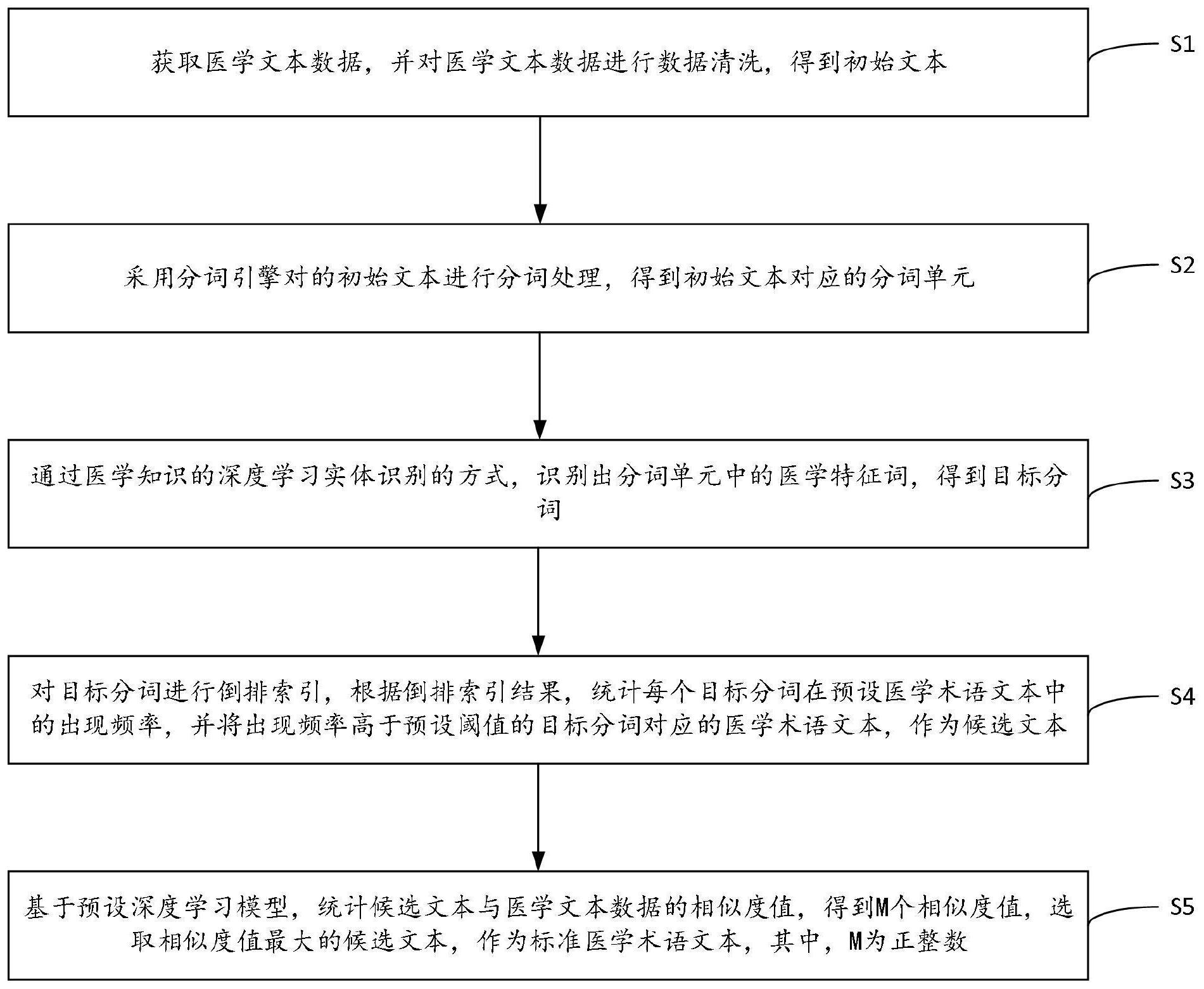
本申请实施例的目的在于提出一种医学术语的标准化方法,解决现有技术医学术 语的标准准确率准确性低的问题。 为了解决上述技术问题,本申请实施例提供一种医学术语的标准化方法,包括: 获取医学文本数据,并对所述医学文本数据进行数据清洗,得到初始文本; 采用分词引擎对所述的初始文本进行分词处理,得到所述初始文本对应的分词单 元; 通过医学知识的深度学习实体识别的方式,识别出所述分词单元中的医学特征 词,得到目标分词; 对所述目标分词进行倒排索引,根据所述倒排索引结果,统计每个所述目标分词 在预设医学术语文本中的出现频率,并将所述出现频率高于预设阈值的所述目标分词对应 的医学术语文本,作为候选文本; 基于预设深度学习模型,统计所述候选文本与所述医学文本数据的相似度值,得 到M个相似度值,选取相似度值最大的所述候选文本,作为标准医学术语文本,其中,M为正 整数。 进一步的,所述通过医学知识的深度学习实体识别的方式,识别出所述分词单元 中的医学特征词,得到目标分词包括: 获取预置的医学术语库; 4 CN 111581976 A 说 明 书 2/12 页 针对每个所述分词单元,通过遍历的方式,将所述分词单元分别与所述预置的医 学术语库中的每个词汇进行命名实体识别,得到实体识别结果; 若所述实体识别结果为存在相同命名实体,则获取所述识别结果对应的分词单元 和医学特征词,并使用所述医学特征词替代所述分词单元,并将所述医学特征词作为目标 分词。 进一步的,所述通过医学知识的深度学习实体识别的方式,识别出所述分词单元 中的医学特征词,得到目标分词还包括: 采用N-gram模型,对所述分词单元进行词性标注,并赋予所述分词单元标签,得到 词性单元; 删除词性为虚词的词性单元,得到词性为实词的词性单元,将所述词性为实词的 词性单元作为目标分词。 进一步的,所述采用N-gram模型,对所述分词单元进行词性标注,并赋予所述分词 单元标签,得到词性单元包括: 读取所述预置的医学术语库的标签序列; 采用所述N-gram模型,对所述分词单元进行词性标注,得到词性标注单元; 针对所述词性为实词的所述词性标注单元,遍历所述预置的医学术语库,查询与 所述词性为实词的所述词性标注单元所在的标签,得到目标标签; 赋予所述词性为实词的所述词性标注单元所述的目标标签,得到所述词性单元。 进一步的,所述对所述目标分词进行倒排索引,根据所述倒排索引结果,统计每个 所述目标分词在预设医学术语文本中的出现频率,并将所述出现频率高于预设阈值的所述 目标分词对应的医学术语文本,作为候选文本包括: 基于所述目标分词,将相同标签的所述目标分词组合在一起,建立倒排索引表; 根据所述倒排索引表,统计每个所述目标分词在预设医学术语文本中的出现频 率,并将所述出现频率高于预设阈值的所述目标分词对应的医学术语文本,作为基础文本; 判断所述基础文本是否存在相同文本,若存在,则删除多余相同所述基础文本,保 留其中一份所述基础文本; 将保留的所述基础文本作为候选文本。 进一步的,所述基于预设深度学习模型,统计所述候选文本与所述医学文本数据 的相似度值,得到M个相似度值,选取相似度值最大的所述候选文本,作为标准医学术语文 本,其中,M为正整数包括: 获取预设深度学习模型; 通过特征工程的方式,统计所述候选文本与所述医学文本数据的相似度值,得到M 个相似度值,其中,M为正整数; 按相似度值从大到小的顺序排列,选取相似度值最大的所述候选文本,作为标准 医学术语文本; 输出所述标准医学术语文本。 为解决上述技术问题,本发明采用的一个技术方案是:提供一种医学术语的标准 化装置,包括: 初始文本获取模块,用于获取医学文本数据,并对所述医学文本数据进行数据清 5 CN 111581976 A 说 明 书 3/12 页 洗,得到初始文本; 分词单元获取模块,用于采用分词引擎对所述的初始文本进行分词处理,得到所 述初始文本对应的分词单元; 目标分词获取模块,用于通过医学知识的深度学习实体识别的方式,识别出所述 分词单元中的医学特征词,得到目标分词; 候选文本获取模块,用于对所述目标分词进行倒排索引,根据所述倒排索引结果, 统计每个所述目标分词在预设医学术语文本中的出现频率,并将所述出现频率高于预设阈 值的所述目标分词对应的医学术语文本,作为候选文本; 标准医学术语文本模块,用于基于预设深度学习模型,统计所述候选文本与所述 医学文本数据的相似度值,得到M个相似度值,选取相似度值最大的所述候选文本,作为标 准医学术语文本,其中,M为正整数。 进一步的,所述目标分词获取模块包括: 医学术语库获取单元,用于获取预置的医学术语库; 实体识别结果获取单元,用于针对每个所述分词单元,通过遍历的方式,将所述分 词单元分别与所述预置的医学术语库中的每个词汇进行命名实体识别,得到实体识别结 果; 目标分词确认单元,用于若所述实体识别结果为存在相同命名实体,则获取所述 识别结果对应的分词单元和医学特征词,并使用所述医学特征词替代所述分词单元,并将 所述医学特征词作为目标分词。 为解决上述技术问题,本发明采用的一个技术方案是:提供一种计算机设备,包 括,一个或多个处理器;存储器,用于存储一个或多个程序,使得一个或多个处理器实现上 述任意一项所述的医学术语的标准化方案。 为解决上述技术问题,本发明采用的一个技术方案是:一种计算机可读存储介质, 所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现上述 任意一项所述的医学术语的标准化方案。 以上方案中的一种医学术语的标准化方法,通过将医学文本数据进行数据清理, 并进行分词处理,得到分词单元,有利于将医学文本数据进行初步的整理,清除杂糅的文本 数据,然后通过识别分词单元中的医学特征词,作为目标分词,实现识别医学相关的词语, 为后续获取候选文本提供基础,再通过倒排索引的方式,获取目标分词对应的医学术语文 本,实现得到一系列和医学文本数据相关的候选文本,使用倒排索引的方式,有利于获取一 系列医学术语的标准化准确度不同的候选文本,最后通过对候选文本的相似度计算,得到 相似度最大的对应候选文本,作为标准医学术语文本。通过对医学文本数据进行数据清洗, 识别医学特征词,再根据倒排索引的方式,获得候选文本,最后选出相似度最大的候选文 本,作为最终的标准医学术语文本,通过这种方式的层层识别和筛选,有利于有效的提高医 学术语标准化的准确率,进而提高医学术语文本的数据的可用性。 附图说明 为了更清楚地说明本申请中的方案,下面将对本申请实施例描述中所需要使用的 附图作一个简单介绍,显而易见地,下面描述中的附图是本申请的一些实施例,对于本领域 6 CN 111581976 A 说 明 书 4/12 页 普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。 图1是本申请实施例提供的医学术语的标准化方法的应用环境示意图; 图2根据本申请实施例提供的医学术语的标准化方法的一实现流程图; 图3是本申请实施例提供的医学术语的标准化方法中步骤S3的一实现流程图; 图4是本申请实施例提供的医学术语的标准化方法中步骤S3的另一实现流程图; 图5是本申请实施例提供的医学术语的标准化方法中步骤S34的一实现流程图; 图6是本申请实施例提供的医学术语的标准化方法中步骤S4的一实现流程图; 图7是本申请实施例提供的医学术语的标准化方法中步骤S5的一实现流程图; 图8是本申请实施例提供的医学术语的标准化装置示意图; 图9是本申请实施例提供的计算机设备的示意图。











